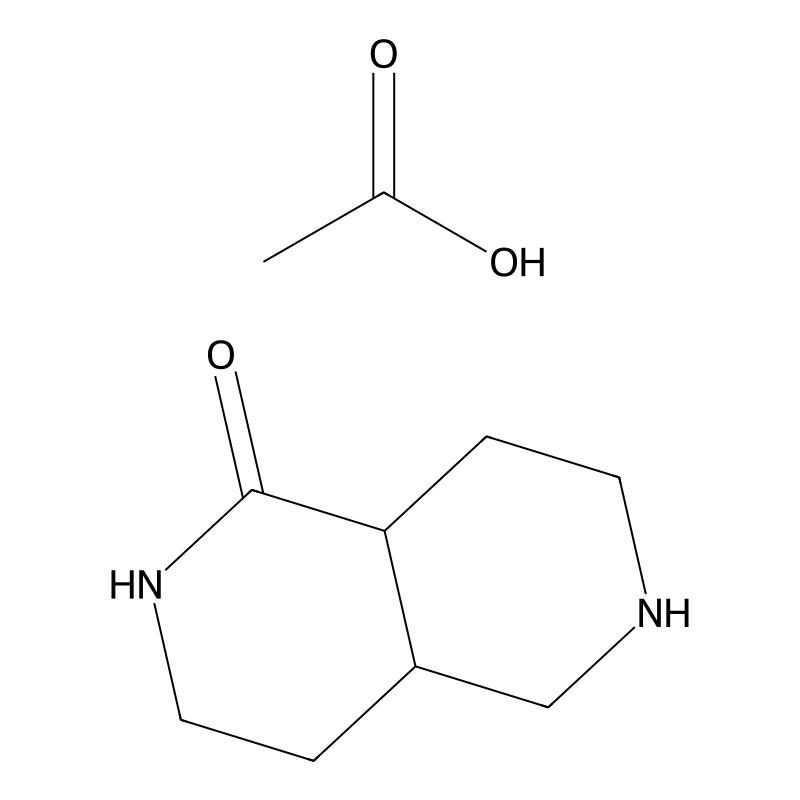
Octahydro-2,6-naphthyridin-1(2H)-one acetate
Content Navigation
Product Name
IUPAC Name
Molecular Formula
Molecular Weight
InChI
InChI Key
SMILES
Canonical SMILES
Octahydro-2,6-naphthyridin-1(2H)-one acetate is a complex organic compound characterized by a bicyclic structure that includes a naphthyridine core. This compound features a saturated ring system with two nitrogen atoms located in adjacent positions, specifically at the 1 and 5 positions of the naphthyridine framework. The acetate group contributes to its reactivity and solubility properties. Its chemical formula is C₁₁H₁₃N₂O₂, indicating the presence of carbon, hydrogen, nitrogen, and oxygen atoms.
Octahydro-2,6-naphthyridin-1(2H)-one acetate has several notable applications:
- Pharmaceuticals: Its derivatives are investigated for use in developing new antimicrobial and anticancer drugs.
- Agricultural Chemicals: Compounds with similar structures are explored as potential pesticides or herbicides due to their biological activity against pests.
- Material Science: The unique chemical properties may allow for applications in creating novel materials or polymers.
Research indicates that compounds related to octahydro-2,6-naphthyridin-1(2H)-one acetate exhibit significant biological activities. These include:
- Antimicrobial Properties: Studies have shown that naphthyridine derivatives possess antibacterial and antifungal activities, making them potential candidates for pharmaceutical applications .
- Antitumor Activity: Some derivatives have demonstrated cytotoxic effects against various cancer cell lines, suggesting their potential as anticancer agents.
- Neuroprotective Effects: Certain naphthyridine compounds have been explored for their neuroprotective properties in models of neurodegenerative diseases.
The synthesis of octahydro-2,6-naphthyridin-1(2H)-one acetate can be achieved through several methods:
- Cyclization Reactions: Starting from appropriate precursors like 2-amino-pyridines and carbonyl compounds, cyclization can yield naphthyridine structures. Catalysts such as iodine or transition metals may facilitate these reactions
Interaction studies involving octahydro-2,6-naphthyridin-1(2H)-one acetate often focus on its binding affinity with biological targets such as enzymes or receptors. These studies help elucidate mechanisms of action and inform drug design strategies. Techniques such as molecular docking simulations and in vitro assays are commonly employed to assess these interactions.
