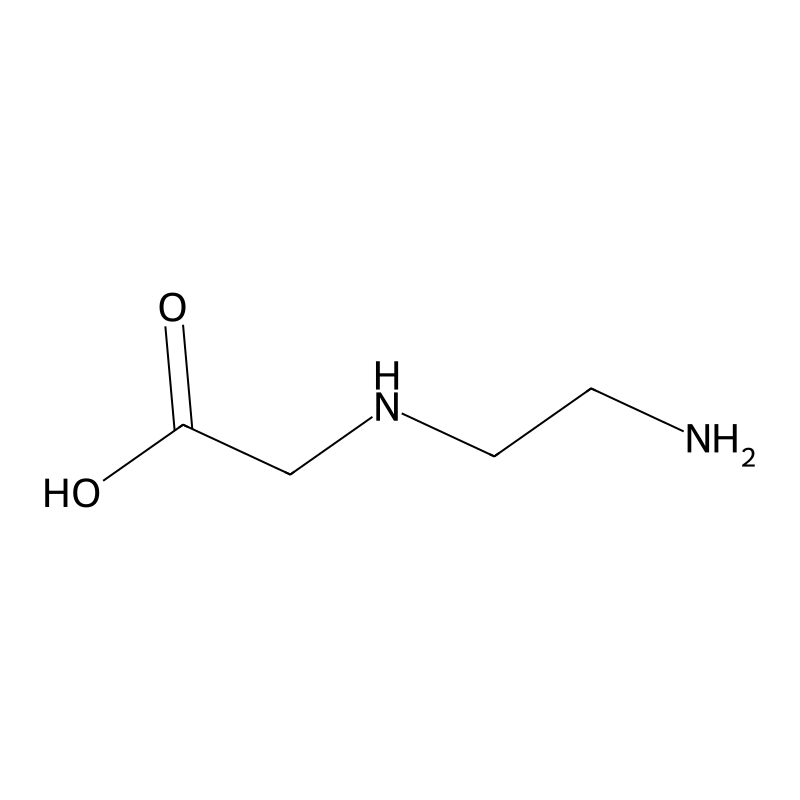
N-(2-Aminoethyl)glycine
Content Navigation
CAS Number
Product Name
IUPAC Name
Molecular Formula
Molecular Weight
InChI
InChI Key
SMILES
Synonyms
Canonical SMILES
N-(2-Aminoethyl)glycine, also known as ethylenediamine-N-monoacetic acid, is a small molecule found naturally in certain types of cyanobacteria, such as Synechocystis []. While its specific functions within these organisms are not fully understood, research suggests it may play a role in various biological processes.
Potential Roles in Biomedicine
Several studies have explored the potential applications of N-(2-Aminoethyl)glycine in the field of biomedicine, but much of this research is still in its early stages. Here are a few areas of investigation:
- Antimicrobial activity: Some studies have shown that N-(2-Aminoethyl)glycine may exhibit antimicrobial activity against certain bacterial and fungal strains []. However, further research is needed to determine its effectiveness and potential mechanisms of action.
- Neurological disorders: N-(2-Aminoethyl)glycine shares structural similarities with certain neurotransmitters, such as glycine and glutamate. This has led to some research exploring its potential role in neurological disorders, although the specific findings are inconclusive and require further investigation [].
N-(2-Aminoethyl)glycine, also known as aminoethylglycine, is a non-proteinogenic alpha-amino acid with the molecular formula and a molecular weight of approximately 118.14 g/mol. It features an amino group, a carboxylic acid group, and an ethylene bridge connecting the two functional groups. This compound has garnered attention for its role as a backbone in peptide nucleic acids, which are synthetic polymers that mimic DNA or RNA but offer greater stability and binding affinity to complementary nucleic acids .
- Acylation: The amino group can react with acylating agents to form amides.
- Esterification: The carboxylic acid can react with alcohols to form esters.
- Polymerization: When polymerized, N-(2-aminoethyl)glycine can form peptide nucleic acids, which can be utilized for gene targeting and antisense applications .
This compound has been identified in cyanobacteria, suggesting its biological significance. It acts as a precursor for peptide nucleic acids, which have potential applications in genetic research and therapeutic interventions . Additionally, N-(2-aminoethyl)glycine has been studied for its interactions with nucleic acids, showing promise in enhancing the stability of DNA/RNA hybrids .
