In recent years, machine learning techniques in the field of chemistry have made significant strides, enabling direct learning from molecular structures without the need for preprocessing into fixed-length vectors. However, the stereochemistry of molecules, a spatial structural characteristic, often remains unexplored within modern neural network architectures designed for learning structure-property relationships. Even when molecules exhibit identical graph connectivity, different stereochemical arrangements can lead to distinct physical and biological properties.
In this study, the authors tackle the challenge of incorporating molecular stereochemistry into graph neural networks. They develop two custom aggregation functions for message-passing neural networks (MPNNs) to learn the properties of molecules possessing tetrahedral chirality. Tetrahedral chirality is a common form of stereochemistry and is the focus of investigation due to its impact on property predictions.
Chemical machine learning advancements have allowed direct learning from molecular structures, bypassing the need for preprocessing into fixed vectors. However, the stereochemistry of molecules, a spatial structural characteristic, has been largely unexplored in the context of modern neural network architectures used for learning structure-property relationships. Even when molecules exhibit identical graph connectivity, different stereochemical arrangements can lead to distinct physical and biological properties.
In this study, the authors aim to address this limitation by developing two custom aggregation functions for message-passing neural networks (MPNNs) to effectively handle molecular stereochemistry. Specifically, they focus on molecules with tetrahedral chirality, a common form of stereochemistry that affects molecular properties.
In recent years, machine learning techniques have seen significant progress in the field of chemistry, allowing for direct learning from molecular structures without the need for preprocessing them into fixed-length vectors. These advances have shown improvements in various cases, including property prediction, synthesis prediction, and molecular optimization. However, the consideration of stereochemistry within the framework of deep learning, despite being an essential aspect of molecular representation, has remained largely unexplored. Stereoisomers with tetrahedral chirality are the subject of this investigation, primarily due to their prevalence in stereochemistry and their influence on property prediction.
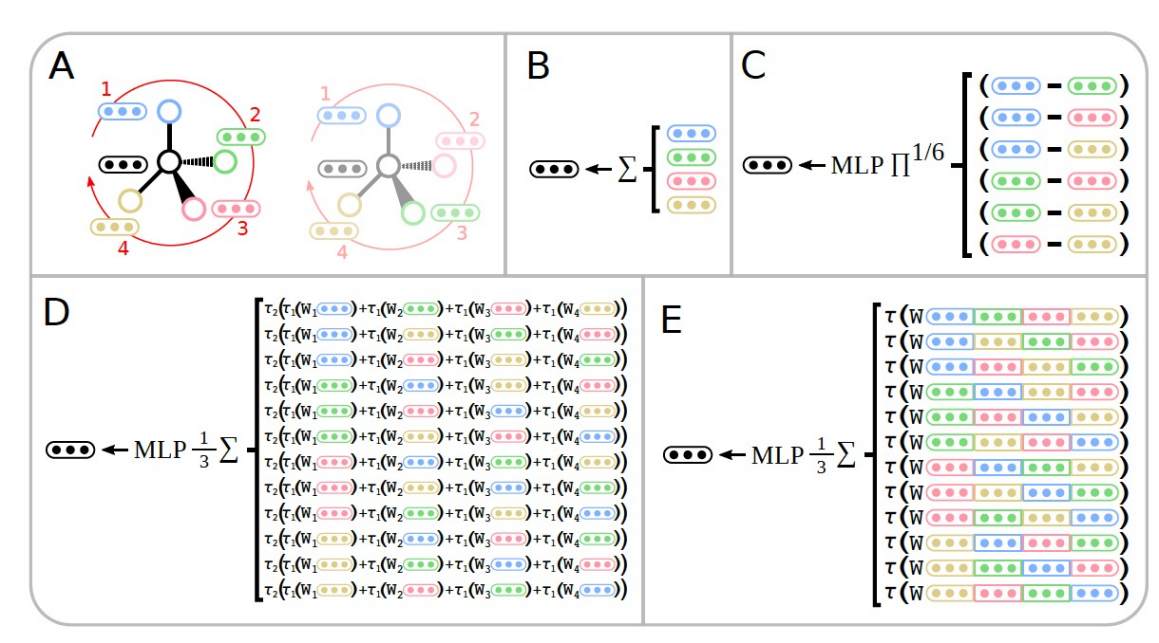
The authors address the challenge of incorporating molecular stereochemistry, particularly tetrahedral chirality, into the operation of message-passing neural networks (MPNNs). MPNNs manipulate molecular representations in the form of graphs, where atoms are nodes and chemical bonds are edges. These networks iteratively aggregate representations of neighboring nodes through message-passing iterations. However, traditional aggregation functions for graph-structured data, such as summation, averaging, and maximum pooling, are symmetric operations. Since molecules with tetrahedral chirality exhibit the same graph connectivity, symmetric aggregation operators, when applied to different chiral centers, collapse their neighboring nodes to the same representation regardless of their chirality. This constitutes a major challenge in implementing chirality within the MPNN architecture.
