Machine learning optimized antibodies yield highly diverse and affinity-rich antibody libraries
Therapeutic antibodies are an important and rapidly growing class of drugs. However, the design and discovery of early-stage antibody therapies remain a time-consuming and costly endeavor. Here, we present a comprehensive Bayesian, language-model-based approach for designing large-scale and diverse high-affinity single-chain variable fragment (scFv) antibody libraries, followed by experimental validation. Compared to directed evolution methods, the best scFv generated by our approach showed a 28.7-fold improvement in binding affinity compared to the best scFv generated by directed evolution. Furthermore, in the most successful antibody library, 99% of the designed scFv showed improvements over the initial candidate scFv.
Due to the vast search space of antibody sequences, a thorough evaluation of the entire antibody space becomes impractical. Therefore, a smaller subset of antibodies is typically selected from synthetic production, animal immunization, or human donors to identify candidate antibodies. These selected antibody libraries only represent a small fraction of the overall search space, often resulting in weak binding or developmental issues of the candidate antibodies. Optimization of these candidates is needed to enhance their binding affinity and other developmental properties. Given the explosion in sequence space, an iterative approach is often adopted to optimize antibody-target binding, but this is time-consuming and requires substantial effort to validate non-functional antibodies. Further modifications may be required to improve other properties of the improved binders, but such modifications could negatively impact the previously optimized binding affinity, necessitating additional measurement and engineering cycles. Determining the final antibody typically takes around 12 months. If antibodies with strong binding and high diversity can be efficiently engineered in the early stages of development, it would reduce the impact of later-discovered unfavorable antibody properties, increase developmental potential, and shorten the timeline needed for early-stage drug development.
While computational methods can guide the search for biologically relevant antibodies, most novel methods require knowledge of the target structure or the antibody-epitope complex structure. Machine learning (ML) methods effectively represent biological data and rapidly explore the vast design space through computer simulations. Existing ML-based antibody optimization has shown to enhance binding characteristics when designing antibodies against specific targets. It can learn about antibody binding solely from sequence data, without requiring the target's structure. However, existing work hasn't allowed for the evaluation of designed antibody libraries before experimentation, a crucial feature that can accelerate the design cycle. In this work, we've developed a comprehensive machine-learning-driven framework for designing single-chain variable fragment (scFv) antibodies. It uniquely combines language models, Bayesian optimization, and high-throughput experiments (Figure 1).
1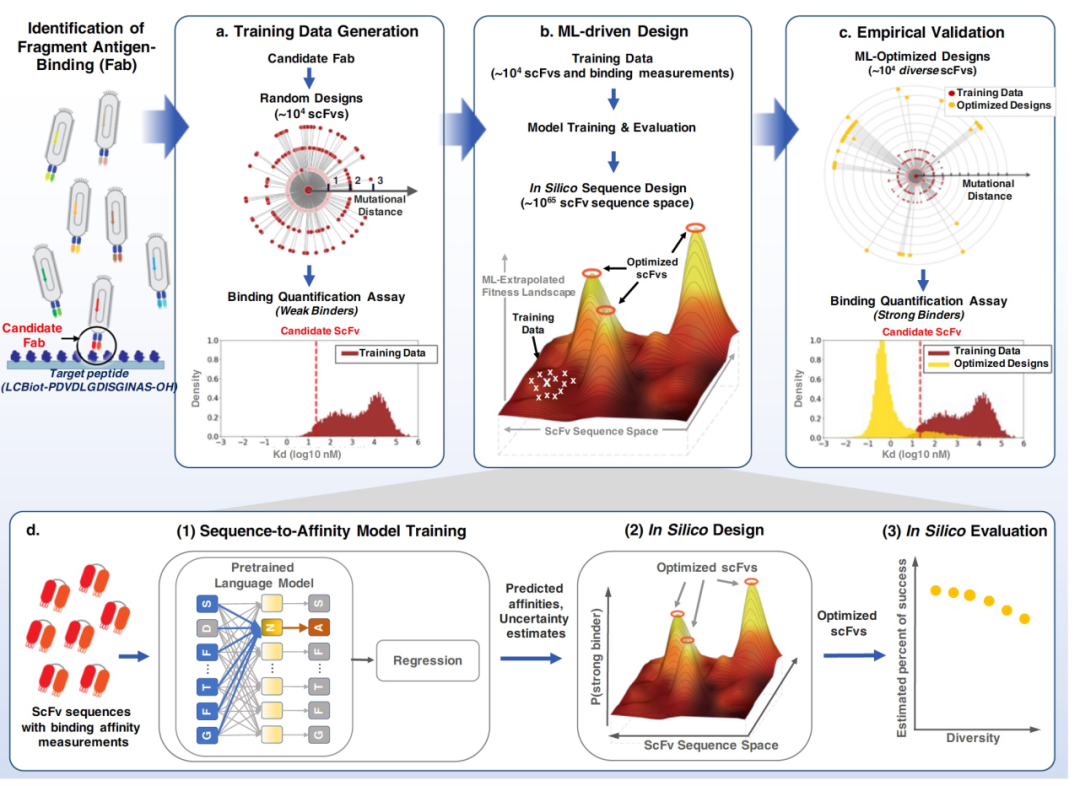
Development of a comprehensive target-specific scFv optimization process