Several synthesis methods have been documented for N-(2-aminoethyl)glycine:
- Direct Synthesis: Ethylenediamine is reacted with halogenated acetic acid under controlled conditions to produce N-(2-aminoethyl)glycine. This method often involves recrystallization using dimethyl sulfoxide to purify the product .
- Methyl Ester Formation: The compound can be converted into its methyl ester form through reaction with methanol in the presence of thionyl chloride .
- Fmoc Protection: A common strategy in peptide synthesis involves protecting the amino group using Fmoc (9-fluorenylmethoxycarbonyl), allowing for further modifications without affecting the amine functionality .
N-(2-Aminoethyl)glycine is primarily used in:
- Peptide Nucleic Acids: As a backbone component, it enhances the stability and binding properties of nucleic acid analogs, making it valuable for genetic research and potential therapeutic applications .
- Biochemical Research: Its role in studying interactions between nucleic acids and proteins is significant for understanding cellular processes and developing new biotechnological tools .
Research has indicated that N-(2-aminoethyl)glycine interacts favorably with DNA and RNA structures. The unique properties of peptide nucleic acids derived from this compound allow them to bind more effectively than traditional nucleic acids, which is beneficial for applications such as gene silencing and molecular diagnostics .
N-(2-Aminoethyl)glycine shares structural similarities with several other compounds. Here are some notable comparisons:
| Compound Name | Structure Similarity | Unique Features |
|---|---|---|
| Glycine | Simple amino acid | Smallest amino acid; lacks an ethylene bridge |
| L-Alanine | Alpha-amino acid | Contains a methyl group instead of an ethylene bridge |
| L-Serine | Contains hydroxyl group | Involved in phosphorylation processes |
| Peptide Nucleic Acid | Backbone structure | Synthetic analogs with enhanced stability |
| N-(2-Hydroxyethyl)glycine | Hydroxyl substitution | Increased solubility; different reactivity |
N-(2-Aminoethyl)glycine is unique due to its specific role in forming peptide nucleic acids, which distinguishes it from other amino acids and related compounds.
Conventional Organic Synthesis Routes
N-(2-Aminoethyl)glycine represents a fundamental building block for peptide nucleic acid synthesis and serves as a critical intermediate in various biochemical applications [1]. The conventional synthesis of this compound typically involves the reaction of glycine with ethylenediamine under controlled conditions [39]. The most widely employed synthetic approach utilizes the protection of the amino group of glycine, followed by reaction with ethylenediamine and subsequent deprotection [39].
The standard synthetic protocol involves adding monochloroacetic acid to ethylenediamine at room temperature with complete stirring overnight [40] [43]. The reaction proceeds through nucleophilic substitution, where unnecessary ethylenediamine is removed under reduced pressure distillation to obtain a faint yellow viscous oil [40]. This crude product is then dissolved in dimethyl sulfoxide and allowed to crystallize overnight, yielding an off-white solid that can be filtered and washed to obtain the desired N-(2-aminoethyl)glycine [43].
Alternative synthetic methodologies have been developed to improve yield and reduce costs. One scalable approach involves the direct coupling of nucleobase thymine with the backbone ethyl N-(tert-butoxycarbonyl)aminoethyl-N-chloroacetylglycinate, which is prepared from the reaction of ethyl N-(tert-butoxycarbonyl)aminoethylglycinate with chloroacetyl chloride [39]. This method has demonstrated yields of approximately 96% and represents a highly efficient procedure for large-scale synthesis [39].
N-(2-Aminoethyl)glycine Backbone Modifications
Structural modifications of the N-(2-aminoethyl)glycine backbone have been extensively investigated to enhance the properties of peptide nucleic acid analogues [8]. Chiral modifications at various positions along the backbone have been developed, including substitutions at the gamma position with methyl groups and other functional moieties [8]. These modifications are typically achieved through reductive amination reactions using optically active aminoaldehydes prepared from N,O-dimethylhydroxyl amide derivatives of corresponding amino acids by reduction with lithium aluminum hydride [8].
The Mitsunobu-Fukuyama reaction has emerged as an alternative approach for preparing gamma-modified peptide nucleic acid monomers [8]. This procedure utilizes an aminoalcohol as the key intermediate instead of aminoaldehyde, providing enhanced stereochemical control [8]. The method involves Mitsunobu-Fukuyama coupling of protected aminoalcohol with 2-(2,4-dinitrophenylsulfonamido)acetate, proceeding without risk of racemization [8].