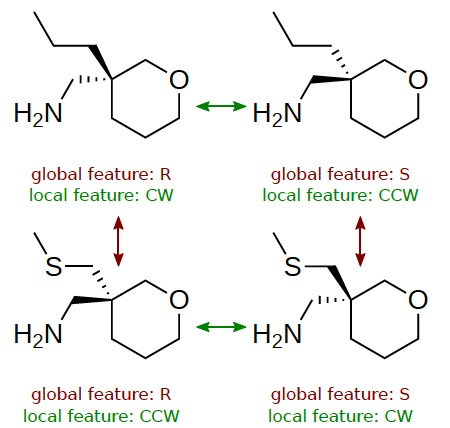
On the surface, MPNNs could capture stereochemistry through global descriptors such as R/S atomic features, differentiating enantiomers (non-superimposable stereoisomers, mirror images) using these features. These global descriptors represent a holistic measure of chirality, determined by the CIP (Cahn-Ingold-Prelog) side-chain ranking rules. However, Figure 1 illustrates why global chiral descriptors as atomic features are insufficient to meaningfully distinguish these structures within MPNNs. With global descriptors, two "R" structures would receive the same atomic-level features, while two "S" structures would receive different features. Yet, despite sharing the same global descriptor, the local arrangement around the tetrahedral center differs for each "R" structure.
Another approach involves capturing relevant information through local chiral descriptors, indicated by CW/CCW labels as shown in Figure 1, commonly used in SMILES representation. Chiral centers are assigned odd/even labels (CW or CCW) based on the order of neighboring atoms relative to their spatial orientation (as provided in the given SMILES string), assigning them to one of 12 equivalent arrangements of local chirality groups. The authors' model combines this local parity bit with an ordered set of neighbors, as opposed to using the parity bit directly as an atomic feature, in order to preserve physically meaningful invariance and avoid sensitivity to arbitrary notations and SMILES normalization conventions.
For the chirality of tetrahedral centers, the model ensures that the structure of the aggregation function P(C) on the same chiral group is such that the output results are consistent:
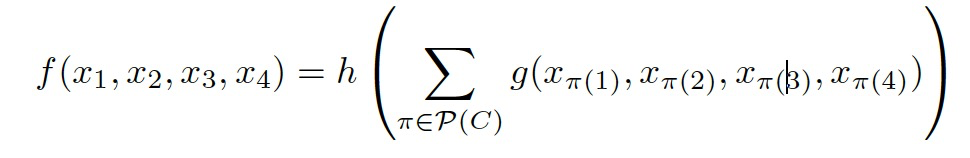
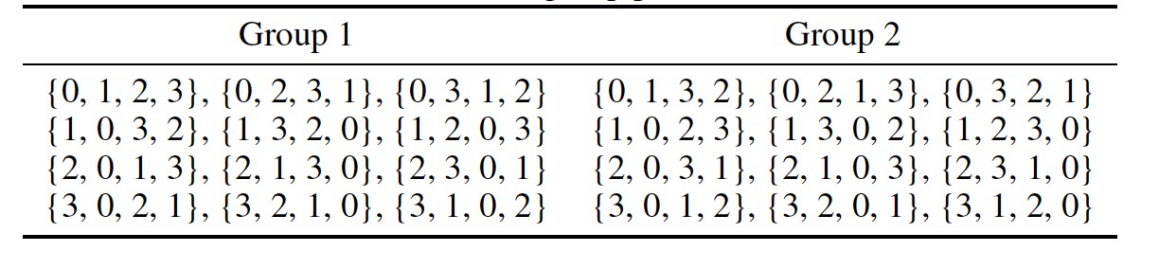
To meet this design requirement, two aggregation methods are proposed. The first method is the permutation-based approach , which computes the results of sorting all chiral group members listed in Table 2, ensuring consistency of results within the same chiral group and producing distinct results across different chiral groups. The second method is the permutation-and-concatenation-based approach, with a conceptual strategy similar to the first method.
