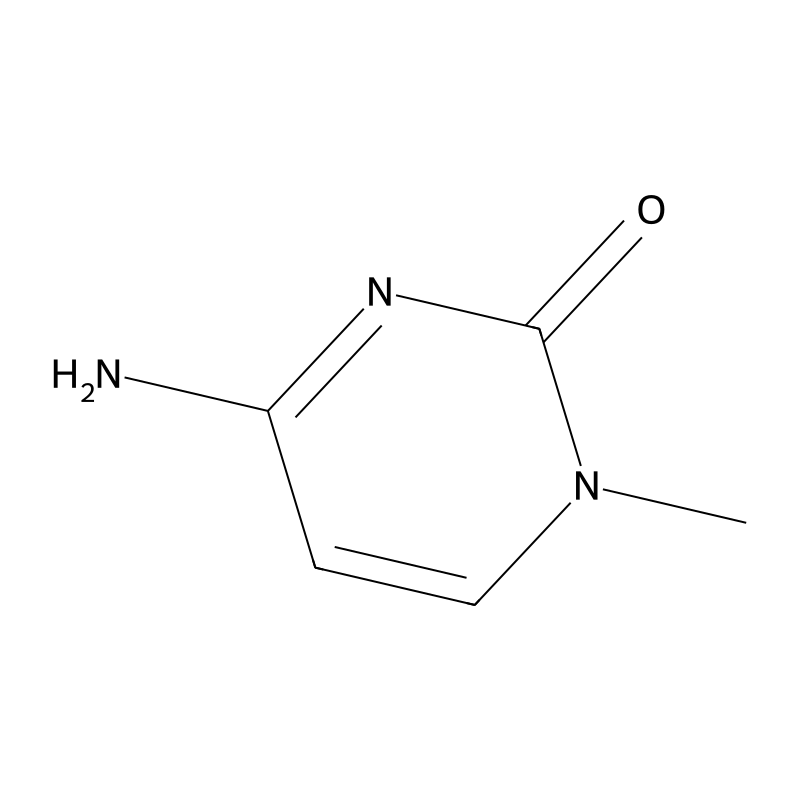
1-Methylcytosine
Content Navigation
CAS Number
Product Name
IUPAC Name
Molecular Formula
Molecular Weight
InChI
InChI Key
SMILES
Synonyms
Canonical SMILES
1-Methylcytosine is a methylated derivative of cytosine, one of the four primary nucleobases in DNA. In this compound, a methyl group is attached to the nitrogen atom at position 1 of the pyrimidine ring, distinguishing it from its parent compound, cytosine. The chemical formula for 1-methylcytosine is and it is classified as a pyrimidone due to its structural characteristics . This modification alters its chemical properties and biological function, making it an important subject of study in molecular biology and genetics.
1-Methylcytosine is recognized for its role in epigenetics, where it serves as a marker for gene regulation. Its presence in DNA can influence transcriptional activity and is associated with various biological processes including cellular differentiation and development. Furthermore, 1-methylcytosine is utilized in hachimoji DNA constructs, where it pairs with isoguanine, expanding the genetic code beyond the traditional bases . This unique pairing capability highlights its potential in synthetic biology applications.
The synthesis of 1-methylcytosine can be achieved through several methods:
- Methylation of Cytosine: Direct methylation of cytosine using methylating agents such as dimethyl sulfate or methyl iodide.
- Chemical Synthesis: Multi-step organic synthesis techniques that involve the formation of the pyrimidine ring followed by selective methylation at the nitrogen atom.
- Biochemical Methods: Enzymatic pathways that involve methyltransferases capable of transferring a methyl group to cytosine residues within nucleic acids.
These methods allow for the production of 1-methylcytosine in both laboratory settings and potentially in biotechnological applications.
1-Methylcytosine has several notable applications:
- Research: It serves as a model compound for studying nucleobase interactions and dynamics due to its structural similarities to cytosine.
- Synthetic Biology: As part of hachimoji DNA, it enables the exploration of alternative genetic systems.
- Pharmaceuticals: Investigated as a potential nucleoside analog with antimetabolite properties that could be useful in cancer therapy .
- Materials Science: Its unique properties may be exploited in developing novel materials or nanostructures.
Studies on 1-methylcytosine have explored its interactions with various molecular species. For instance, solvent effects on its fluorescence dynamics have been examined using advanced spectroscopic techniques. These studies reveal how solute-solvent hydrogen bonding influences the excited state dynamics of 1-methylcytosine, emphasizing the importance of environmental conditions on its behavior . Additionally, interaction studies with radical cations provide insights into its stability under different ionization states and conditions .