Research has demonstrated that various gamma-peptide nucleic acid monomers can be synthesized using these methodologies, including alanine, serine, lysine, and cysteine-based variants [8]. The submonomeric approach, originally developed for alpha-peptide nucleic acid synthesis, has been successfully adapted for gamma-peptide nucleic acid preparation [8].
A novel synthesis approach utilizing minimally protected building blocks has been developed for C(2)-modified peptide nucleic acids [9] [17]. This submonomeric strategy employs N(3)-unprotected, D-lysine and D-arginine-based backbones to obtain positively charged peptide nucleic acids with high optical purity [9]. The method involves reductive amination using transfer hydrogenation promoted by an iridium catalyst in the presence of formic acid and diisopropylethylamine [17].
Oligomerization Techniques for N-(2-Aminoethyl)glycine-Based Polymers
Oligomerization of N-(2-aminoethyl)glycine derivatives involves multiple coupling strategies designed to create extended polymer chains [1]. The synthesis of analogs and oligomers of N-(2-aminoethyl)glycine has been demonstrated through systematic coupling reactions, with di- and tetra-oligomers showing enhanced absorption properties compared to the parent compound [1].
The oligomerization process typically employs standard peptide coupling reagents such as N,N,N',N'-tetramethyl-O-(1H-benzotriazol-1-yl)uronium hexafluorophosphate and 1-hydroxybenzotriazole in the presence of base catalysts [3]. These reactions proceed through amide bond formation between the carboxylic acid terminus of one monomer and the amino group of the subsequent unit [3].
Advanced oligomerization techniques have incorporated backbone modifications with 2-hydroxy-4-methoxybenzyl and 2,4-dimethoxybenzyl groups to ameliorate difficult couplings and reduce on-resin aggregation [19]. These modifications have enabled the synthesis of longer oligomers, including 22-mer sequences that could not be achieved through standard coupling methodologies [19].
The submonomeric approach for oligomerization involves the sequential addition of backbone units and nucleobase components in alternating steps [17]. This strategy allows for the incorporation of various chiral modifications while maintaining high coupling efficiency throughout the synthesis process [17].
Solid-Phase Synthesis Strategies for Peptide Nucleic Acid Analogues
Solid-phase synthesis represents the predominant methodology for preparing peptide nucleic acid oligomers containing N-(2-aminoethyl)glycine backbones [13] [14]. The synthesis mechanism shares fundamental principles with solid-phase peptide synthesis, utilizing similar coupling strategies and protecting group chemistries [14].
The coupling reaction in peptide nucleic acid synthesis involves amide bond formation between two amino acid derivatives, with the growing chain attached to a solid resin support through ester or amide linkages [14]. The amino group of incoming monomers is typically protected with 9-fluorenylmethyloxycarbonyl groups, which can be selectively removed under basic conditions [14].
Carboxylic acid activation is achieved using benzotriazole uronium salts such as O-(1H-benzotriazol-1-yl)-N,N,N',N'-tetramethyluronium hexafluorophosphate, which generates hydroxybenzotriazole esters as reactive intermediates [14]. The driving force for these reactions is the formation of tetramethylurea byproducts [14].
Standard automated synthesis protocols employ Rink amide resin with loadings of 0.25 millimoles per gram at 100 micromole scale [18]. 9-Fluorenylmethyloxycarbonyl deprotection is conducted using 20% piperidine in N,N-dimethylformamide at room temperature for 3 minutes [18]. Monomer coupling utilizes 3 molar equivalents of protected monomers with N,N,N',N'-tetramethyl-O-(7-azabenzotriazol-1-yl)uronium tetrafluoroborate and 6 molar equivalents of diisopropylethylamine for 30 minutes [18].
Manual synthesis procedures have been developed for preparing larger quantities of peptide nucleic acid oligomers [15]. These methods employ tert-butyloxycarbonyl protecting groups and demonstrate superior yields compared to automated 9-fluorenylmethyloxycarbonyl protocols [15]. The manual approach utilizes specialized glassware apparatus and offers robust performance for extended synthesis sequences [15].