We hypothesize that by integrating target-specific binding affinity with information from millions of natural protein sequences within a probabilistic machine learning framework, the model can rapidly design scFv molecules with significantly higher binding quality compared to conventional directed evolution methods. To design candidate scFv (variable fragments of antibodies) targeting specific molecules, we devised a five-step process that uniquely combines language models, Bayesian optimization, and high-throughput experimentation to generate high-affinity scFv libraries (see Figure 1): 1. Quantification of high-throughput binding between random mutagenized variants of candidate scFv and the target to create supervised training data (Figure 1a). 2. Unsupervised pre-training on a vast set of protein sequences to extract biologically relevant information and represent scFv sequences (Figure 1b, d). 3. Supervised fine-tuning of the pre-trained language model on training data, predicting binding affinity and quantifying uncertainty (Figure 1b, d). 4. Construction of a Bayesian scFv variant landscape based on the trained sequence-affinity model, followed by Bayesian optimization and computer simulations for scFv design validation (Figure 1b, d). 5. Experimental verification of top-scoring scFv sequences predicted to possess strong binding affinity through computer simulations (Figure 1c).
Supervised training data was generated using an improved yeast mating assay. The target peptide was a conserved sequence found in the HR2 region of the coronavirus spike protein, known to bind neutralizing antibodies. A phage display using a library containing naturally occurring human Fabs was employed to identify candidate scFv sequences with weaker binding to the target (Ab-14, Ab-91, and Ab-95). All heavy and light chain sequences were designed by introducing k = 1, 2, 3 random mutations in the CDRs of the three candidate scFvs. In this work, we aimed to optimize Ab-14, hence only measurement data for Ab-14 (26,453 heavy chains, 26,223 light chains) were used as supervised training data for sequence-affinity prediction. Binding affinity measurements were represented on a logarithmic scale, with smaller values indicating stronger binding.
Four BERT-masked language models were pre-trained, namely a protein language model, antibody heavy chain model, antibody light chain model, and a paired heavy-light chain model. The protein language model was trained on the Pfam dataset, while antibody-specific language models were trained on naturally occurring human antibodies from the Observed Antibody Space (OAS) database. To train the sequence-affinity model, two methods were explored for predicting affinity and quantifying uncertainty: ensemble methods and Gaussian processes. Both methods leveraged the knowledge learned from pre-trained language models, offering meaningful sequence-affinity models for designing high-affinity scFv libraries. Corresponding training data were used to train sequence-affinity models for Ab-14-H heavy chain variants and Ab-14-L light chain variants. Strong positive correlations were observed between predicted binding affinity on test data and experimentally measured binding affinity.
To generate high-affinity scFv libraries, a Bayesian adaptive variant landscape was constructed, mapping the entire scFv sequence to posterior probabilities, i.e., the estimated probability of the binding affinity being higher than that of the candidate scFv Ab-14. This is distinct from a direct sequence-to-affinity adaptive variant landscape. Sampling algorithms were crucial for diversity determination in optimizing posterior probabilities. Three strategies were used: hill climbing (HC), genetic algorithm (GA), and Gibbs sampling.