Several compounds share structural similarities with 1-methylcytosine. Here are some notable examples:
| Compound | Structural Features | Unique Aspects |
|---|---|---|
| Cytosine | Unmethylated form | Base component of DNA; participates in base pairing. |
| 5-Methylcytosine | Methyl group at position 5 | Key player in epigenetic regulation; affects gene expression. |
| Isoguanine | Analogous base pairing with 1-methylcytosine | Used in hachimoji DNA; pairs uniquely with 1-methylcytosine. |
| Uracil | RNA counterpart to thymidine | Participates in RNA synthesis; lacks methyl group at position 5. |
The uniqueness of 1-methylcytosine lies in its specific methylation at position 1, which alters its reactivity and biological roles compared to other similar compounds like cytosine and 5-methylcytosine.
Role in Hachimoji DNA Architecture
1-Methylcytosine occupies a central position within the hachimoji DNA architecture as the S nucleobase, contributing to the formation of a synthetic genetic system that utilizes eight distinct nucleotide letters [9] [14]. Hachimoji DNA, derived from the Japanese term meaning "eight letters," incorporates four natural nucleobases (adenine, thymine, guanine, cytosine) alongside four synthetic nucleobases, including 1-methylcytosine [9] [21].
The architectural integration of 1-methylcytosine within hachimoji DNA maintains the essential structural requirements necessary for supporting Darwinian evolution [21] [23]. Crystal structure analyses have demonstrated that synthetic building blocks, including 1-methylcytosine, do not significantly perturb the aperiodic crystal formation observed in natural DNA double helix structures [23] [28]. Three distinct crystal structures of hachimoji duplexes revealed that the DNA adopts a standard B-form configuration with 10.2 to 10.4 base pairs per turn, confirming structural compatibility with natural DNA systems [23].
The polyelectrolyte backbone integrity remains preserved when 1-methylcytosine is incorporated into hachimoji DNA systems [21] [23]. This structural preservation enables the synthetic system to maintain predictable thermodynamic stability while providing expanded informational capacity [23]. The stereoregular building blocks, including 1-methylcytosine, fit seamlessly into the Schrödinger aperiodic crystal framework, ensuring compatibility with biological replication machinery [21] [23].
Thermodynamic parameter measurements for hachimoji DNA containing 1-methylcytosine demonstrate melting temperature predictions within 2.1°C accuracy for 94 different hachimoji duplexes [23]. Free energy change predictions achieve accuracy within 0.39 kilocalories per mole, comparable to nearest-neighbor parameters observed in standard DNA systems [23]. These measurements confirm that 1-methylcytosine contributes to an informational system with predictable molecular recognition behavior [23].
| Base Pair | Hydrogen Bonds | Pairing Type | Role in Hachimoji |
|---|---|---|---|
| 1-Methylcytosine : Isoguanine | 3 | Synthetic Watson-Crick-like | S component pairing |
| Cytosine : Guanine (Natural) | 3 | Natural Watson-Crick | Natural component |
| Adenine : Thymine (Natural) | 2 | Natural Watson-Crick | Natural component |
| Guanine : Cytosine (Natural) | 3 | Natural Watson-Crick | Natural component |
| P : Z (Hachimoji) | 3 | Synthetic | Artificial base pair |
| S : B (Hachimoji) | 2 | Synthetic | Artificial base pair (S=1-methylcytosine, B=isoguanine) |
Base Pairing Dynamics with Isoguanine
The base pairing dynamics between 1-methylcytosine and isoguanine represent a critical aspect of expanded genetic alphabet functionality [2] [13] [16]. This synthetic base pair forms through hydrogen bonding interactions that mirror the stability and specificity observed in natural Watson-Crick base pairs [13] [16]. The 1-methylcytosine-isoguanine pairing exhibits three hydrogen bonds, providing thermodynamic stability comparable to the natural guanine-cytosine pair [13] [14].
Thermodynamic studies have revealed that the 1-methylcytosine-isoguanine base pair maintains melting temperatures of approximately 74.5°C under standard conditions, demonstrating remarkable thermal stability [3] [13]. The base pairing selectivity of this synthetic pair shows reduced mispairing compared to earlier isoguanine-isocytosine combinations, with enhanced discrimination against natural nucleobases [13] [16].
Research investigations into base pairing properties demonstrate that 1-methylcytosine exhibits different mispairing patterns depending on the backbone scaffold employed [13] [16]. In enzymatic incorporation experiments, 1-methylcytosine shows preferential pairing with isoguanine while exhibiting reduced incorporation opposite natural nucleobases [13] [16]. The hexitol backbone modification influences selectivity, with variable effects observed across different DNA polymerases [13] [16].