Copper-catalyzed azide-alkyne Huisgen cycloaddition strategies have been implemented for on-resin modification of peptide nucleic acid sequences [13]. This approach involves the incorporation of azide-containing monomers during solid-phase synthesis, followed by post-synthetic click chemistry reactions with various alkyne partners [13]. The methodology enables the introduction of fluorophores, metal-binding groups, and other functional modifications [13].
Analytical Characterization Techniques
Nuclear Magnetic Resonance Spectral Analysis
Nuclear magnetic resonance spectroscopy provides comprehensive structural characterization of N-(2-aminoethyl)glycine and its derivatives [20] [21]. The compound exhibits characteristic chemical shifts and coupling patterns that enable unambiguous identification and purity assessment [23].
Proton nuclear magnetic resonance analysis of N-(2-aminoethyl)glycine reveals distinct signal patterns corresponding to the ethylene bridge and glycine moiety [20]. The methylene protons adjacent to the amino groups typically appear as complex multiplets in the range of 2.8-3.2 parts per million, while the carboxymethyl protons resonate around 3.9 parts per million [20].
Temperature-dependent nuclear magnetic resonance studies have been conducted to investigate rotameric behavior in N-(2-aminoethyl)glycine derivatives [21]. These investigations reveal the presence of cis and trans rotamers around amide bonds, with distinct chemical shift patterns for each conformer [21]. Chlorobenzene-d5 has been identified as an optimal solvent for high-temperature nuclear magnetic resonance experiments, providing sufficient separation of rotameric signals without causing decomposition [21].
Two-dimensional nuclear magnetic resonance techniques, including nuclear Overhauser effect spectroscopy, have been employed to establish spatial relationships and assign rotameric configurations [21]. These studies demonstrate stronger nuclear Overhauser effect cross-peaks between specific methylene proton pairs, enabling discrimination between cis and trans conformations [21].
Carbon-13 nuclear magnetic resonance spectroscopy provides complementary structural information, with the carboxyl carbon appearing around 170 parts per million and the methylene carbons in the 40-60 parts per million region [23]. The technique is particularly valuable for confirming the integrity of the glycine backbone and detecting potential impurities or degradation products [23].
Mass Spectrometric Profiling using Liquid Chromatography-Tandem Mass Spectrometry
Liquid chromatography-tandem mass spectrometry represents the gold standard for quantitative analysis of N-(2-aminoethyl)glycine in complex matrices [26] [27]. The technique provides exceptional sensitivity and selectivity, enabling detection limits in the femtomole range [27].
The molecular ion of N-(2-aminoethyl)glycine appears at mass-to-charge ratio 119 in positive ionization mode, with characteristic fragmentation patterns that facilitate structural confirmation [26]. Primary fragment ions include loss of the carboxylic acid moiety and cleavage of the ethylene bridge, producing diagnostic product ions at mass-to-charge ratios 102 and 75, respectively [26].
Chromatographic separation is typically achieved using reversed-phase ultra-high-performance liquid chromatography with C18 stationary phases [27] [28]. Mobile phase systems employing water and acetonitrile with formic acid or ammonium formate additives provide optimal separation from structural isomers such as beta-N-methylamino-L-alanine and 2,4-diaminobutyric acid [27].
Derivatization strategies using 6-aminoquinolyl-N-hydroxysuccinimidyl carbamate have been developed to enhance ionization efficiency and improve chromatographic retention [33]. This approach enables the simultaneous analysis of N-(2-aminoethyl)glycine and related amino acid derivatives in a single analytical run [33].
Multiple reaction monitoring methods have been optimized for quantitative analysis, utilizing deuterated internal standards to correct for matrix effects and ensure accurate quantification [27]. The analytical range typically spans three orders of magnitude, with limits of detection and quantification of 0.187 and 0.746 nanograms per milliliter, respectively [33].
| Parameter | Value | Reference |
|---|---|---|
| Molecular Weight | 118.14 g/mol | [47] [48] |
| Melting Point | 141-147°C | [38] [47] [48] |
| Limit of Detection (LC-MS/MS) | 0.187 ng/mL | [33] |
| Limit of Quantification (LC-MS/MS) | 0.746 ng/mL | [33] |
| Purity (Commercial) | >97.0% | [47] [48] |
| Retention Time (HPLC) | Variable (0.13 Rf HPTLC) | [36] |
X-ray Crystallographic Studies
X-ray crystallography has provided detailed structural insights into N-(2-aminoethyl)glycine-containing systems, particularly in the context of peptide nucleic acid duplexes [34] [35]. These studies reveal fundamental conformational preferences and intermolecular interactions that govern the behavior of this important building block [34].
