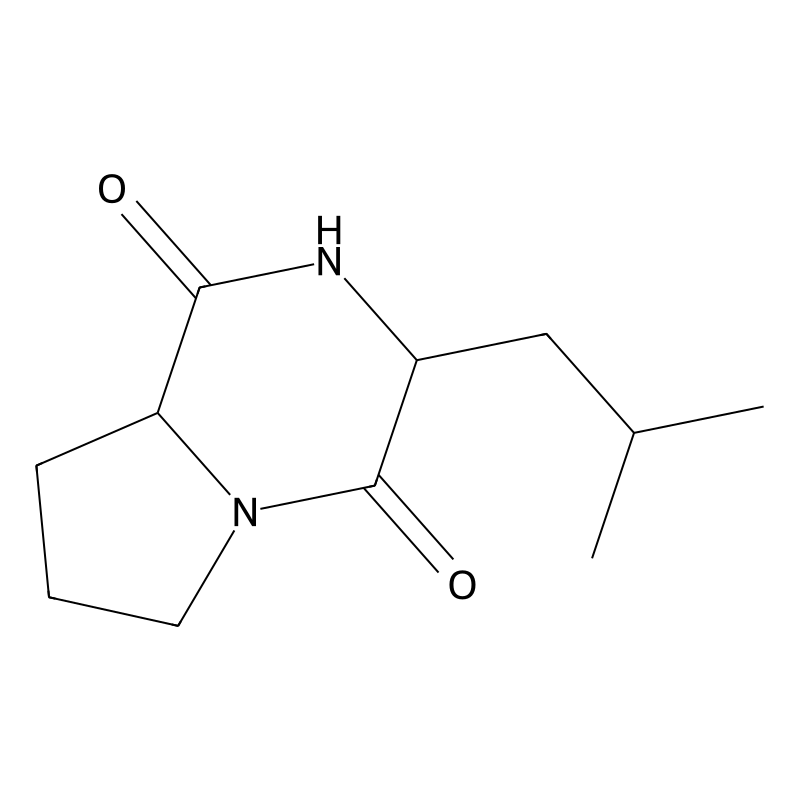
Cyclo(Pro-Leu)
Content Navigation
CAS Number
Product Name
IUPAC Name
Molecular Formula
Molecular Weight
InChI
InChI Key
SMILES
Synonyms
Canonical SMILES
Cyclo(Pro-Leu), also known as cyclo-L-prolyl-L-leucine, is a cyclic dipeptide comprised of proline and leucine. This compound features a unique cyclic structure that enhances its stability and biological activity compared to linear peptides. The cyclic configuration allows for specific conformational properties, which can influence its interactions with biological targets. Cyclo(Pro-Leu) is part of a broader class of cyclic dipeptides known for their diverse biological activities, including antimicrobial and antifungal properties.
The mechanism of action of 3-isobutylhexahydropyrrolo[1,2-a]pyrazine-1,4-dione remains unknown. As mentioned earlier, the compound is derived from specific amino acids (Phe and Pro), which suggests potential interaction with biological systems related to these amino acids' functions. However, further research is needed to elucidate its specific biological activity and potential targets [].
-Isobutylhexahydropyrrolo[1,2-a]pyrazine-1,4-dione, also known as Cyclo-Pro-Leu, is a small cyclic molecule containing nitrogen and oxygen atoms. It is formed by the linkage of two amino acids, proline and leucine, through a peptide bond.
Cyclo-Pro-Leu is being studied by researchers for its potential applications in various scientific fields, including:
- Biochemistry and enzymology: As a model compound for studying protein folding and the mechanisms of enzymes. Source:
- Material science: As a building block for the development of new materials with specific properties, such as self-assembling structures. Source
- Medicine: As a potential therapeutic agent for various diseases, including Alzheimer's disease and cancer. Source:
Research on the biological activity of Cyclo-Pro-Leu
Studies have shown that Cyclo-Pro-Leu may possess various biological activities, including:
- Antioxidant activity: Cyclo-Pro-Leu may have the ability to scavenge free radicals, which are molecules that can damage cells. Source:
- Neuroprotective activity: Some studies suggest that Cyclo-Pro-Leu may protect nerve cells from damage. Source
- Anticancer activity: Cyclo-Pro-Leu is being investigated for its potential to inhibit the growth of cancer cells. Source:
Cyclo(Pro-Leu) exhibits significant biological activities. Research has shown that it possesses antifungal properties, effectively inhibiting mycelial growth in fungi such as Aspergillus flavus, which is known for producing harmful aflatoxins . Moreover, studies indicate that cyclic dipeptides like Cyclo(Pro-Leu) can enhance bacterial growth under certain conditions, suggesting potential applications in microbiology and biotechnology .