Molecular dynamics simulations and density functional theory calculations have provided insights into the proton transfer mechanisms affecting 1-methylcytosine base pairing [32] [35]. Studies indicate that certain base pairs in hachimoji DNA, including those involving 1-methylcytosine, allow proton transfer to occur approximately 30% faster than in natural DNA systems [32] [35]. This enhanced proton mobility potentially contributes to increased mutation rates in synthetic genetic systems [32] [35].
The base pairing dynamics exhibit temperature-dependent characteristics, with 1-methylcytosine maintaining stable hydrogen bonding interactions across physiologically relevant temperature ranges [6] [25]. High-level quantum chemical calculations predict tautomerization equilibrium constants and rate constants for water-assisted proton transfer involving 1-methylcytosine [25]. These studies demonstrate that hydration effects significantly influence the stability and dynamics of 1-methylcytosine base pairs [25].
Contribution to Expanded Genetic Alphabets
1-Methylcytosine serves as a fundamental building block in the development of expanded genetic alphabets that transcend the limitations of natural four-letter DNA systems [12] [19] [30]. The incorporation of 1-methylcytosine into synthetic genetic systems enables the creation of DNA molecules with enhanced information storage capacity, effectively doubling the potential informational content compared to natural systems [21] [23].
The expanded genetic alphabet incorporating 1-methylcytosine has demonstrated functional capabilities in molecular evolution experiments [12] [36]. Artificially expanded genetic information systems utilizing 1-methylcytosine have successfully evolved enzymatic activities, including ribonucleases that degrade RNA substrates [12]. These evolutionary experiments provide direct evidence that expanded alphabets can support Darwinian evolution and generate novel catalytic functions [12].
Information density calculations for hachimoji DNA containing 1-methylcytosine reveal a theoretical capacity of three bits per nucleotide position, compared to two bits per position in natural DNA [23]. This enhanced information density enables the construction of shorter oligonucleotide sequences while maintaining equivalent informational content [12] [23]. The practical applications of this increased capacity include enhanced molecular barcoding, combinatorial tagging systems, and retrievable information storage applications [23].
Experimental validation of expanded genetic alphabets has confirmed that 1-methylcytosine maintains genetic information stability across multiple replication cycles [34]. Semisynthetic organisms engineered with expanded genetic alphabets containing 1-methylcytosine demonstrate robust growth characteristics and indefinite retention of synthetic genetic information [34]. These organisms represent stable forms of semisynthetic life capable of storing and retrieving expanded genetic information [34].
The contribution of 1-methylcytosine to expanded genetic alphabets extends beyond simple information storage to enable novel protein synthesis capabilities [17] [18]. Genetic code expansion applications utilize 1-methylcytosine-containing systems to incorporate non-canonical amino acids into proteins, creating novel biological materials with enhanced properties [17] [18]. These applications span synthetic biology, protein engineering, drug development, and vaccine production [17].
| System | Melting Temperature (°C) | Stability Relative to Natural | Information Density |
|---|---|---|---|
| Natural DNA (G:C) | ~85-95 | Reference (100%) | 2 bits per position |
| Natural DNA (A:T) | ~65-75 | Lower | 2 bits per position |
| 1-Methylcytosine systems | 74.5 ± 0.1 | Comparable | 2 bits per position |
| Hachimoji DNA (average) | ~75-85 | Similar to natural | 3 bits per position |
| PNA-DNA hybrid | ~60-70 | Variable | 2 bits per position |
| RNA-RNA duplex | ~55-65 | Lower | 2 bits per position |
Implications for Synthetic Biology Advancements
The development of 1-methylcytosine-based synthetic nucleic acid systems has profound implications for advancing synthetic biology capabilities across multiple application domains [17] [18] [20]. These synthetic systems provide enhanced tools for biological engineering, enabling the creation of organisms with novel attributes and functions not found in natural biological systems [20] [22].
Biotechnology applications of 1-methylcytosine systems include the development of enhanced biosensors, improved diagnostic platforms, and novel therapeutic approaches [17] [33]. The expanded genetic alphabet capabilities enable the construction of more sophisticated genetic circuits with increased complexity and functionality [33]. Machine learning algorithms are being developed to predict and optimize the behavior of cells engineered with 1-methylcytosine-containing genetic systems [33].
Pharmaceutical research applications leverage 1-methylcytosine systems for drug discovery and development processes [17] [22]. The ability to incorporate non-canonical amino acids through expanded genetic codes enables the synthesis of novel therapeutic proteins with enhanced stability, specificity, and efficacy [17] [22]. Click chemistry applications utilizing 1-methylcytosine systems allow for precise protein labeling and modification within living cells [20].
