NI-42
Content Navigation
Product Name
IUPAC Name
Molecular Formula
Molecular Weight
InChI
InChI Key
SMILES
solubility
Synonyms
Canonical SMILES
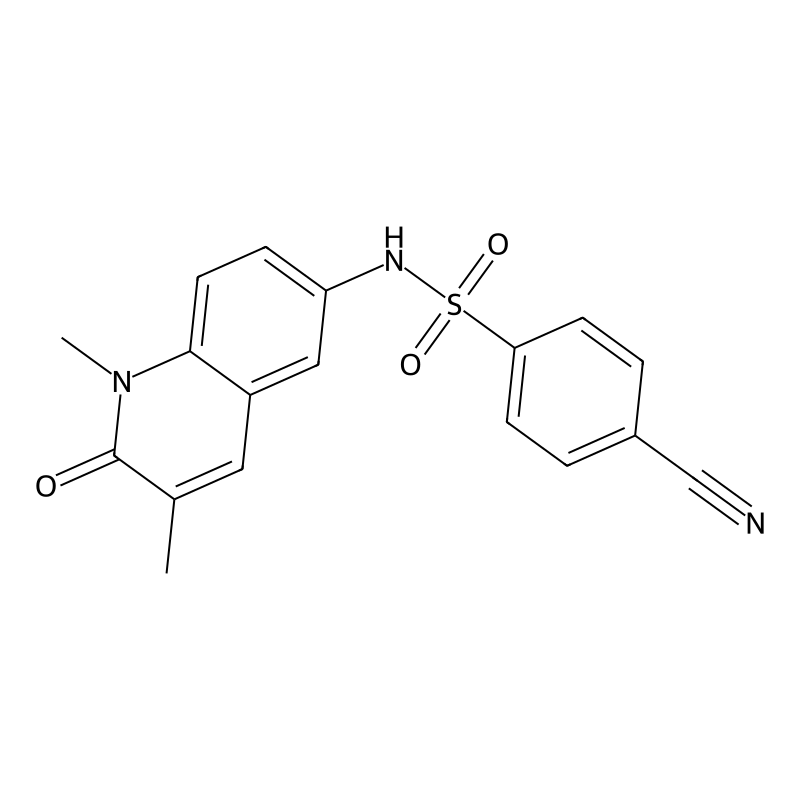
NI-42 (CAS: 1884640-99-6) is a highly potent, orally bioavailable pan-inhibitor of the bromodomain and PHD finger-containing (BRPF) family of scaffolding proteins. Featuring an N-methylquinolin-2-one core, it delivers a primary IC50 of 7.9 nM against BRPF1, alongside measurable activity against BRPF2 and BRPF3 [1]. For procurement and assay design, its primary value lies in its structural orthogonality to standard benzimidazolone-based inhibitors, its excellent in vivo pharmacokinetic profile (49% oral bioavailability in murine models), and its strict selectivity against non-class IV bromodomains such as BRD4 [2]. These properties make NI-42 an essential tool compound for validating the role of MYST histone acetyltransferase complexes in oncology and chromatin remodeling workflows.
Substituting NI-42 with standard benzimidazolone-class BRPF inhibitors (such as GSK5959 or PFI-4) introduces significant risks in target validation workflows [1]. Because small-molecule epigenetic probes often carry chemotype-specific secondary pharmacology profiles, relying on a single chemical scaffold can yield false-positive phenotypic results driven by off-target binding. NI-42 provides a structurally orthogonal N-methylquinolin-2-one acyl-lysine mimic[1]. Utilizing NI-42 alongside a benzimidazolone probe ensures that observed cellular or in vivo effects—such as the inhibition of acute myeloid leukemia (AML) cell proliferation—are genuinely driven by BRPF inhibition rather than scaffold-specific artifacts. Furthermore, substituting with non-selective pan-bromodomain inhibitors risks confounding data with dominant BET family (BRD4) transcriptional suppression.
Structural Orthogonality for Target Validation
To robustly validate BRPF as a therapeutic target, researchers must distinguish on-target epigenetic modulation from off-target artifacts. NI-42 utilizes an N-methylquinolin-2-one scaffold, which is structurally orthogonal to the 1,3-dimethylbenzimidazolone core used in standard probes like GSK5959 and PFI-4 [1]. This structural divergence provides a distinct secondary pharmacology fingerprint while maintaining primary target affinity (BRPF1 IC50 = 7.9 nM)[1].
| Evidence Dimension | Chemical Scaffold / Core Structure |
| Target Compound Data | N-methylquinolin-2-one (NI-42) |
| Comparator Or Baseline | 1,3-dimethylbenzimidazolone (GSK5959, PFI-4) |
| Quantified Difference | Orthogonal chemotype with distinct secondary pharmacology fingerprint |
| Conditions | Epigenetic probe library selection |
Procuring orthogonal probes is essential for ruling out scaffold-specific off-target effects during preclinical target validation.
