Drug patents are distinct. In order to enhance their quality before granting, regulatory agencies can employ predictive models.
Drug patents provide crucial incentives for the development of life-saving drugs, but if granted improperly, they can lead to competition delays and access restrictions. Despite patents having a maximum validity of 20 years, pharmaceutical companies often seek longer protection periods by applying for "secondary" or follow-on patents covering alternative formulations, dosages, uses, and drug combinations. Additionally, companies can apply for "extension" patents to increase the density of patent protection. Legislators are increasingly concerned about the impact of weak secondary patents on the phenomenon known as the "patent thicket," where each patent poses an obstacle to generic competition.
To address these concerns, the United States Patent and Trademark Office (USPTO) has sought input on how to improve patent quality for drug patents before granting. Investing in the quality of drug patents prior to granting is attractive because invalidating low-quality drug patents after granting can cost millions of dollars. However, the task of managing pre-grant quality measures for drug patents is complicated by their scarcity. Under the law, only specific patents can be listed in the U.S. Food and Drug Administration (FDA) "Orange Book." In fact, less than 0.12% of all patents are drug patents, and within technology fields related to pharmaceuticals, drug patents make up less than 3.8%. Therefore, determining which among the numerous applications will become "drug patents" (defined as patents listed in the Orange Book for approved drugs) is a daunting challenge.
Here, we provide a potential solution by introducing the characteristics of drug patents and a model for predicting which patent applications and patents are likely to become drug patents. To develop these models, we applied descriptive statistics and machine learning methods to drug patents from 2005 to 2015 and a control group of patents in the same technical field. Patent applications destined for the Orange Book differ in several ways from similar patent applications: they are more likely to have related prior patents listed in the Orange Book (increased by 20 times), be subject to the "Track One Acceleration" program (increased by 14 times), have a greater number of related patents and applications (increased by 2 to 7 times), and include "terminal disclaimer declarations" (increased by 7 times).
We also found that it is possible to predict whether applications and patents will ultimately be listed in the Orange Book based on publicly available features. Predictive models developed based on patent features perform well to excellent, with area under the curve (AUC) scores for predicting the status of drug patents ranging from 0.85 to 0.92, depending on the features available at the time of publication and grant. Our results confirm the distinctiveness of drug patents and patent applications from others and suggest that machine learning methods can be used to help identify potential drug patents that may be of interest to the USPTO. The findings are also relevant to generic competition because they can benefit from a more transparent understanding of the scope of protection of brand drugs before patents are officially listed in the Orange Book.
Method:
We collected data on drug patents approved by the U.S. Food and Drug Administration (FDA) between 2005 and 2015, as well as control patent data in the same technological field, along with related patent application data. Data sources included: (i) the United States Patent and Trademark Office (USPTO) Patent View database for patent literature data; (ii) Google Patents for domestic and international patent family data; (iii) USPTO's Patent Examination Research Dataset for patent application and examination variables; (iv) the February 2022 version of the Orange Book; (v) the Orange Book Patent Monopoly Data from the National Bureau of Economic Research (NBER). By combining the current version with the NBER's Orange Book, we were able to model not only patents appearing in the current Orange Book but also patents from previous versions.
The sample construction process initially identified all patents granted by USPTO examining units (referred to as "art units") that granted at least 100 Orange Book patents during the sample period. To exclude related non-pharmaceutical technology patents belonging to these art units, we further restricted the sample to two subcategories that together comprised 85% of the patents in the Orange Book. Ultimately, the sample included 50,541 patents, with 2,235 ultimately listed in the Orange Book, considered our "treated" group; the rest formed our "control" group.
For each patent and related patent application, we collected feature data reflecting patent documents, examination processes, families, citations, parties, and ownership entities (Table 1) and generated summary statistics for each patent application and patent subgroup, calculating t-statistics and standardized mean differences (SMD). To better understand the uniqueness of drug patents, we compared them not only to the control group but also to all patents granted during the sample period. To account for the gradual availability of information over the patent application life cycle, we differentiated features that were publicly available at the time of patent application publication (typically 18 months after submission) and at the time of patent grant. The value portion of predictive models depends on how early they can reveal relevant information before it becomes known. To estimate temporal differences, we computed lag periods between patent application and grant dates and compared them with the listing dates in the Orange Book provided by the Evergreen Drug Patent Database, which compiles data on consecutive versions of the Orange Book.