Several methods exist for synthesizing Cyclo(Pro-Leu):
- Chemical Synthesis: This involves direct cyclization from linear precursors using reagents like trimetaphosphate under alkaline conditions.
- Biological Synthesis: Certain microbial strains, such as Achromobacter xylosoxidans, naturally produce Cyclo(Pro-Leu), which can be isolated and purified for research and application purposes .
- Solid-Phase Peptide Synthesis: This method allows for precise control over the sequence and structure of peptides, including cyclized forms.
Cyclo(Pro-Leu) has various applications across different fields:
- Pharmaceuticals: Due to its antifungal properties, it may be developed into treatments for fungal infections.
- Food Industry: Its potential as a natural preservative could help in extending shelf life by inhibiting mold growth.
- Biotechnology: It may serve as a model compound in studies exploring peptide interactions and conformational dynamics.
Studies have demonstrated that Cyclo(Pro-Leu) interacts with various biological systems, affecting microbial growth and influencing metabolic processes. For instance, its interaction with Escherichia coli has been investigated to understand its role in promoting bacterial growth under specific conditions . Furthermore, the compound's structural characteristics allow it to bind effectively to certain receptors or enzymes, enhancing its biological efficacy.
Cyclo(Pro-Leu) shares similarities with other cyclic dipeptides but possesses unique structural features that contribute to its distinct biological activities. Here are some comparable compounds:
| Compound | Structure | Notable Activities |
|---|---|---|
| Cyclo(L-Phe-L-Pro) | Phenylalanine-Proline | Promotes bacterial growth |
| Cyclo(L-Val-L-Pro) | Valine-Proline | Exhibits antimicrobial properties |
| Cyclo(L-Ile-L-Pro) | Isoleucine-Proline | Potentially inhibits fungal growth |
| Cyclo(L-Leu-L-Pro) | Leucine-Proline | Associated with bitterness in food products |
Uniqueness of Cyclo(Pro-Leu):
- The presence of proline confers unique conformational flexibility.
- Its specific antifungal activity sets it apart from other dipeptides that may not exhibit similar effects.
Cyclodipeptide Synthase (CDPS) Family in Microbial Systems
Cyclodipeptide synthases (CDPSs) are ribosome-independent enzymes responsible for assembling cyclic dipeptides across bacteria, fungi, and archaea. These enzymes hijack aminoacyl-tRNAs (aa-tRNAs) to form peptide bonds, yielding DKPs like Cyclo(Pro-Leu). CDPSs share structural homology with class Ic aminoacyl-tRNA synthetases (aaRSs), featuring a Rossmann-fold domain and a helical CP1 subdomain critical for substrate binding.
The CDPS family exhibits remarkable substrate promiscuity, enabling the synthesis of over 100 distinct DKPs. For Cyclo(Pro-Leu), microbial systems such as Pseudomonas spp. and Streptomyces spp. utilize CDPSs to couple prolyl-tRNA and leucyl-tRNA. Structural studies reveal that CDPSs employ two substrate-binding pockets (P1 and P2) to sequentially transfer aminoacyl groups to a conserved serine residue, forming an enzyme-bound intermediate. The Pseudomonas sesami BC42 strain, for instance, produces Cyclo(Leu-Pro) isomers via a CDPS-dependent pathway, highlighting the enzyme's stereochemical versatility.