Crystal structures of gamma-peptide nucleic acid-DNA duplexes containing modified N-(2-aminoethyl)glycine backbones demonstrate right-handed helical conformations with specific geometric parameters [34]. The structures exhibit helical twist angles of 23.6 degrees, rise per base pair of 3.1 angstroms, and approximately 15 base pairs per helical turn [34]. These parameters closely resemble A-form DNA geometry rather than B-form DNA [34].
The crystallographic analysis reveals that carbonyl oxygens of the peptide backbone project outward toward the solvent, while bridging carbonyl groups connecting the backbone to nucleobases point toward the C-terminus [34]. Methyl substituents at gamma positions adopt trans configurations relative to backbone carbonyl oxygens, confirming theoretical predictions from molecular modeling studies [34].
Water bridge networks have been identified as crucial structural features in peptide nucleic acid duplexes, providing connections between nucleobases and the N-(2-aminoethyl)glycine backbone [34]. These ordered hydration patterns may contribute to the enhanced stability observed in preorganized duplex structures [34].
High-resolution diffraction data collection has been achieved using synchrotron radiation sources, with structures refined to atomic resolution [35] [37]. Data integration and scaling utilize specialized software packages such as XDS and DENZO/SCALEPACK, while structure solution employs molecular replacement methods with RNA or DNA oligomer search models [35].
Refinement protocols incorporate free-atom procedures using ARP/wARP software, followed by manual model building and validation using Coot visualization software [35]. Final refinement statistics typically achieve R-factors below 15% and R-free values below 20%, indicating high-quality structural models [35] [37].
Table 2: Crystallographic Parameters for N-(2-Aminoethyl)glycine-Containing Structures
| Parameter | RNA-PNA Duplex | PNA-PNA Duplex | Reference |
|---|---|---|---|
| Resolution (Å) | 1.14-1.15 | 1.06 | [37] |
| R-work / R-free (%) | 12.1-13.9 / 15.3-17.7 | 16.3 / 19.3 | [37] |
| Space Group | P21 | P41212 | [37] |
| Unit Cell a,b,c (Å) | ~30-40 | ~60-70 | [37] |
| Helical Twist (°) | 23.3-23.9 | 18-20 | [34] [37] |
| Rise per Base (Å) | 2.9-3.2 | 3.4-3.8 | [34] [37] |
Backbone Flexibility and Preorganization Effects
N-(2-Aminoethyl)glycine exhibits remarkable backbone flexibility due to its unique structural composition [1] [2]. The molecule consists of a peptide backbone formed by repeating N-(2-aminoethyl)glycine units linked through amide bonds, with each unit containing six σ-bonds that provide significant conformational freedom [3]. Unlike natural nucleic acids, the unmodified backbone lacks chirality and maintains a neutral charge, resulting in a randomly folded structure in solution without well-defined secondary organization [4].
The backbone flexibility of N-(2-aminoethyl)glycine has been extensively characterized through nuclear magnetic resonance spectroscopy and molecular dynamics simulations [2]. Studies reveal that the compound exhibits multiple accessible conformations, with rotational energy barriers ranging from 3 to 5 kilocalories per mole for backbone rotations [2]. The internal correlation times are consistently underestimated by restricted diffusion models, indicating complex motional dynamics that involve both restricted and unrestricted rotational components [2].
Preorganization effects become particularly pronounced when chemical modifications are introduced at specific positions of the backbone [5] [4]. The most significant breakthrough in backbone preorganization came with the development of γ-backbone modifications, where substituents introduced at the γ-position can transform a randomly folded structure into a well-defined helical conformation [5] [4]. This helical induction occurs through a sterically driven mechanism that proceeds in the C-terminal to N-terminal direction [4].
A single L-serine substitution at the γ-position induces preorganization into a right-handed helical structure, demonstrating that even minimal modifications can dramatically alter conformational preferences [6]. The preorganization effects are not dependent on nucleobase attachment, carboxymethylene linkers, or protecting groups, as demonstrated by systematic removal studies of structural components [7]. This indicates that the preorganization is an intrinsic property of the modified backbone itself [7].