Several compounds share structural similarities with octahydro-2,6-naphthyridin-1(2H)-one acetate. Below is a comparison highlighting its uniqueness:
| Compound Name | Structure Type | Biological Activity | Notable Features |
|---|---|---|---|
| 1,5-Naphthyridine | Unsubstituted naphthyridine | Antimicrobial | Lacks saturation; more reactive |
| 2-Acetylaminoquinoline | Quinoline derivative | Anticancer | Contains a quinoline core |
| 3-Hydroxyquinoline | Hydroxyquinoline | Antimicrobial | Hydroxyl group enhances solubility |
Octahydro-2,6-naphthyridin-1(2H)-one acetate stands out due to its saturated structure and specific functional groups that confer distinct chemical reactivity and biological properties not found in its more common relatives like 1,5-naphthyridine.
Enamine Cyclization Approaches
Enamine cyclization remains a cornerstone for constructing the bicyclic framework of octahydro-2,6-naphthyridinone derivatives. A modified Skraup reaction, employing m-nitrobenzenesulfonic acid sodium salt (m-NO$$2$$PhSO$$3$$Na) as an oxidant, has been adapted to facilitate the cyclization of aminopyridine precursors. For example, heating 3-aminopyridine derivatives with glycerol and m-NO$$2$$PhSO$$3$$Na in dioxane/water (1:1) yields 1,5-naphthyridine intermediates, which can subsequently undergo hydrogenation to access the saturated octahydro system. This method achieves moderate yields (45–50%) and demonstrates scalability for industrial production.
Phosphine-Catalyzed Annulation Strategies
While phosphine-catalyzed annulations are well-established for constructing nitrogen heterocycles, their application to octahydro-2,6-naphthyridinone acetate remains underexplored. Theoretical frameworks suggest that tributylphosphine could catalyze [4+2] cycloadditions between enamines and α,β-unsaturated carbonyl compounds, forming the bicyclic core. However, experimental validation is limited, highlighting a critical gap in the literature.
Solid-Phase Synthesis Techniques
Solid-phase synthesis offers advantages in purity control and combinatorial library generation. Immobilizing a pyrrolidine precursor on Wang resin enables sequential coupling with keto-esters, followed by cyclative cleavage to release the bicyclic product. This method, though not yet reported for the target compound, aligns with strategies used for analogous piperidine-based systems.
Stereochemical Control and Diastereoselectivity
The octahydro-2,6-naphthyridinone core contains four stereocenters, necessitating precise control during synthesis. Key findings include:
- Catalyst-dependent selectivity: Montmorillonite K10 clay promotes axial selectivity in cyclization steps, favoring the cis-fused bicyclic structure.
- Solvent effects: Polar aprotic solvents (e.g., DMF) enhance diastereoselectivity by stabilizing transition states through hydrogen bonding.
- Temperature modulation: Low-temperature reactions (−20°C) reduce epimerization risks, preserving stereochemical integrity during acetate functionalization.
Combinatorial Chemistry and Diversity-Oriented Synthesis
Combinatorial approaches leverage the compound’s core for generating structurally diverse libraries. Supplier data reveals that 23 commercial variants exist, with modifications at the acetate group (e.g., trifluoroacetate, propionate). Table 1 summarizes available derivatives:
| Supplier | Purity (%) | Quantity (mg) | Price ($) |
|---|---|---|---|
| Angene International | 95 | 50 | 59 |
| BLD Pharmatech | 95 | 100 | 85 |
| Astatech | 95 | 250 | 983 |
Molecular docking represents a cornerstone computational methodology in structure-based drug discovery, serving as the primary technique for predicting and analyzing the binding interactions between small molecule ligands and their target proteins. This approach has gained particular significance in the investigation of Octahydro-2,6-naphthyridin-1(2H)-one acetate and related naphthyridine derivatives, where researchers employ sophisticated algorithms to model the three-dimensional binding conformations and estimate binding affinities with target proteins [1] [2].
The fundamental principle underlying molecular docking involves the systematic exploration of conformational space to identify optimal binding poses between a ligand and its protein target. Contemporary docking algorithms utilize various search strategies, including genetic algorithms, simulated annealing, and Monte Carlo methods, to navigate the complex energy landscape of protein-ligand interactions [1] [3]. For naphthyridine derivatives, studies have demonstrated that molecular docking can effectively predict binding modes with high accuracy, particularly when validated against experimental structures [4] [5].