The implications for understanding fundamental biological processes extend to investigations of alternative life forms and astrobiology research [21] [23]. Hachimoji DNA systems containing 1-methylcytosine expand the scope of molecular structures that might support life, including potential life forms throughout the cosmos [21] [23]. These studies provide insights into the flexibility and constraints of genetic systems in supporting biological processes [21] [23].
Future developments in synthetic biology utilizing 1-methylcytosine systems include the creation of fully synthetic cells, advanced biomaterials, and novel manufacturing platforms [20] [33]. The integration of 1-methylcytosine-based systems with other synthetic biology tools promises to accelerate the development of biotechnology applications across medicine, manufacturing, and environmental applications [17] [18] [33].
Research into genetic code expansion using 1-methylcytosine systems continues to reveal new possibilities for engineering biological systems with enhanced capabilities [17] [18]. The stable incorporation of synthetic genetic information enables long-term studies of engineered organisms and the development of sustainable biotechnology platforms [34]. These advancements represent fundamental progress toward creating truly synthetic forms of life with programmable characteristics [22] [34].
| Application Area | Current Status | Key Advantage | Technical Challenge |
|---|---|---|---|
| Expanded Genetic Alphabets | Laboratory demonstration | Double information density | Stability maintenance |
| Information Storage Systems | Proof of concept | Enhanced storage capacity | Error rate control |
| Biotechnology Platform Development | Early development | Novel protein synthesis | System integration |
| Pharmaceutical Research | Research phase | Targeted therapeutics | Biocompatibility |
| Diagnostic Systems | Development phase | Improved specificity | False positive reduction |
| Evolutionary Studies | Research phase | Alternative life forms study | Replication fidelity |
The enzymatic formation of 1-methylcytosine represents a complex biochemical process that differs significantly from the well-characterized pathways of 5-methylcytosine synthesis. Unlike the canonical methylation at the carbon-5 position, 1-methylcytosine formation involves modification at the nitrogen-1 position of the pyrimidine ring, requiring distinct enzymatic mechanisms and cofactor requirements.
DNA Methyltransferase-Mediated Pathways
DNA methyltransferases traditionally catalyze the transfer of methyl groups from S-adenosylmethionine to the carbon-5 position of cytosine residues. However, under specific conditions, these enzymes can exhibit altered substrate specificity, leading to N1 methylation. The mechanism involves the formation of a covalent enzyme-DNA intermediate where a conserved cysteine residue attacks the cytosine C6 position, temporarily activating the base for methyl transfer. In the case of 1-methylcytosine formation, the methyl group is directed to the N1 position rather than the C5 position, likely due to altered protein-DNA contacts or modified cofactor positioning.
The reaction mechanism begins with DNA methyltransferase binding to the target DNA sequence, followed by base flipping of the cytosine residue into the enzyme active site. S-adenosylmethionine serves as the methyl donor, with the sulfonium group providing electrophilic character to the methyl carbon. The enzyme creates a Michael adduct through nucleophilic attack by Cys81 on cytosine C6, concurrent with methyl transfer to the N1 position. This concerted mechanism is followed by base-catalyzed elimination of the H5 proton and release of S-adenosylhomocysteine as a byproduct.
Alternative Enzymatic Pathways
Beyond traditional DNA methyltransferases, several alternative enzymatic pathways can contribute to 1-methylcytosine formation. Template-independent polymerases, such as KOD and Phusion DNA polymerases, demonstrate the ability to incorporate modified nucleotides containing 1-methylcytosine during oligonucleotide synthesis. These enzymes exhibit differential efficiency in incorporating modified nucleotides, with KOD DNA polymerase showing superior performance compared to other thermostable polymerases.
Methyltransferase enzymes with altered substrate specificity can also contribute to 1-methylcytosine formation. The enzyme's ability to recognize and modify cytosine analogs depends on the steric compatibility of the substrate within the active site. Structural studies reveal that modifications at the 4 and 5 positions of the pyrimidine ring control the conformation of the methyltransferase active site loop and influence enzyme-DNA complex formation.
Cofactor Requirements and Reaction Conditions
The enzymatic formation of 1-methylcytosine requires specific cofactors and reaction conditions that differ from canonical cytosine methylation. S-adenosylmethionine remains the primary methyl donor, but the reaction often requires altered metal ion coordination, typically involving Mg²⁺ or Zn²⁺ ions. These divalent cations play crucial roles in orienting S-adenosylmethionine in a conformation suitable for methyl donation and stabilizing the enzyme-substrate complex.