Sampling methods were applied to generate optimized heavy and light chain variant scFvs for Ab-14. A position-specific scoring matrix (PSSM) method, representing traditional directed evolution methods, was also used to generate a control sequence set. Sequences generated from each method were ranked based on posterior probabilities and a few top sequences were selected. This way, each chain yielded seven scFv libraries: three from ensemble method optimization adaptive functions (En-HC, En-GA, En-Gibbs), three from Gaussian process optimization adaptive functions (GP-HC, GP-GA, GP-Gibbs), and one PSSM library. For result validation, scFv mutants with an average of k = 2 random mutations were generated from the top 10 strongest binding entities of supervised training data. All sequences were synthesized and experimentally validated using the same high-throughput yeast display method employed during training data generation.
The experimentally measured binding distribution of training data was compared with the PSSM library and machine learning-designed sequences. The machine learning-designed sequences exhibited stronger binding compared to training data. Notably, over 25% of the ensemble method Ab-14-H variant designs had experimentally measured binding affinities stronger than the strongest binding entities in training data, while only 0.9% of PSSM method Ab-14-H variant designs exhibited stronger experimentally measured binding affinity than the strongest binding entities in training data.
Stronger than direct evolution
1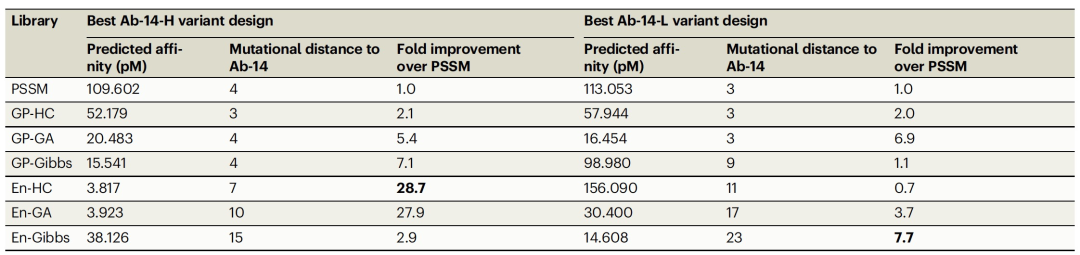
We conducted a quality assessment by comparing the binding strength and success rate of the best-designed scFvs from each machine learning-derived library with those from libraries generated using the PSSM method. In this experiment, success rate was defined as the percentage of scFvs with experimentally measured binding scores better than the initial candidate scFv Ab-14. We chose the PSSM libraries as the comparison group because they better reflect traditional optimization processes and often outperform random mutation libraries. Table 1 contains features of the best binding scFvs from each library. Compared to scFvs in the PSSM libraries, the best-designed scFvs in the machine learning-optimized libraries exhibit stronger binding affinities and generally contain more mutations. In heavy chain design, the strongest binding design in the En-Gen library has a 28.7-fold stronger binding affinity than the strongest scFv in the PSSM library. Similarly, in light chain design, the best design from the En-Gibbs library has a 7.7-fold stronger binding affinity compared to the best scFv in the PSSM library.
2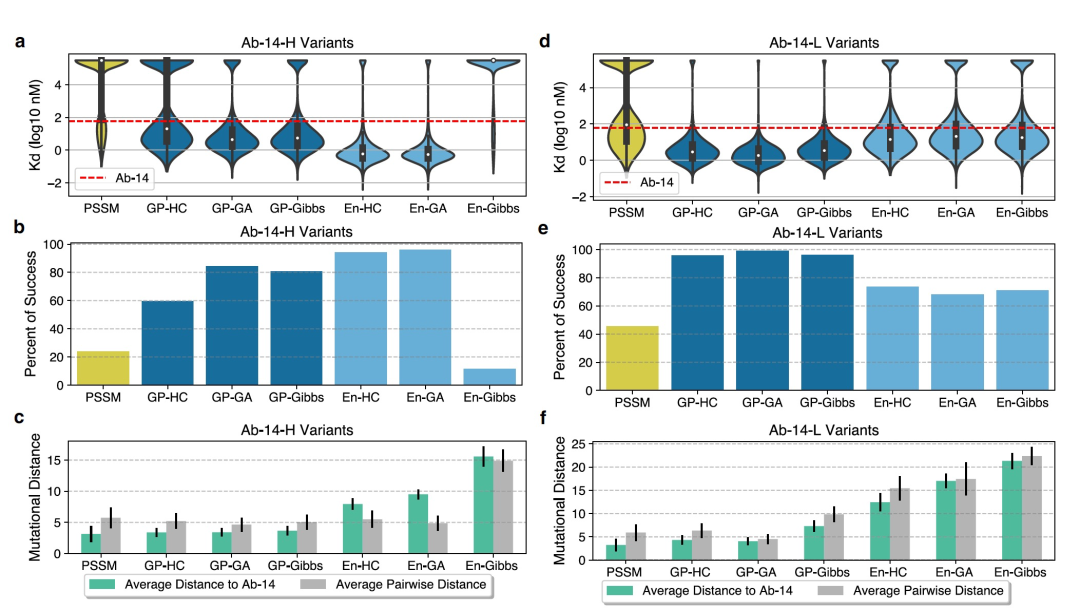
Figure 2 illustrates the performance and diversity of the design libraries. For Ab-14-H heavy chain design, except for sequences in the En-Gibbs library, all machine learning-optimized libraries outperform the PSSM library in terms of median binding affinity (Figure 2a) and exhibit a significantly higher success rate than the PSSM library by 23.8% (Figure 2b). Notably, the En-HC (94.3%) and En-GA (96%) libraries are particularly successful, surpassing all GP-generated Ab-14-H variant libraries (59.4–84.2%). In the case of Ab-14-L light chain design, all machine learning-optimized libraries outperform the PSSM library in terms of median binding affinity (Figure 2d) and success rate, with the PSSM library having a success rate of 45.6% (Figure 2e). The success rates based on GP-derived libraries (95.7–99%) are further superior to all ensemble-based libraries (67.9–73.5%).