1
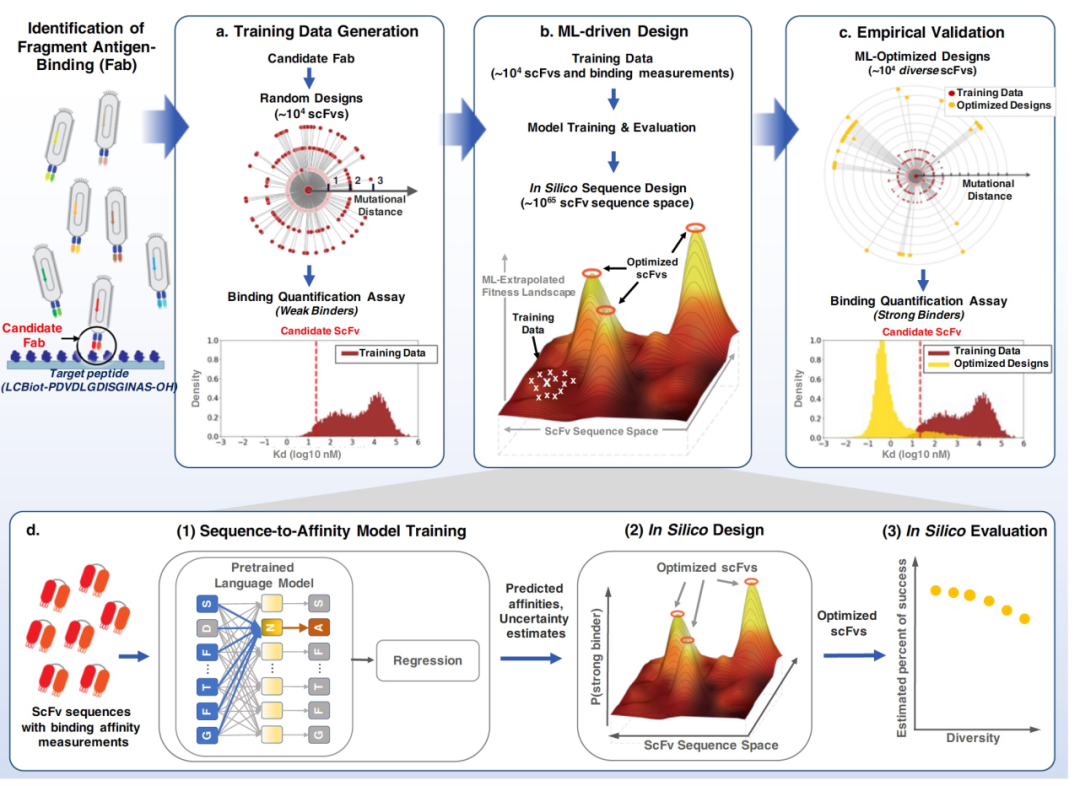
Firstly, the United States Patent and Trademark Office (USPTO) is considering stricter examination of continuation patent applications, which allow applicants to submit applications for variations of inventions disclosed in earlier patents. As a proxy indicator, we calculated the number of domestic and international members in families with at least one drug patent at the time of submission and grant. Secondly, the agency indicated it would review terminal disclaimer declarations to overcome "obvious-type double patenting rejections," which allow patentees to obtain patents for "innovative obvious variants" already covered by their other patents. Therefore, we tracked the prevalence of this practice by encoding whether patents contain "terminal disclaimer declarations." Building on previous attempts to predict significant patents, we employed a random forest machine learning model to predict whether any given patent would be listed in the Orange Book. Random forests are a set of independent decision trees that vote on whether a patent will ultimately be listed in the Orange Book. Each independent decision tree first constructs a tree based on variables (e.g., examination time, terminal disclaimer, etc.) and, for each branch in the tree, determines the best split point that distinguishes between drug patents and control patents in the training data. We chose this approach over regression models because random forests excel in prediction, especially when modeling complex systems like the patent system.
To reflect the temporal changes in data availability, we trained one model using data available from the USPTO at the time of application submission and data available to the public at the time of publication (typically 18 months later). Then, we trained a second model using data available at the time of patent grant. Primary and secondary drug patents have different characteristics, and information about them can be obtained at different stages of the application process. Specifically, some secondary patents already have family members listed in the Orange Book, a feature that may disproportionately influence the results. Therefore, as a robustness check, we also generated additional models where the first model included only primary patents (the first patent in a family), and the second model included only secondary patents (subsequent patents in a family). Standard methods were then used to assess the models' success: (i) receiver operating characteristic (ROC) curves and their associated area under the curve (AUC) statistics, and (ii) confusion matrices. ROC curves provide an intuitive visualization of a classification model's performance by plotting the true positive rate against the false positive rate at various thresholds, while the AUC measures the two-dimensional area under the ROC curve. Confusion matrices further illustrate the model's predictive performance for listing patents in the Orange Book at a given threshold.