In Vivo Suitability and Oral Bioavailability
For translational research transitioning from cellular assays to animal models, pharmacokinetic viability is a primary selection criterion. NI-42 demonstrates an oral bioavailability (Fpo) of 49% in mouse models, with a systemic clearance rate of 4 mL/min/kg (IV) and a plasma half-life of 2.0 hours [1]. This allows for effective oral dosing (e.g., 3 mg/kg), whereas earlier generation or alternative probes often suffer from poor solubility or require intraperitoneal (IP) administration [2].
| Evidence Dimension | Oral Bioavailability (Fpo) |
| Target Compound Data | 49% (NI-42) |
| Comparator Or Baseline | Alternative probes requiring IP dosing (e.g., early piperidine analogs) |
| Quantified Difference | Enables direct oral administration with 49% systemic absorption |
| Conditions | Mouse pharmacokinetic models (3 mg/kg PO, 1 mg/kg IV) |
High oral bioavailability reduces the complexity and stress of in vivo dosing protocols compared to IP-restricted compounds.
Selectivity Against Non-Class IV Bromodomains (BET Family)
A major procurement risk when selecting bromodomain inhibitors is unintended cross-reactivity with the BET family (e.g., BRD4), which dominates cellular phenotypes and obscures BRPF-specific data. NI-42 exhibits excellent selectivity over non-class IV BRD proteins, showing >32-fold selectivity against BRD4 [1]. This ensures that the compound's anti-proliferative effects in acute myeloid leukemia (AML) models are strictly mediated by BRPF/MYST complex disruption rather than BET suppression [1].
| Evidence Dimension | Selectivity vs. BRD4 |
| Target Compound Data | >32-fold selectivity window for BRPF over non-class IV BRDs |
| Comparator Or Baseline | Non-selective pan-bromodomain inhibitors |
| Quantified Difference | Absence of BET-driven phenotypic interference |
| Conditions | BROMOscan and Differential Scanning Fluorimetry (DSF) assays |
Ensures that resulting assay data is not confounded by the dominant transcriptional suppression typical of BRD4 off-target binding.
Pan-BRPF Profiling vs. Isoform-Specific Probes
While some probes like PFI-4 are highly selective for the BRPF1B isoform (failing to inhibit BRPF1A), NI-42 acts as a biased pan-BRPF inhibitor[1]. It exhibits high affinity for BRPF1 (Kd = 40 nM), while maintaining measurable activity against BRPF2 (Kd = 210 nM) and BRPF3 (Kd = 940 nM) [1]. This broad-spectrum class IV activity makes NI-42 the preferred choice when the exact BRPF isoform driving the disease phenotype is unknown or when simultaneous inhibition of the MYST HAT scaffolding complex is desired.
| Evidence Dimension | Target Isoform Coverage |
| Target Compound Data | Pan-BRPF activity (BRPF1 Kd=40 nM, BRPF2 Kd=210 nM, BRPF3 Kd=940 nM) |
| Comparator Or Baseline | PFI-4 (Strictly selective for BRPF1B, inactive against BRPF1A) |
| Quantified Difference | Broader class IV bromodomain coverage |
| Conditions | Isothermal Titration Calorimetry (ITC) / AlphaScreen assays |
Provides comprehensive BRPF family inhibition, preventing compensatory activity from uninhibited isoforms in phenotypic screens.
Orthogonal Target Validation in Epigenetic Screening
Using NI-42 in parallel with benzimidazolone probes (like GSK5959) to confirm that observed phenotypes in chromatin remodeling assays are genuinely BRPF-dependent, ruling out scaffold-specific secondary pharmacology [1].
In Vivo Oncology and Leukemia Models
Procuring NI-42 for murine models of acute myeloid leukemia (AML), where its 49% oral bioavailability allows for non-invasive, systemic dosing to evaluate the therapeutic potential of MYST complex disruption [1].
Broad-Spectrum MYST Complex Inhibition
Utilizing NI-42 in assays where pan-BRPF inhibition is required to overcome potential compensatory mechanisms between BRPF1, BRPF2, and BRPF3, which highly isoform-selective probes like PFI-4 cannot achieve [2].
Purity
XLogP3
Hydrogen Bond Acceptor Count
Hydrogen Bond Donor Count
Exact Mass
Monoisotopic Mass
Heavy Atom Count
Appearance
Storage
Dates
Explore Compound Types