Scoring Functions and Binding Affinity Prediction
The accuracy of molecular docking studies heavily depends on the quality of scoring functions employed to evaluate and rank different binding poses. Modern docking platforms incorporate multiple scoring schemes, ranging from empirical functions based on experimental binding data to physics-based approaches that calculate interaction energies using force field parameters [6] [7]. Recent developments in machine learning have led to the creation of hybrid scoring functions that combine traditional empirical approaches with data-driven models, significantly improving prediction accuracy [8].
Studies involving naphthyridine derivatives have shown that different scoring functions can yield varying results, necessitating the use of consensus scoring approaches [3]. The binding affinities predicted through molecular docking typically range from -4.0 to -12.0 kilocalories per mole for most drug-like compounds, with more potent inhibitors achieving scores below -10.0 kilocalories per mole [3] [5]. These computational predictions correlate well with experimental binding constants, providing valuable guidance for lead optimization efforts.
Target Protein Preparation and Binding Site Analysis
Successful molecular docking studies require careful preparation of target protein structures, including the addition of hydrogen atoms, optimization of side chain conformations, and identification of appropriate binding sites [1] [2]. For proteins lacking experimental structures, homology modeling techniques are employed to generate suitable templates for docking studies. The quality of these models directly impacts the reliability of subsequent docking results [9] [10].
Binding site identification and characterization represent critical steps in the docking workflow. Computational tools analyze protein surfaces to identify potential druggable cavities, taking into account factors such as cavity volume, hydrophobicity, and accessibility [11]. For naphthyridine derivatives, studies have identified key binding sites on various protein targets, with particular emphasis on active sites containing aromatic residues that can participate in pi-pi stacking interactions [3] [5].
Validation and Experimental Correlation
The validation of molecular docking results requires careful comparison with experimental data, including crystal structures of protein-ligand complexes and biochemical binding assays [12] [13]. Root mean square deviation calculations between predicted and experimental binding poses serve as primary metrics for assessing docking accuracy. Studies have shown that high-quality docking predictions typically achieve root mean square deviation values below 2.0 angstroms [13].
Cross-docking studies, where ligands are docked into multiple protein conformations, provide additional validation of docking protocols [14] [15]. These approaches account for protein flexibility and help identify the most reliable binding predictions. For naphthyridine derivatives, cross-docking studies have revealed the importance of considering multiple protein conformations to capture the full spectrum of possible binding modes [1] [16].
Molecular Dynamics Simulations of Ligand-Receptor Complexes
Molecular dynamics simulations provide a powerful computational framework for investigating the dynamic behavior of protein-ligand complexes at atomic resolution, offering insights that complement and extend the static pictures obtained from molecular docking studies. These simulations are particularly valuable for studying Octahydro-2,6-naphthyridin-1(2H)-one acetate and related compounds, as they reveal the temporal evolution of binding interactions and assess the stability of predicted binding modes [16] [17].
Simulation Setup and Force Field Selection
The establishment of robust molecular dynamics simulation protocols requires careful selection of appropriate force fields and simulation parameters. Contemporary studies employ well-validated force fields such as AMBER, CHARMM, and GROMOS, each offering specific advantages for different types of molecular systems [18] [19]. For protein-ligand complexes involving naphthyridine derivatives, AMBER force fields are frequently employed due to their comprehensive parameterization for both proteins and small organic molecules [16] [20].
Simulation systems typically consist of the protein-ligand complex solvated in explicit water molecules, with the addition of counterions to maintain electroneutrality [17]. The choice of water model, boundary conditions, and system size significantly influences simulation outcomes. Most studies employ cubic periodic boundary conditions with system sizes ranging from 50,000 to 100,000 atoms, providing sufficient buffer space to minimize artifacts from periodic images [16] [20].
Equilibration Protocols and Production Runs
Proper equilibration of molecular dynamics systems requires a multi-stage protocol that gradually relaxes the initial structure while maintaining system integrity [20] [17]. Initial energy minimization removes unfavorable contacts, followed by gradual heating to physiological temperature under constant volume conditions. Subsequent equilibration under constant pressure and temperature conditions allows the system density to adjust to appropriate values [16].