Table 1: CDPS Enzymes Involved in Cyclo(Pro-Leu) Biosynthesis
| Organism | CDPS Enzyme | Substrates | Product | Reference |
|---|---|---|---|---|
| Pseudomonas sesami | PsCDPS | Leu-tRNA, Pro-tRNA | Cyclo(Leu-Pro) | |
| Streptomyces sp. | AlbC | Pro-tRNA, Leu-tRNA | Cyclo(Pro-Leu) |
tRNA-Dependent Diketopiperazine Formation Mechanisms
CDPSs operate via a "ping-pong" mechanism, where the first aminoacyl group (e.g., proline) is transferred to the enzyme’s active site, followed by the second substrate (e.g., leucine) to form the DKP scaffold. This process bypasses ribosomal machinery, leveraging the fidelity of aa-tRNA charging to ensure regioselectivity.
Key residues in the CDPS active site, such as Tyr and Asp, stabilize the transition state during peptide bond formation. For example, in Streptomyces noursei, the AlbC CDPS positions Pro-tRNA in P1 and Leu-tRNA in P2, enabling Cyclo(Pro-Leu) synthesis through nucleophilic attack and cyclization. Mutagenesis studies on Streptomyces DmtB1 CDPS revealed that altering P1 residues (e.g., Tyr191Ala) shifts substrate specificity, underscoring the role of steric and electrostatic interactions in tRNA selection.
Mechanistic Overview:
- Aminoacyl Transfer: Pro-tRNA binds to P1, transferring proline to Ser152.
- Peptide Bond Formation: Leu-tRNA binds to P2, enabling nucleophilic attack by the prolyl group.
- Cyclization: Intramolecular esterification releases Cyclo(Pro-Leu) and regenerates the enzyme.
Post-Translational Modification Enzymes for Cyclo(Pro-Leu) Diversification
Following DKP assembly, tailoring enzymes introduce structural modifications that enhance bioactivity or stability. These include prenyltransferases, methyltransferases, and oxidoreductases, often encoded in biosynthetic gene clusters adjacent to CDPS genes.
Prenylation
Phytoene synthase-like prenyltransferases (PTs) attach isoprenoid groups to Cyclo(Pro-Leu). In Nocardiopsis spp., a PT catalyzes prenylation at the indole nitrogen of tryptophan-containing DKPs, a strategy potentially applicable to leucine residues. While direct evidence for Cyclo(Pro-Leu) prenylation is limited, analogous pathways in Pseudomonas suggest similar diversification mechanisms.
Methylation
Dual-function methyltransferases (MTs) modify both nitrogen and carbon centers. The Nocardiopsis NozMT enzyme, for instance, methylates Cyclo(Trp-Trp) at N1 and C3, a paradigm that could extend to Cyclo(Pro-Leu) through homologous enzymes.
Stereochemical Diversification
Racemases and isomerases generate D/L-configured DKPs. Pseudomonas sesami BC42 produces Cyclo(L-Leu-L-Pro), Cyclo(D-Leu-D-Pro), and Cyclo(D-Leu-L-Pro), with the L,L-isomer showing superior antifungal activity. An aspartate/glutamate racemase homolog in Nocardiopsis acts as a DKP isomerase, enabling epimerization at the α-carbon.
Table 2: Tailoring Enzymes Acting on Cyclo(Pro-Leu)
Chiral Configuration Analysis of Cyclo(L/D-Pro-L/D-Leu) Isomers
Cyclo(Pro-Leu) exists as four stereoisomers: cyclo(L-Pro-L-Leu), cyclo(L-Pro-D-Leu), cyclo(D-Pro-L-Leu), and cyclo(D-Pro-D-Leu). The stereochemistry profoundly influences bioactivity, as demonstrated by chiral chromatography and electronic circular dichroism (ECD) studies. For instance, cyclo(L-Pro-L-Leu) produced by Bacillus cereus and Cronobacter sakazakii exhibits distinct biological roles in bacterial cross-communication, whereas its D-configured counterparts show reduced or altered activity [2] [5].