Experimental results
1
We first analyzed the differences between drug patents and their applications compared to the control group patents (Figure 1a). The most significant differences include a 20-fold higher likelihood of having related prior patents listed in the Orange Book and a 14-fold higher likelihood of undergoing "Track One" accelerated examination. Drug patents also involve more related patents and applications (2 to 7 times), are more likely to contain "terminal disclaimer declarations" (7 times), and non-patent literature citations (including literature submitted by the applicants, 13 times) compared to the average patent. Among all patents, only 4.7% contain terminal disclaimer declarations, while 34.7% of drug patents include this declaration; among drug patents that already have prior family members, 58% include terminal disclaimer declarations. In terms of other features, drug patents do not exhibit statistically significant differences from control group patents on average. The differences between drug patents and control group patents become more pronounced in subsequent patents listed in the Orange Book, whereas they are relatively moderate in drug patents initially listed in the Orange Book. On average, each drug in the Orange Book is associated with 5.4 patents and 2.7 patent families. However, there is significant variation among drugs in the study: 50% of drugs involve only three patents or fewer, while less than 2% of drugs involve more than 20 patents. The average lag time between application submission and Orange Book listing is 7.9 years (standard deviation of
2
Our model demonstrates high accuracy in predicting drug patents, as shown by the ROC curve in Figure 2a. Our model has an overall accuracy of 95%, precision of 48%, and recall of 45%. As indicated in the confusion matrix in Figure 2b, specifically, 93.3% of publications are correctly predicted not to be listed in the Orange Book, 2.0% of patents are correctly identified as listed in the Orange Book, with a false positive rate of 2.4% and a false negative rate of 2.2%. At the time of grant, these numbers improve further to 2.4% true positives, 1.3% false positive rate, 94.3% true negatives, and 2.0% false negative rate, translating to an accuracy of 97%, precision of 65%, and recall of 55%. Figure 1b displays the ranking of feature importance used by the predictive model. The most predictive features for whether a patent application will ultimately become a drug patent include the technology group, the length of the specification, and the experience level of the inventors, assignees, and attorneys of the applying patent. It's also notable that despite being used as a sample selection criterion, the technology group still exhibits high predictive power for listings in the Orange Book. This predictive power reflects the fact that, even though all patents in the sample were examined by technology groups that grant a substantial number of drug patents, the percentage of patents listed in the Orange Book varies among these technology groups.
Finally, we confirmed an intuition that the number of prior drug patents in a patent family at the time of grant is the strongest predictor for its future inclusion in the Orange Book. Robustness checks indicate that this information can be effectively used to predict secondary patents during the application stage: when considering only secondary patents, the accuracy reaches 99%, with precision and recall based on application features being 70% and 54%, respectively. When the model considers only primary patents, the accuracy is 97%, with precision and recall based on application features being 24% and 29%, respectively. Our study has some limitations and limited generalizability in several key aspects. Our focus was on drug patents, which means certain small molecule drug patents prohibited from being listed in the FDA Orange Book were excluded, as were patents covering biopharmaceutical drugs, which are increasingly important. Additionally, there is significant variation in the number of patents covering a particular drug, but the model does not control for this variation, which may lead to variations in predictive power based on the scale of drug patent portfolios. The Orange Book is continuously evolving in each edition, and we decided to use any patents that have appeared in the Orange Book at any time when training the model, which might make the model overly inclusive of patents appearing at a particular time point.
Conclusion:
We found that drug patent applications differ from control applications, and their features can be used to predict to some extent whether a patent will ultimately be listed in the Orange Book, though not perfectly. Our research provides the first "proof of concept" evidence that features observable during the patent application (by patent examiners), publication, and grant (by the public) phases are useful for predicting whether a patent will eventually become a drug patent.
The research results may be of interest to policymakers who wish to improve the quality of drug patents before granting and target this effort without excessively burdening the examination of all patents. Currently, targeting such efforts is challenging, as patents are typically not identified as covering drugs until several years later. Our descriptive and predictive research findings can help regulatory agencies determine which applications may warrant further examination or greater attention and how to regulate patent examination practices to prevent low-quality patents without inhibiting innovation. It can also assist decision-makers in determining how to regulate patent examination practices to prevent the production of low-quality patents while not impeding innovation.

Dr.Sunny
Medical Assistant