Most property prediction datasets lack clean stereochemical information, preventing benchmarking of stereochemistry-aware models. To address this, the authors extract a subset of data from the D4 dopamine receptor protein-ligand docking screening dataset. Stereoisomers may exhibit different interaction energies when binding to target proteins due to distinct accessible conformations/poses. The dataset (D4DCHP) reduces the original 138 million molecules to pairs of stereoisomers involving a single 1,3-dicyclohexylpropane scaffold. Two additional subsets are defined: one where enantiomers differ by more than 5 kcal/mol in docking score (DIFF5) and another where molecules contain a single tetrahedral center (CHIRAL1). Performance is also evaluated on the "Lipo" dataset, containing 1,127 out of 4,200 molecules with at least one tetrahedral center; however, unlike the D4DCHP dataset, this dataset lacks complete enantiomer pairs.
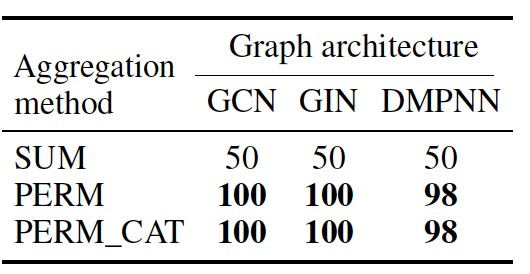
To ensure that the proposed aggregation methods can comprehend tetrahedral stereochemistry, the authors first evaluate them on the straightforward task of classifying molecules from CHIRAL1 as R or S. This task tests whether MPNNs can (1) distinguish enantiomers and (2) learn the CIP rules for assigning R/S labels. Given identical input atomic/bond features and graph connectivity for enantiomer pairs, the accuracy of a summation aggregator is expected to be around 50%. Empirical results (Table 2) support this hypothesis. Summation aggregators within MPNN architectures perform worse than random classifiers, while custom aggregators achieve near-perfect accuracy for classifying molecules as R or S.
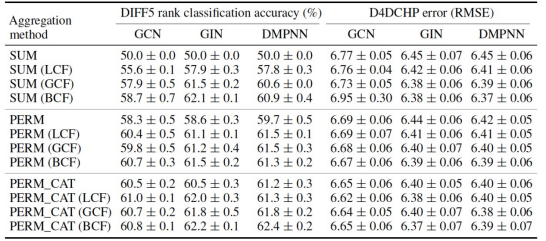
Next, empirical performance is evaluated on the full D4DCHP dataset. In the absence of atomic-level stereochemical features, the asymmetric aggregation methods PERM and PERM_CAT exhibit significant advantages over the SUM aggregator baseline. When stereochemical features are present, the performance of different aggregation methods depends on the architecture. Custom aggregation functions show measurable improvements in ranking classification and RMSE for the GCN architecture. However, for the GIN and DMPNN architectures, these improvements are less pronounced. For GIN, the inclusion of atomic-level stereochemical features captures trends that the custom aggregator captures when these features are absent. In the case of DMPNN, custom aggregators provide improvement in ranking classification but not in RMSE. The strong impact of atomic-level stereochemical features is noteworthy. By including just two additional atomic-level features, the SUM aggregator achieves around a 10% increase in ranking classification accuracy Regardless of how the graphical architecture is designed, more expressive graphical architectures can use this three-dimensional information more effectively. As a result, the explicit isotropy provided by custom aggregators no longer offers significant advantages. However, the highest observed ranking classification accuracy of 62% still has room for improvement, which stimulates further research into learning methods that can better handle the representation of tetrahedral stereochemistry.
Conclusion
We has developed two aggregation functions to learn the properties of molecules with tetrahedral chirality. Custom aggregators can fully distinguish enantiomers in the toy R/S classification problem, and in the newly proposed D4DHCP dataset, they exhibit performance that is comparable or moderately improved compared to the baseline SUM aggregator, depending on the inclusion or exclusion of MPNN architecture and atomic-level stereo features.

Dr. Alexander Hughes
Medical Assistant