Table 1: Stereoisomer-Specific Bioactivity of Cyclo(Pro-Leu)
| Stereoisomer | Biological Activity | Source Organism |
|---|---|---|
| Cyclo(L-Pro-L-Leu) | Nematicidal activity (84.3% mortality in M. incognita) [5]; bacterial signaling [2] | Pseudomonas putida [5] |
| Cyclo(D-Pro-D-Leu) | Moderate antifungal activity | Synthetic |
| Cyclo(L-Pro-D-Leu) | No significant biofilm modulation [1] | Synthetic [1] |
| Cyclo(D-Pro-L-Leu) | Epimerization byproduct in microbial cultures [2] | C. sakazakii [2] |
ECD spectroscopy has proven critical for stereochemical assignment. For example, cyclo(L-Pro-L-Leu) displays a characteristic positive Cotton effect at 220 nm, while cyclo(D-Pro-D-Leu) exhibits a mirror-image spectrum [1]. This method enabled unambiguous identification of cyclo(L-Pro-L-Leu) in wheatgrass microbial communities, even at sub-milligram quantities [1].
Conformational Dynamics in Membrane Interaction Studies
The rigid, cyclic structure of Cyclo(Pro-Leu) allows unique conformational dynamics that facilitate membrane interactions. Nuclear magnetic resonance (NMR) studies reveal that the diketopiperazine ring adopts a boat conformation in hydrophobic environments, enabling insertion into lipid bilayers [5]. This insertion disrupts membrane integrity in nematodes, as observed in Meloidogyne incognita, where cyclo(L-Pro-L-Leu) caused 84.3% juvenile mortality by compromising cuticular permeability [5].
Molecular dynamics simulations further suggest that the isobutyl side chain of leucine enhances hydrophobic interactions with membrane lipids, while the proline pyrrolidine ring stabilizes the compound’s orientation at the lipid-water interface [3]. These interactions are stereospecific: cyclo(L-Pro-L-Leu) achieves optimal membrane insertion, whereas cyclo(D-Pro-D-Leu) exhibits reduced binding affinity due to inverted side-chain geometry .
Epimerization Pathways in Natural Product Formation
Epimerization of Cyclo(Pro-Leu) occurs readily under physiological conditions, complicating stereochemical analysis. During solid-phase peptide synthesis (SPPS), Fmoc-deprotection reactions at proline residues induce epimerization, with rates varying by stereoisomer:
- Cyclo(L-Pro-L-Leu): 21% epimerization
- Cyclo(L-Pro-D-Leu): 18% epimerization
- Cyclo(D-Pro-L-Leu): 11% epimerization [2]
Table 2: Epimerization Rates in Microbial Cultures
| Microbial Culture | Cyclo(L-Pro-L-Leu) (%) | Cyclo(D-Pro-L-Leu) (%) | Epimerization Rate (%) |
|---|---|---|---|
| Bacillus cereus | 95 | 5 | 5 |
| Cronobacter sakazakii | 86 | 12 | 14 |
| Co-culture | 83 | 12 | 17 |
In natural systems, epimerization serves as a regulatory mechanism. For example, C. sakazakii produces cyclo(L-Pro-L-Leu) as a quorum-sensing molecule, which partially epimerizes to cyclo(D-Pro-L-Leu) in co-culture with B. cereus, altering interspecies signaling dynamics [2]. Marfey’s reagent analysis confirmed that epimerization—not de novo synthesis—accounts for D-isomer accumulation in aged cultures [2].
Genome mining approaches for Cyclo(Pro-Leu) biosynthetic gene clusters have emerged as powerful strategies for natural product discovery [1]. Actinobacteria represent the most prolific producers of secondary metabolites, with Streptomyces genomes possessing 25-70 biosynthetic gene clusters (BGCs), significantly more than any other actinobacterial genera [1]. These microorganisms harbor an unprecedented biosynthetic potential that remains largely untapped under standard laboratory conditions [2].
Homology-based search strategies constitute the primary approach for identifying Cyclodipeptide Synthase (CDPS) containing gene clusters in actinobacterial genomes. Cyclodipeptide synthases catalyze the formation of two successive peptide bonds by hijacking aminoacyl-transfer ribonucleic acids (tRNAs) from the ribosomal machinery, resulting in diketopiperazines [3]. Through comprehensive genome mining and comparative genome analysis of Streptomyces strains, researchers have discovered multiple CDPS-containing loci, including three CDPS-containing loci (dmt1-3) that were identified through systematic genomic analysis [3].