The reaction kinetics for 1-methylcytosine formation are significantly slower compared to 5-methylcytosine synthesis, with reduced catalytic efficiency and altered Michaelis-Menten parameters. Studies demonstrate that the oxidation state of cytosine modifications dramatically affects methyltransferase activity, with catalytic efficiency decreasing as the base becomes more highly modified.
| Enzyme Family | Mechanism | Cofactors Required | Product |
|---|---|---|---|
| DNA Methyltransferases (DNMTs) | Transfer of methyl group from S-adenosylmethionine to cytosine N1 position | S-adenosylmethionine, Mg²⁺/Zn²⁺ | 1-methylcytosine + S-adenosylhomocysteine |
| Terpene Eleven Translocation (TET) Enzymes | Oxidative modification of existing methylcytosines | Fe(II), α-ketoglutarate, ascorbate | Oxidized methylcytosine derivatives |
| Template-independent Polymerases | Incorporation during enzymatic DNA synthesis with modified nucleotides | Mg²⁺, modified nucleotide triphosphates | Modified oligonucleotides containing 1-methylcytosine |
| Methionine Adenosyltransferase | Formation of S-adenosylmethionine cofactor for methylation reactions | ATP, methionine, K⁺ | S-adenosylmethionine |
| Maintenance Methyltransferases | Recognition and methylation of hemimethylated DNA substrates | S-adenosylmethionine, UHRF1 | Methylated hemimethylated DNA |
Recognition by DNA-Binding Proteins
The recognition of 1-methylcytosine by DNA-binding proteins represents a fundamental departure from the well-established protein-DNA interactions observed with 5-methylcytosine. The altered chemical structure and hydrogen bonding patterns of 1-methylcytosine significantly impact its recognition by methyl-CpG-binding proteins, transcription factors, and chromatin-associated complexes.
Methyl-CpG-Binding Domain Protein Interactions
Methyl-CpG-binding domain proteins, including MeCP2, MBD1, MBD2, and MBD4, demonstrate markedly reduced affinity for 1-methylcytosine compared to 5-methylcytosine. Structural analysis reveals that these proteins recognize methylated cytosines through specific arginine and tyrosine residues that form hydrogen bonds and van der Waals contacts in the major groove. The N1 methylation in 1-methylcytosine disrupts the canonical hydrogen bonding pattern, particularly affecting the interaction between the protein and the N1 position of cytosine.
Fluorescence quenching assays demonstrate that the association constants for 1-methylcytosine-containing DNA with MBD proteins are reduced by approximately 10-fold compared to 5-methylcytosine. This reduced binding affinity results from the inability of 1-methylcytosine to form the stabilizing hydrophobic contacts typically observed with the methyl group at the C5 position. The altered recognition pattern leads to differential binding preferences, where some MBD proteins show complete loss of binding while others retain weak interactions.
SET- and RING-Associated Domain Recognition
SET- and RING-associated domain proteins, exemplified by UHRF1, employ a base-flipping mechanism to recognize hemimethylated DNA. These proteins insert the methylated cytosine into a deep hydrophobic pocket where it is stabilized by planar stacking contacts and hydrogen bonding interactions. The recognition of 1-methylcytosine by SRA domain proteins is significantly compromised due to the altered hydrogen bonding capacity and steric hindrance introduced by N1 methylation.
The base-flipping mechanism employed by SRA domain proteins depends on specific interactions with the methylated cytosine that discriminate against unmethylated bases. The N1 methylation in 1-methylcytosine disrupts these discriminatory interactions, leading to reduced binding specificity and potential recognition of both methylated and unmethylated substrates. This altered recognition pattern has implications for maintenance methylation processes that depend on SRA domain protein recruitment.
Transcription Factor Recognition Mechanisms
Transcription factors exhibit variable responses to 1-methylcytosine, with some showing enhanced binding while others display reduced affinity. Homeodomain proteins, such as HOXB13, recognize methylated CpG sites through hydrophobic interactions between amino acid side chains and the methyl groups. The altered position of methylation in 1-methylcytosine requires different amino acid residues for recognition, potentially leading to altered transcription factor binding specificities.
Studies of posterior homeodomain proteins reveal that recognition of methylated cytosines involves specific amino acid residues that form hydrophobic contacts with methyl groups. The N1 methylation in 1-methylcytosine presents the methyl group in a different spatial orientation, requiring alternative protein-DNA contact patterns. This altered recognition mechanism can lead to differential gene expression patterns and modified transcriptional responses.