Production simulations for protein-ligand complexes typically extend from 50 to 200 nanoseconds, depending on the research objectives and computational resources available [16] [5]. Longer simulations provide better statistical sampling of conformational states but require greater computational investment. Recent studies of naphthyridine derivatives have employed simulation times ranging from 100 to 500 nanoseconds to achieve adequate sampling of binding site dynamics [3] [5].
Analysis of Binding Stability and Interaction Patterns
Molecular dynamics simulations generate extensive trajectory data that requires systematic analysis to extract meaningful insights about protein-ligand interactions. Root mean square deviation calculations monitor the structural stability of both protein and ligand components throughout the simulation [5] [13]. Values below 2.0 angstroms for protein backbone atoms typically indicate stable binding, while larger deviations may suggest conformational changes or binding instability [13].
Root mean square fluctuation analysis identifies regions of high mobility within the protein structure, revealing how ligand binding affects protein dynamics [5]. Interaction analysis tools track the formation and breaking of specific contacts, including hydrogen bonds, salt bridges, and hydrophobic interactions. For naphthyridine derivatives, these analyses have revealed the importance of maintaining key hydrogen bonding networks for stable binding [3] [5].
Free Energy Calculations and Binding Affinity Prediction
Advanced molecular dynamics techniques enable the calculation of binding free energies, providing quantitative predictions of ligand affinity that can be directly compared with experimental measurements [20] [21]. Methods such as free energy perturbation, thermodynamic integration, and umbrella sampling have been successfully applied to naphthyridine-containing systems [20].
These calculations require extensive sampling and careful attention to convergence criteria, but they offer the most rigorous computational approach for predicting binding affinities [12]. Recent studies have achieved prediction accuracies within 1-2 kilocalories per mole of experimental values, making these methods increasingly valuable for lead optimization efforts [21] [22].
Homology Modeling for Target Structure Prediction
Homology modeling, also known as comparative modeling, represents an essential computational technique for predicting three-dimensional protein structures when experimental structures are unavailable. This approach is particularly crucial for drug discovery efforts targeting Octahydro-2,6-naphthyridin-1(2H)-one acetate, as many potential protein targets lack high-resolution experimental structures [9] [23].
Template Selection and Sequence Alignment
The foundation of successful homology modeling lies in the identification of appropriate template structures that share significant sequence similarity with the target protein. Modern template search algorithms employ position-specific scoring matrices and profile-based methods to identify remote homologs that may not be detected by simple sequence comparison [9] [24]. For drug discovery applications, template structures with sequence identities above 30% typically provide models of sufficient quality for molecular docking studies [23] [24].
Multiple template approaches have gained prominence as a strategy for improving model quality by combining structural information from several related proteins [24] [25]. These methods are particularly valuable when no single template provides complete coverage of the target sequence or when different templates excel in modeling different structural regions. The selection of optimal template combinations requires careful consideration of sequence coverage, structural quality, and functional relevance [24].
Model Building and Refinement Protocols
Contemporary homology modeling employs sophisticated algorithms that satisfy spatial restraints derived from template structures while accommodating sequence differences between target and template [9] [10]. Leading modeling packages such as MODELLER, Swiss-Model, and I-TASSER incorporate advanced techniques for handling insertions, deletions, and conformational differences [26] [27].
Loop modeling represents a particular challenge in homology modeling, as these regions often exhibit low sequence conservation and high structural variability [9] [23]. Specialized algorithms employ ab initio folding approaches or database searching methods to predict loop conformations that are consistent with the overall protein fold [10]. For drug discovery applications, accurate loop modeling is crucial when binding sites involve loop regions that may interact with ligands [9].
Validation and Quality Assessment
Rigorous validation of homology models requires multiple complementary approaches to assess structural quality and reliability [9] [24]. Stereochemical validation examines local geometry using tools such as PROCHECK and MolProbity, which analyze bond lengths, angles, and torsional angles [23]. Global fold assessment employs energy-based methods that evaluate the compatibility of amino acid sequences with predicted three-dimensional structures [9].
Statistical validation compares model features with distributions observed in high-quality experimental structures [23] [24]. Key metrics include Ramachandran plot analysis, which should show greater than 90% of residues in favored regions, and overall geometry quality scores [9]. Additional validation may involve comparison with experimental data such as nuclear magnetic resonance chemical shift data or limited proteolysis patterns [10].