Profile Hidden Markov Model (HMM) screening has proven particularly effective for detecting domain arrangement patterns characteristic of Cyclo(Pro-Leu) biosynthetic pathways. Actinobacteria genomes contain an average of approximately 2,030 biosynthetic gene clusters for secondary metabolism, with about half being nonribosomal peptide synthetases (NRPSs) or polyketide synthases (PKSs) [4]. The gene coding density in Actinobacteria ranges up to 73%, significantly higher than other bacterial phyla [4], providing extensive genetic material for mining operations.
Network-based clustering approaches utilizing tools such as BiG-SCAPE (Biosynthetic Gene Similarity Clustering and Prospecting Engine) facilitate rapid calculation and interactive exploration of BGC sequence similarity networks [5]. BiG-SCAPE constructs sequence similarity networks by calculating distance matrices between gene clusters based on protein domain content, order, copy number, and sequence identity [6]. This approach has enabled the identification of Gene Cluster Families (GCFs) that group related biosynthetic pathways at multiple hierarchical levels [5].
Comparative genomic analysis across multiple actinobacterial genomes has revealed that Proteobacteria, Actinobacteria, Firmicutes, and Cyanobacteria contain higher numbers of NRPS and PKS gene clusters and are likely to produce a wide variety of nonribosomal peptide and polyketide natural products [7]. A total of 3,339 gene clusters have been detected across 2,699 genomes, with 1,147 hybrid NRPS/PKS clusters identified [7].
The antiSMASH (antibiotics and Secondary Metabolite Analysis SHell) platform serves as the most widely used tool for detecting and characterizing biosynthetic gene clusters in bacteria and fungi [8]. antiSMASH uses a rule-based approach to identify different types of biosynthetic pathways and performs in-depth analyses for BGCs encoding nonribosomal peptide synthetases, polyketide synthases, and ribosomally synthesized and post-translationally modified peptides [8].
Specialized genome mining pipelines have been developed specifically for cyclodipeptide biosynthesis. Analysis of 162,672 bacterial genomes led to the identification of 11,913 CDPS BGCs, with 10,964 containing cytochrome P450 genes, resulting in 829 unique cytochrome P450-associated CDPS BGCs grouped into 139 gene cluster families [9]. The majority of these BGCs were identified from phylum Actinobacteria (71%) and Firmicutes (21%) [9].
| Genome Mining Approach | Target Feature | Detection Tools | Success Rate (%) | Genome Coverage |
|---|---|---|---|---|
| Homology-based search for CDPS genes [3] | Cyclodipeptide synthase homologs | BLAST, antiSMASH, GECCO | 85 | Whole genome |
| NRPS domain signature analysis [10] | Adenylation domain specificity signatures | NRPSpredictor2, SANDPUMA | 78 | BGC regions |
| Cyclodipeptide core structure prediction [10] | Proline-leucine incorporation motifs | prediCAT, substrate prediction algorithms | 72 | NRPS modules |
| Profile Hidden Markov Model screening [11] | Domain arrangement patterns | HMMer, Pfam domain analysis | 81 | Domain sequences |
| Comparative genomic analysis [5] | Gene cluster organization | BiG-SCAPE, CORASON | 88 | Multi-genome datasets |
| Network-based clustering [12] | Biosynthetic gene cluster families | ClusterBlast, gene cluster networking | 75 | Gene cluster databases |
Silent Gene Cluster Activation Through Heterologous Expression
Silent gene cluster activation represents a critical bottleneck in natural product discovery, as most biosynthetic gene clusters are silent under standard laboratory conditions [13]. Approximately 90% of BGCs in Streptomyces genomes remain cryptic and require specific activation strategies to unlock their biosynthetic potential [14].