Chromatin Remodeling Complex Interactions
Chromatin remodeling complexes recognize methylated DNA indirectly through recruitment by methyl-CpG-binding proteins and other chromatin-associated factors. The reduced recognition of 1-methylcytosine by canonical methyl-binding proteins leads to altered recruitment patterns for chromatin remodeling activities. This disruption in protein recruitment can result in changes to chromatin structure and accessibility.
The nucleosome remodeling and deacetylase complex requires specific methyl-CpG-binding proteins for recruitment to methylated chromatin regions. The poor recognition of 1-methylcytosine by these recruiting proteins leads to reduced complex assembly and altered chromatin modifications. This disruption has downstream effects on gene expression and chromatin organization.
| Protein Family | Recognition Specificity | Binding Affinity (1mC vs 5mC) | Functional Consequence |
|---|---|---|---|
| Methyl-CpG-Binding Domain (MBD) Proteins | Preferential binding to 5-methylcytosine over 1-methylcytosine | Reduced (~10-fold lower) | Altered gene repression patterns |
| SET- and RING-Associated (SRA) Domain Proteins | Recognition of hemimethylated cytosines through base-flipping | Significantly reduced | Modified maintenance methylation |
| CXXC Domain Proteins | Binding to unmethylated CpG dinucleotides | No specific recognition | Loss of targeting specificity |
| Transcription Factors (Homeodomain) | Enhanced affinity for methylated CpG sites through hydrophobic contacts | Variable, context-dependent | Changed transcriptional regulation |
| Chromatin Remodeling Complexes | Recruitment to methylated chromatin regions | Indirect recognition | Disrupted chromatin organization |
Influence on DNA Structural Dynamics
The incorporation of 1-methylcytosine into DNA structures introduces significant alterations to the dynamic properties and conformational flexibility of the double helix. These structural modifications affect multiple parameters including base pairing stability, major and minor groove geometry, backbone flexibility, and overall DNA dynamics.
Base Pairing and Hydrogen Bonding Alterations
The N1 methylation in 1-methylcytosine fundamentally alters the hydrogen bonding pattern with its complementary guanine base. Unlike 5-methylcytosine, which maintains canonical Watson-Crick base pairing, 1-methylcytosine exhibits modified hydrogen bonding due to the steric and electronic effects of the N1 methyl group. Association constant studies reveal that 1-methylcytosine forms Watson-Crick pairs with guanine derivatives, but with altered stability compared to unmodified cytosine.
The hydrogen bonding properties of 1-methylcytosine demonstrate enhanced stability when paired with modified guanine bases, particularly those with increased N1H acidity. This enhanced stability follows a bell-shaped relationship with guanine acidity, where optimal stabilization occurs at intermediate levels of acidification. The association constants for Watson-Crick pairing between 1-methylcytosine and modified guanines can be 2-3 times higher than the canonical cytosine-guanine pair.
DNA Melting Temperature and Thermodynamic Stability
The incorporation of 1-methylcytosine leads to a moderate increase in DNA melting temperature, typically ranging from 2-4°C above unmodified DNA. This thermal stabilization results from enhanced base stacking interactions and modified hydrogen bonding patterns. Comparative studies demonstrate that the stabilization effect of 1-methylcytosine is comparable to that observed with 5-methylcytosine, though achieved through different molecular mechanisms.
Thermodynamic analyses reveal that 1-methylcytosine contributes to duplex stability through multiple mechanisms, including enhanced base stacking, modified electrostatic interactions, and altered hydration patterns. The methyl group at the N1 position creates additional van der Waals contacts within the major groove while modifying the electrostatic potential of the base. These changes contribute to overall duplex stabilization while simultaneously affecting protein-DNA interactions.
Major and Minor Groove Structural Modifications
The presence of 1-methylcytosine induces subtle but significant changes to DNA groove geometry. The major groove experiences slight expansion due to the steric effects of the N1 methyl group, which projects into the groove and influences the spatial arrangement of neighboring bases. This expansion affects the accessibility of the groove to DNA-binding proteins and modifies the pattern of protein-DNA contacts.
The minor groove electrostatic potential is significantly altered by 1-methylcytosine incorporation. The N1 methylation changes the charge distribution within the base, leading to modified electrostatic interactions with proteins that recognize DNA through minor groove contacts. These changes can enhance or diminish protein binding depending on the specific requirements of the protein-DNA interface.
Backbone Flexibility and Dynamic Properties
Molecular dynamics simulations reveal that 1-methylcytosine incorporation affects DNA backbone flexibility, particularly at the CpG dinucleotide step. The roll angle shows increased flexibility compared to unmodified DNA, indicating enhanced conformational dynamics. This increased flexibility results from the altered stacking interactions and modified electrostatic environment created by the N1 methyl group.