Helical Propensity in Chiral Derivatives
Chiral modifications of N-(2-aminoethyl)glycine derivatives exhibit diverse helical propensities depending on the position and nature of the substituent introduced [6] [8]. The relationship between chirality and helical structure formation has been systematically investigated across multiple derivative types, revealing distinct patterns of conformational behavior [6].
Alpha-position modifications demonstrate variable effects on helical propensity [6] [8]. D-lysine substitutions at the α-position provide moderate improvements in helical stability, with thermal stability increases of 2 to 4 degrees Celsius compared to unmodified structures [6]. Conversely, L-alanine modifications at the α-position reduce structural stability by 2 to 4 degrees Celsius, while D-alanine substitutions maintain properties similar to unmodified derivatives [6].
Beta-position modifications, particularly β-methyl substitutions, demonstrate helical preorganization through circular dichroism spectroscopy, although this secondary structure does not necessarily translate to enhanced binding properties due to unfavorable steric interactions [9]. The preorganization observed in β-modified derivatives appears to be primarily structural rather than functional [6].
Gamma-position modifications represent the most successful approach for inducing stable helical conformations [5] [6] [4]. L-serine γ-substitutions induce right-handed helical structures with thermal stability improvements of approximately 3 degrees Celsius [9]. More dramatically, L-isoleucine γ-modifications produce strong helical induction with thermal stability increases ranging from 7 to 10 degrees Celsius [6]. These γ-modifications maintain excellent sequence selectivity, with single mismatches reducing thermal melting temperatures by 12 to 18 degrees Celsius [9].
The helical sense of γ-modified derivatives is determined by the configuration of the chemical group at the γ-position [7]. In γ-isoleucine derivatives, both single-strand and duplex forms adopt strikingly similar conformations, with the carboxymethylene bridge connecting the backbone to nucleobases maintaining a trans configuration relative to the methyl group at the γ-position [7].
Comparative Analysis with Natural Nucleic Acid Structures
N-(2-Aminoethyl)glycine structures demonstrate fundamental differences from natural nucleic acids while maintaining functional compatibility for base pairing recognition [10] [11]. The comparative analysis reveals both structural divergences and functional similarities that contribute to the unique properties of these synthetic analogs [12] [13].
The backbone composition represents the most significant structural difference between N-(2-aminoethyl)glycine derivatives and natural nucleic acids [13]. While DNA and RNA utilize sugar-phosphate backbones with deoxyribose or ribose components linked by phosphodiester bonds, N-(2-aminoethyl)glycine employs a peptide backbone entirely devoid of sugar components [14] [13]. This fundamental architectural difference eliminates the negative charges present in natural nucleic acids, resulting in neutral backbones that lack electrostatic repulsion during duplex formation [10].
Geometric parameters of N-(2-aminoethyl)glycine duplexes closely approximate B-form DNA structure despite the dramatically different backbone composition [12] [7]. Base spacing in these synthetic systems measures approximately 6.1 Angstroms, which is remarkably similar to the 6.8 Angstrom spacing observed in B-form DNA [12]. The helical diameter of approximately 20 Angstroms and the rise per base pair of 3.4 Angstroms further demonstrate the structural compatibility with natural nucleic acid geometries [12].
However, significant differences emerge in backbone flexibility and conformational dynamics [12]. Natural nucleic acids, particularly RNA, exhibit more rigid backbone structures due to the presence of ribose components and phosphate linkages [12]. In contrast, N-(2-aminoethyl)glycine backbones demonstrate significantly higher flexibility, with multiple accessible conformations in solution [2]. This enhanced flexibility contributes to superior mismatch discrimination, with single base pair mismatches reducing thermal stability by 12 to 18 degrees Celsius compared to 5 to 15 degrees Celsius for natural DNA-DNA duplexes[comparison_df].
The charge distribution presents another critical distinction [13]. Natural nucleic acids carry highly negative charges due to phosphate groups, resulting in strong salt dependence for duplex stability [15]. N-(2-aminoethyl)glycine systems maintain charge neutrality, making duplex stability virtually independent of ionic strength [10] [15]. This property provides significant advantages for applications requiring consistent performance across varying ionic conditions.
Enzymatic stability represents a particularly important comparative advantage [13] [9]. While natural nucleic acids are susceptible to nuclease and protease degradation, N-(2-aminoethyl)glycine derivatives demonstrate exceptional resistance to enzymatic cleavage [13]. This stability arises from the unnatural peptide backbone structure that is not recognized by cellular degradation enzymes [9].