We employed two mutation distance metrics to gauge the diversity of the libraries: dAb14avg (average distance from the initial Ab-14) and dpw (average pairwise distance). The former, dAb14avg, indicates the distance of the designs from the training data, while the latter, dpw, signifies diversity within the library. For Ab-14-H variant design, the dAb14avg for all machine learning-optimized libraries is higher than that of the PSSM library, where dAb14avg is 3.1. Ensemble-based libraries also exhibit significantly higher dAb14avg (7.9–15.6) compared to GP-based libraries (dAb14avg ranging from 3.4 to 3.7), suggesting these methods can extrapolate and design sequences far from the training data (Figure 2c). Particularly, sequences in the En-Gibbs library have an average distance of 15.6 from Ab-14-H and an average distance of 14.9 from each other (Figure 2c). However, this increase in mutation distance comes at the cost of reduced binding affinity, indicating a trade-off between the two.
For Ab-14-L variant design, the average distance of all machine learning-optimized libraries from Ab-14-L is significantly greater than that of the PSSM library, where PSSM's dAb14avg is 3.2, GP-based libraries range from 4.3 to 7.4, and ensemble-based libraries range from 12.4 to 21.3 (Figure 2f). Except for GP-GA (dpw = 4.5), the dpw values (ranging from 6.3 to 22.4) for all machine learning-optimized libraries are higher than that of the PSSM library (dpw = 5.9). Specifically, the En-Gibbs light chain library is composed of sequences with an average distance of 21.3 from Ab-14-L and an average distance of 22.4 from each other (Figure 2f).
Conclusion
In experiments directly comparing with traditional directed evolution strategies, our ensemble-based machine learning approach demonstrated significantly stronger binding affinity of designed scFvs, particularly in scenarios of high diversity, where the model accurately predicted the binding affinity of higher-order mutants. Importantly, following a design-build-test cycle, the model was able to generate a heavy chain scFv with a binding affinity 28.7 times stronger than the strongest scFv in the PSSM library (Table 1). The majority of machine learning-designed scFvs outperformed the candidate scFv Ab-14; compared to the PSSM library's success rate of less than 20%, over 90% of experimentally evaluated En-GA and En-HC heavy chain scFvs were successful (Figure 2). Furthermore, ensemble-based methods were able to explore a larger sequence space; the average mutation distance of the heavy chain ensemble library ranged from 7.9 to 15.6, while the mutation distance for the PSSM library was 3.17 (Figure 2). Traditional methods might eventually find binding affinities as strong as those found by our machine learning approach. However, this is not guaranteed and would require at least additional design-build-test cycles. Traditional methods would struggle to achieve the same level of success rate and diversity metrics as our approach.

Dr.Sunny
Medical Assistant