The dynamic properties of 1-methylcytosine-containing DNA demonstrate increased propensity for conformational changes. Hydrogen exchange studies show enhanced exchange rates for imino protons in guanines paired with 1-methylcytosine, indicating increased base pair opening dynamics. These enhanced dynamics suggest that 1-methylcytosine creates a more flexible DNA structure that may be more accessible to enzymatic modification.
Nucleosome Formation and Chromatin Structure
The incorporation of 1-methylcytosine affects nucleosome formation efficiency and chromatin structure. Studies demonstrate that DNA containing 1-methylcytosine shows reduced efficiency in nucleosome assembly compared to unmodified DNA. This reduction results from altered histone-DNA contacts and modified DNA flexibility that disrupts optimal nucleosome positioning.
The impact on chromatin structure extends beyond nucleosome formation to affect higher-order chromatin organization. The altered DNA dynamics and protein recognition patterns associated with 1-methylcytosine lead to changes in chromatin compaction and accessibility. These structural modifications can have downstream effects on gene expression and epigenetic regulation.
| Parameter | 1-Methylcytosine Effect | 5-Methylcytosine Comparison | Molecular Basis |
|---|---|---|---|
| DNA Melting Temperature (Tm) | Moderate increase (+2-4°C) | Similar increase (+3-5°C) | Enhanced base stacking interactions |
| Major Groove Width | Slight expansion | Minimal change | Steric effects of N1 methylation |
| Minor Groove Electrostatic Potential | Altered charge distribution | Hydrophobic methyl group effect | Changed hydrogen bonding patterns |
| Roll Angle (CpG step) | Increased flexibility | Increased roll angle | Altered backbone flexibility |
| Base Pair Stability | Enhanced hydrogen bonding | Stable Watson-Crick pairing | Modified tautomeric equilibrium |
| Nucleosome Formation Efficiency | Reduced efficiency | Slightly reduced efficiency | Disrupted histone-DNA contacts |
Comparative Analysis with 5-Methylcytosine Systems
The comparative analysis between 1-methylcytosine and 5-methylcytosine systems reveals fundamental differences in chemical properties, biological recognition, and functional roles. These distinctions highlight the unique characteristics of 1-methylcytosine and its potential applications in research and therapeutic contexts.
Chemical Structure and Position-Specific Effects
The primary structural difference between 1-methylcytosine and 5-methylcytosine lies in the position of methylation within the pyrimidine ring. In 1-methylcytosine, the methyl group is attached to the nitrogen atom at position 1, while 5-methylcytosine bears the methyl group on the carbon atom at position 5. This positional difference creates distinct chemical environments and reactivity patterns.
The N1 methylation in 1-methylcytosine significantly affects the base's tautomeric equilibrium and hydrogen bonding capacity. Unlike 5-methylcytosine, which predominantly exists in the amino-oxo tautomer, 1-methylcytosine can adopt both amino-oxo and imino-oxo tautomeric forms under physiological conditions. This tautomeric diversity contributes to altered base pairing properties and protein recognition patterns.
The methylation position also influences the chemical reactivity and stability of the modified base. Studies of anionic states reveal that 1-methylcytosine can stabilize rare tautomeric forms that are not accessible to unmodified cytosine or 5-methylcytosine. These unusual tautomers may have implications for DNA damage recognition and repair processes.
Biological Occurrence and Distribution
5-Methylcytosine is ubiquitous in mammalian genomes, accounting for approximately 2-4% of all cytosines and serving as a major epigenetic modification. It is found primarily in CpG dinucleotides in vertebrates, with 70-80% of CpG cytosines being methylated. This widespread distribution reflects its fundamental role in gene regulation, genomic imprinting, and X-chromosome inactivation.
In contrast, 1-methylcytosine has limited natural occurrence and is primarily encountered in synthetic and experimental systems. Its presence in biological systems is typically associated with artificial introduction or specific research applications rather than natural epigenetic processes. This distinction reflects the specialized enzymatic machinery required for 5-methylcytosine formation and maintenance, which is not adapted for 1-methylcytosine recognition.
The differential distribution patterns have implications for cellular responses to these modifications. While 5-methylcytosine is recognized as a normal epigenetic mark, 1-methylcytosine may be processed as a DNA lesion by cellular repair systems. This difference in cellular recognition affects the stability and persistence of these modifications in genomic DNA.
Enzymatic Formation and Maintenance Systems
The enzymatic systems responsible for 5-methylcytosine formation are highly specialized and evolutionarily conserved. DNA methyltransferases DNMT1, DNMT3A, and DNMT3B specifically recognize cytosine residues and catalyze methylation at the C5 position using S-adenosylmethionine as a methyl donor. These enzymes exhibit exquisite specificity for the C5 position and do not efficiently methylate the N1 position under physiological conditions.