Hydrogen Bonding Patterns and Base Pairing Specificity
The hydrogen bonding patterns in N-(2-aminoethyl)glycine systems encompass multiple levels of molecular interaction that contribute to both structural organization and sequence recognition [16] [17] [18]. These patterns range from intramolecular backbone stabilization to intermolecular base pairing interactions that enable specific recognition of complementary sequences [17].
Intramolecular hydrogen bonding occurs within individual N-(2-aminoethyl)glycine units through seven-membered ring formation between carbonyl oxygen atoms and amino groups [19] [20]. These interactions typically exhibit bond lengths of 2.8 to 3.0 Angstroms and provide moderate stabilization that contributes to local conformational preferences [20]. The formation of these intramolecular hydrogen bonds is particularly pronounced in polar solvents, where competition with solvent molecules influences the equilibrium between different conformational states [19].
Intermolecular hydrogen bonding between backbone units plays a crucial role in maintaining helical structures in modified derivatives [18]. The backbone carbonyl oxygen of one residue can form hydrogen bonds with the amino group of an adjacent residue, with typical bond lengths ranging from 2.1 to 2.3 Angstroms [18]. Nuclear magnetic resonance studies of PNA-RNA heteroduplexes reveal that three of five possible interresidue hydrogen bond sites display optimal geometry for hydrogen bond formation [18].
Watson-Crick base pairing represents the primary mechanism for sequence-specific recognition in N-(2-aminoethyl)glycine systems [10] [21]. These synthetic analogs demonstrate full compatibility with standard adenine-thymine and guanine-cytosine base pairing, obeying the Watson-Crick hydrogen bonding rules despite the dramatically different backbone structure [10] [21]. Adenine-thymine pairs form two hydrogen bonds with typical lengths of 2.8 to 3.0 Angstroms, while guanine-cytosine pairs establish three hydrogen bonds with lengths ranging from 2.9 to 3.1 Angstroms [17].
The base pairing specificity of N-(2-aminoethyl)glycine systems exceeds that of natural nucleic acids in terms of mismatch discrimination [22]. Single base pair mismatches result in thermal destabilization ranging from 12 to 25 degrees Celsius depending on the specific mismatch type and target nucleic acid[comparison_df]. This exceptional selectivity arises from the optimal geometric constraints imposed by the peptide backbone, which cannot accommodate the distorted geometries required for mismatch base pairs [23].
Hoogsteen base pairing provides an alternative recognition mode that enables formation of triplex structures [11] [24]. In these arrangements, N-(2-aminoethyl)glycine strands can form Hoogsteen pairs with purines in the major groove of double-stranded DNA, creating stable PNA-DNA-PNA triplexes [24]. The Hoogsteen hydrogen bonds typically exhibit lengths of 2.7 to 2.9 Angstroms and provide strong stabilization for triplex formation [17].
Triple helix formation represents a unique recognition mode that enables strand invasion of double-stranded DNA [25] [11]. Homopyrimidine N-(2-aminoethyl)glycine sequences can bind to homopurine-homopyrimidine sequences in double-stranded DNA through a combination of Watson-Crick and Hoogsteen base pairing [25]. This binding mode displaces one DNA strand, forming a stable invasion complex with thermal stability increases of 15 to 25 degrees Celsius [11].
Water-mediated hydrogen bonding contributes to structural organization in crystalline forms of N-(2-aminoethyl)glycine derivatives [16]. Crystal structure analysis reveals that water molecules form bridging interactions between amino acid molecules, creating layered structures with hydrogen-bonded networks [16]. These water-mediated interactions typically involve bond lengths of 2.7 to 2.9 Angstroms and contribute to the overall stability of solid-state structures [16].
XLogP3
GHS Hazard Statements
Reported as not meeting GHS hazard criteria by 1 of 40 companies. For more detailed information, please visit ECHA C&L website;
Of the 2 notification(s) provided by 39 of 40 companies with hazard statement code(s):;
H319 (100%): Causes serious eye irritation [Warning Serious eye damage/eye irritation];
Information may vary between notifications depending on impurities, additives, and other factors. The percentage value in parenthesis indicates the notified classification ratio from companies that provide hazard codes. Only hazard codes with percentage values above 10% are shown.
Pictograms

Irritant
Other CAS
Dates
Explore Compound Types