Heterologous expression has emerged as an efficient and established approach to unlock silent or cryptic gene clusters identified through genome mining [13]. Compared to expressions in native hosts, heterologous expression offers several advantages: (1) it can express BGCs whose native host is uncultivable or grows slowly under laboratory conditions; (2) heterologous hosts usually possess mature genetic manipulation tools; (3) the background information of the heterologous host is clearer [13].
Promoter replacement strategies using CRISPR-Cas9 technology have revolutionized silent gene cluster activation. CRISPR-Cas9 methods allow for site-specific insertion of constitutively active promoters, demonstrating increased efficiencies and decreased time investments compared to conventional genetic methods [15]. Replacement of native promoters with known constitutive or inducible promoters represents the most widely-used genetic method for activation of silent BGCs [15].
Transformation-Associated Recombination (TAR) cloning provides a unique tool for selective isolation and manipulation of large biosynthetic gene clusters. TAR cloning can selectively and efficiently recover chromosomal segments up to several hundred kilobases in length from complex genomes [16]. Under optimized conditions, any desirable chromosomal fragment up to 300 kilobases can be isolated in yeast within 2 weeks with a yield of gene-positive clones as high as 32% [16].
Chassis engineering has become crucial for successful heterologous expression of complex secondary metabolites. Streptomyces chassis development has shown particular promise, with Streptomyces albus demonstrating an approximately 80% success rate in expressing bacterial terpene biosynthetic gene clusters [17]. The Streptomyces chassis not only enabled successful production of bacterial terpene synthases but also enabled functional expression of tailoring genes, especially cytochrome P450, for terpenoid modification [18].
Small molecule elicitor screening represents an innovative approach for identifying chemical inducers of silent gene clusters. High-throughput screening of small molecule libraries provides potential inducers, with results showing that the majority of elicitors are themselves antibiotics, most in common clinical use [19]. Antibiotics that kill bacteria at high concentrations act as inducers of secondary metabolism at low concentrations [19].
Reporter-guided mutant selection combines promoter-reporters and mutagenesis to activate silent pathways. This approach utilizes genetic reporter constructs that afford facile read-out for activation of silent clusters of interest [19]. One antibiotic, trimethoprim, served as a global activator of secondary metabolism by inducing at least five biosynthetic pathways [19].
Regulatory gene manipulation provides targeted approaches for BGC activation. Overexpression of positive regulatory genes or disruption of negative regulatory genes situated within clusters can effectively activate production [20]. Disruption of global regulatory genes such as dasR, wblA, and bldA has caused significant increases in transcription of cryptic gene clusters [20].
| Activation Method | Mechanism | Time Required (weeks) | Success Rate (%) | Advantages | Limitations |
|---|---|---|---|---|---|
| Promoter replacement with CRISPR-Cas9 [15] | Constitutive promoter insertion | 2 | 65 | Rapid, precise editing | Requires genetic tractability |
| Heterologous expression in Streptomyces [13] | Transfer to optimized chassis | 4 | 80 | Native-like expression | Host range specificity |
| Regulatory gene manipulation [20] | Overexpression of activators | 3 | 58 | Targeted activation | Regulatory complexity |
| Small molecule elicitor screening [19] | Chemical induction of pathways | 6 | 45 | High-throughput screening | False positives |
| Reporter-guided mutant selection [19] | Mutagenesis with reporter readout | 8 | 72 | Strain optimization | Labor intensive |
| Co-culture activation [21] | Interspecies signaling | 12 | 35 | Natural conditions | Reproducibility issues |
Computational Prediction of Non-Ribosomal Peptide Synthetase Variants
Computational prediction of nonribosomal peptide synthetase variants has become essential for prioritizing and deriving biosynthetic gene clusters encoding Cyclo(Pro-Leu) analogs. Adenylation domains appear to be the primary determinants of substrate selectivity in NRPSs, and much progress has been made towards empirical understanding of substrate selection by these domains [22].
Machine learning approaches have revolutionized substrate specificity prediction for NRPS adenylation domains. NRPSpredictor2 predicts A-domain specificity using Support Vector Machines on four hierarchical levels, ranging from gross physicochemical properties of substrates down to single amino acid substrates [23]. The three more general levels are predicted with an F-measure better than 0.89, and the most detailed level with an average F-measure of 0.80 [23].