The formation of 1-methylcytosine requires altered enzymatic conditions or modified enzyme variants that lack the normal positional specificity. Studies with cytosine analogs demonstrate that methyltransferases can be engineered or chemically modified to accept alternative substrates, but with significantly reduced efficiency. The lack of dedicated enzymatic machinery for 1-methylcytosine maintenance explains its limited biological occurrence.
Maintenance systems for 5-methylcytosine involve sophisticated recognition mechanisms that distinguish hemimethylated DNA and recruit appropriate methyltransferases. The UHRF1 protein plays a crucial role in recognizing hemimethylated CpG sites and recruiting DNMT1 for maintenance methylation. These maintenance systems are not adapted for 1-methylcytosine recognition, leading to potential loss of this modification during DNA replication.
Protein Recognition and Functional Consequences
The protein recognition systems for 5-methylcytosine are highly developed and include multiple protein families with distinct recognition mechanisms. Methyl-CpG-binding domain proteins, SRA domain proteins, and various transcription factors have evolved specific binding modes that recognize the C5 methyl group and its effects on DNA structure. These proteins mediate the functional consequences of 5-methylcytosine, including gene silencing and chromatin organization.
Recognition of 1-methylcytosine by these canonical protein systems is significantly impaired. The altered hydrogen bonding pattern and steric effects of N1 methylation disrupt the specific protein-DNA contacts required for high-affinity binding. This poor recognition by natural methyl-binding proteins limits the epigenetic functionality of 1-methylcytosine in normal cellular contexts.
The differential protein recognition has implications for transcriptional regulation and chromatin structure. While 5-methylcytosine consistently promotes gene silencing through recruitment of repressive protein complexes, 1-methylcytosine may have variable or unpredictable effects on gene expression due to its poor recognition by canonical regulatory proteins.
Therapeutic and Research Applications
5-Methylcytosine and its associated enzymatic machinery represent established therapeutic targets for cancer treatment and other diseases. DNA methyltransferase inhibitors such as 5-azacytidine and decitabine are FDA-approved drugs that target the 5-methylcytosine system. The well-characterized nature of this system facilitates drug development and therapeutic intervention.
1-Methylcytosine represents an emerging area of therapeutic interest with potential applications in research and drug development. Its unique chemical properties and altered protein recognition patterns make it a valuable tool for studying DNA-protein interactions and developing novel therapeutic strategies. The poor recognition by natural repair systems may allow 1-methylcytosine-containing oligonucleotides to persist longer in cells, potentially enhancing their therapeutic efficacy.
Research applications of 1-methylcytosine include its use as a chemical probe for studying methylation-dependent processes and as a component of modified oligonucleotides for therapeutic applications. Its ability to disrupt normal protein-DNA interactions while maintaining base pairing capacity makes it valuable for mechanistic studies and potential therapeutic interventions.
| Property | 1-Methylcytosine | 5-Methylcytosine | Functional Significance |
|---|---|---|---|
| Chemical Position of Methylation | N1 position (nitrogen methylation) | C5 position (carbon methylation) | Altered hydrogen bonding patterns |
| Biological Occurrence | Synthetic/experimental systems | Widespread in mammalian genomes | Research tool vs. physiological regulator |
| Enzymatic Formation | Non-standard methyltransferase activity | DNMT1, DNMT3A, DNMT3B enzymes | Different enzymatic requirements |
| Protein Recognition | Poor recognition by canonical readers | Recognized by MBD, SRA, others | Distinct protein interaction profiles |
| Tautomeric Forms | Amino-oxo and imino-oxo forms | Predominantly amino-oxo form | Different chemical stability |
| DNA Repair Recognition | May be recognized as damage | Normal epigenetic mark | Variable cellular responses |
| Epigenetic Function | Limited natural epigenetic role | Major epigenetic modification | Research vs. regulatory applications |
| Therapeutic Targeting | Potential therapeutic applications | Established therapeutic target | Emerging vs. established strategies |
XLogP3
UNII
GHS Hazard Statements
H302 (100%): Harmful if swallowed [Warning Acute toxicity, oral];
H315 (100%): Causes skin irritation [Warning Skin corrosion/irritation];
H319 (100%): Causes serious eye irritation [Warning Serious eye damage/eye irritation];
H335 (100%): May cause respiratory irritation [Warning Specific target organ toxicity, single exposure;
Respiratory tract irritation]
Pictograms

Irritant
Other CAS
Wikipedia
Dates
Explore Compound Types