Applications in Structure-Based Drug Design
Homology models serve as valuable starting points for structure-based drug discovery efforts, particularly when combined with molecular docking and virtual screening approaches [9] [28]. However, the limited accuracy of homology models compared to experimental structures necessitates careful consideration of model quality when interpreting docking results [29].
Recent advances in artificial intelligence-based structure prediction, exemplified by AlphaFold, have dramatically expanded the availability of high-quality protein structure models [28] [29]. These developments are revolutionizing drug discovery by making previously inaccessible targets amenable to structure-based approaches. For naphthyridine derivatives and similar compounds, improved structure prediction capabilities enable more comprehensive exploration of potential target space [28].
The integration of homology modeling with experimental validation represents a powerful approach for drug discovery [9] [27]. Computational predictions guide the design of biochemical assays and mutagenesis experiments, while experimental results provide feedback for model refinement. This iterative process has proven particularly effective for optimizing ligand selectivity and understanding structure-activity relationships [10] [30].
| Software | Scoring Function | Application | Typical Binding Affinity Range (kcal/mol) | Key Features |
|---|---|---|---|---|
| AutoDock Vina | Vina Score | General purpose docking | -4.0 to -12.0 | Fast and accurate |
| GOLD | GoldScore/ChemScore | Fragment-based design | -30 to -80 | Multiple scoring options |
| Glide | GlideScore | High-precision docking | -6.0 to -14.0 | Induced fit capability |
| AutoDock 4.2 | Lamarckian GA | Classical GA optimization | -4.0 to -12.0 | Genetic algorithm based |
| Discovery Studio | LibDock/CDOCKER | Commercial suite | -5.0 to -15.0 | Integrated workflow |
| FlexX | FlexX Score | Fragment placement | -8.0 to -25.0 | Fragment-based approach |
| Parameter | Typical Values | Purpose | Software |
|---|---|---|---|
| Simulation Time | 50-200 ns | System equilibration | NAMD/GROMACS/AMBER |
| Time Step | 1-2 fs | Integration stability | All MD packages |
| Temperature | 300 K | Physiological conditions | Thermostat control |
| Pressure | 1 atm | Standard conditions | Barostat control |
| Force Field | AMBER99SB/CHARMM36 | Protein parameterization | Parameter files |
| Water Model | TIP3P/TIP4P | Solvent modeling | Built-in models |
| Salt Concentration | 0.15 M NaCl | Ionic strength | Ion placement |
| Ensemble | NPT | Constant P,T conditions | Simulation control |
| Step | Method/Tool | Key Criteria | Validation Metric | Quality Threshold |
|---|---|---|---|---|
| Template Selection | BLAST/PSI-BLAST | Sequence identity >30% | E-value < 10^-5 | High homology |
| Sequence Alignment | CLUSTALW/MUSCLE | Gap minimization | Alignment score | Minimal gaps |
| Model Building | MODELLER/Swiss-Model | Spatial restraints | DOPE score | Low energy |
| Loop Modeling | ModLoop/LOOPY | Conformational sampling | Loop RMSD | <2.0 Å RMSD |
| Side Chain Optimization | SCWRL/Chimera | Rotamer libraries | Chi-angle deviations | <15° deviation |
| Model Validation | PROCHECK/SAVES | Stereochemical quality | Ramachandran plot | >90% favored regions |
| Interaction Type | Typical Distance (Å) | Energy Contribution (kcal/mol) | Frequency in Naphthyridine Complexes (%) | Key Residues |
|---|---|---|---|---|
| Hydrogen Bonds | 2.5-3.5 | -1.0 to -3.0 | 85-95 | Ser, Thr, Asn, Gln |
| Pi-Pi Stacking | 3.5-4.5 | -2.0 to -4.0 | 60-75 | Phe, Trp, Tyr, His |
| Hydrophobic Contacts | 4.0-5.0 | -0.5 to -2.0 | 90-100 | Leu, Ile, Val, Ala |
| Salt Bridges | 2.8-4.0 | -5.0 to -8.0 | 15-30 | Asp, Glu, Arg, Lys |
| Van der Waals | 3.0-4.5 | -0.2 to -1.0 | 100 | All residues |
| Metal Coordination | 2.0-2.5 | -10.0 to -20.0 | 5-15 | His, Cys, Met |
Hydrogen Bond Acceptor Count
Hydrogen Bond Donor Count
Exact Mass
Monoisotopic Mass
Heavy Atom Count
Dates
Explore Compound Types