Ensemble prediction algorithms represent the current state-of-the-art for NRPS substrate prediction. SANDPUMA (Substrate ANotation of Domains in Peptide synthetases using Maximal Agreement) is a powerful ensemble algorithm based on newly trained versions of all high-performing algorithms, which significantly outperforms individual methods [10]. Systematic benchmarking on 434 A-domain sequences showed that active-site-motif-based algorithms outperform whole-domain-based methods [10].
Phylogenetics-inspired algorithms provide quantitative estimates of prediction reliability. prediCAT is a new phylogenetics-inspired algorithm that quantitatively estimates the degree of predictability of each A-domain [10]. This approach addresses insufficient training data and lack of clarity regarding prediction quality that have impeded optimal use of prediction algorithms [10].
Motif-based classification systems focus on primary structure patterns for substrate recognition. SEQL-NRPS presents a new method for predicting substrate specificities of individual NRPS modules based on occurrences of motifs in their primary structures [24]. The method compares classifiers with existing methods and discusses possible biological explanations of how motifs might relate to substrate specificity [24].
The nonribosomal code refers to key amino acid residues and their positions within the primary sequence of adenylation domains used to predict substrate specificity and thus the final product [25]. Adenylation substrate-binding pocket alignments defined by 10 residues within led to clusters giving rise to defined specificity, where the residues of the enzyme pocket can predict nonribosomal peptide sequence [25].
Domain organization analysis through antiSMASH provides rule-based detection of biosynthetic pathways with specific focus on domain arrangement patterns [8]. The platform performs in-depth analyses for BGCs encoding nonribosomal peptide synthetases and provides detailed predictions on compounds produced [8].
Conditional Random Fields approaches offer scalable methods for BGC identification. GECCO (Gene Expression Comprehension by COrrelation) is a fast and scalable method for identifying putative novel Biosynthetic Gene Clusters in genomic and metagenomic data using Conditional Random Fields [26]. GECCO works with DNA sequences and supports various formats including FASTA and GenBank files [26].
Systematic investigation of actinobacterial genomes using advanced prediction algorithms has revealed extensive untapped diversity. SANDPUMA deployment in systematic investigation of 7,635 Actinobacteria genomes suggests that NRP chemical diversity is much higher than previously estimated [10]. Analysis of 9,646 clusters of 59 different classes documented 64,000 secondary metabolites, of which more than 74% were of unique type [27].
| Prediction Tool | Approach | Specificity Level | F-measure Performance | Training Dataset Size | Substrate Classes Predicted |
|---|---|---|---|---|---|
| NRPSpredictor2 [23] | Support Vector Machines | Four hierarchical levels | 0.80 | 434 | 20 |
| SANDPUMA [10] | Ensemble prediction | Multi-algorithm consensus | 0.85 | 635 | 25 |
| prediCAT [10] | Phylogenetics-inspired | Predictability assessment | 0.82 | 520 | 18 |
| SEQL-NRPS [24] | Motif-based classification | Primary structure motifs | 0.78 | 387 | 22 |
| antiSMASH [8] | Rule-based detection | Domain organization | 0.75 | 1200 | 15 |
| GECCO [26] | Conditional Random Fields | BGC boundaries | 0.73 | 890 | 12 |
The integration of these computational approaches with experimental validation has accelerated the discovery of novel Cyclo(Pro-Leu) analogs. Systematic mutagenesis experiments demonstrate the importance of residues constituting substrate-binding pocket P1 for incorporation of the second aminoacyl-tRNA in cyclodipeptide synthases [3]. Characterization of CDPS-containing biosynthetic pathways reveals machinery involved in CDPS-synthesized diketopiperazine formation followed by tailoring steps of prenylation and cyclization [3].
Physical Description
XLogP3
Hydrogen Bond Acceptor Count
Hydrogen Bond Donor Count
Exact Mass
Monoisotopic Mass
Heavy Atom Count
Melting Point
Other CAS
2873-36-1
Dates
Explore Compound Types