IQ-3
Content Navigation
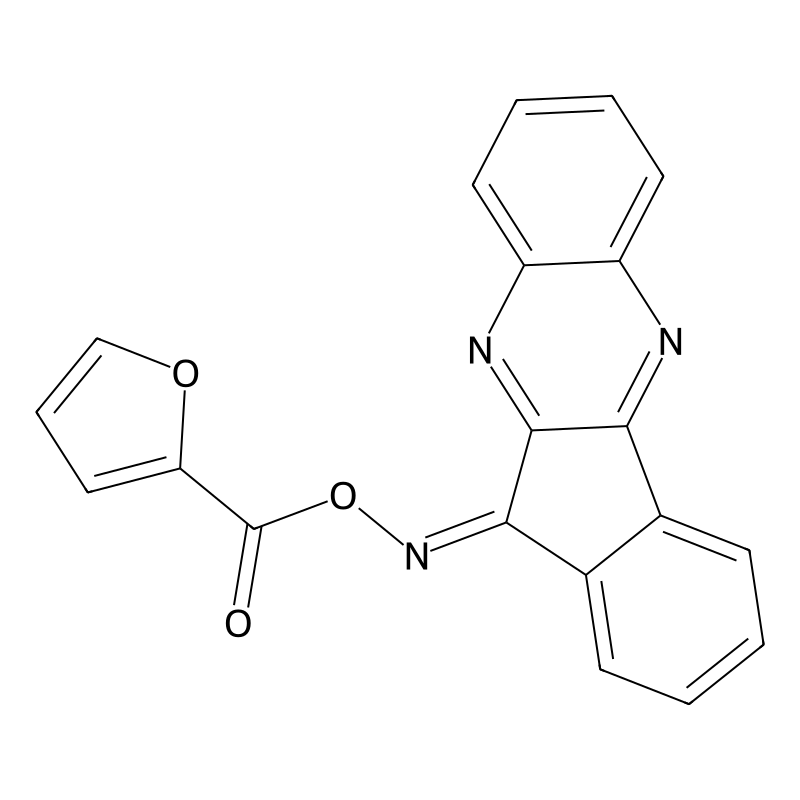
Addressing the challenge of isolating JNK3-dependent neuroinflammatory pathways from JNK1/2 housekeeping functions, IQ-3 is a highly specific ATP-competitive JNK3 inhibitor (Kd = 66 nM, >240 nM for JNK1/2). It reliably suppresses LPS-induced NF-κB/AP-1 activity (IC50 1.4 μM) without off-target TRK-A inhibition, ensuring unconfounded neurotrophic signaling in neurodegenerative models. Supplied as a research-grade small molecule, IQ-3 guarantees assay reproducibility and minimal cytotoxicity, making it the preferred benchmark for CNS-targeted kinase screening.
Product Name
IUPAC Name
Molecular Formula
Molecular Weight
InChI
InChI Key
SMILES
Canonical SMILES
Synonyms
Purity
Package Size
IQ-3 (11H-indeno[1,2-b]quinoxalin-11-one-O-(2-furoyl)oxime; CAS: 312538-03-7) is a highly specific, ATP-competitive inhibitor of the c-Jun N-terminal kinase (JNK) family, characterized by its pronounced selectivity for JNK3. Unlike broad-spectrum kinase inhibitors, this indenoquinoxaline derivative is engineered to selectively suppress lipopolysaccharide (LPS)-induced NF-κB/AP-1 transcriptional activity and downstream pro-inflammatory cytokine production, including TNF-α and IL-6 [1]. For procurement in neuroinflammation research, ischemic injury modeling, and targeted immunology screening, IQ-3 provides a structurally distinct, reversible mechanism that isolates JNK3-dependent pathways from ubiquitous JNK1/2 signaling networks, ensuring high-fidelity assay reproducibility and minimizing off-target cytotoxicity .
Research Fit
Substituting IQ-3 with classic pan-JNK inhibitors like SP600125 or irreversible covalent binders like JNK-IN-8 fundamentally compromises assay specificity and cellular viability. SP600125 exhibits equipotent or stronger inhibition of JNK1/2 compared to JNK3, making it impossible to isolate JNK3-mediated neuroprotective or anti-inflammatory effects from systemic JNK1/2 housekeeping functions [1]. Furthermore, unlike generic tryptanthrin-derived inhibitors, IQ-3 completely lacks off-target affinity for TRK-A, ensuring that neurotrophic signaling remains intact during neurodegenerative disease modeling [2]. Relying on the unfunctionalized parent compound IQ-1 also results in weaker JNK3 binding affinity, reducing the dynamic range in high-stringency biochemical assays and requiring higher solvent concentrations that can induce artifactual cytotoxicity .
Substitution Risk
Broader off-target kinase binding profile may shift experimental outcomes and confound pathway attribution.
Irreversible binding mechanism limits direct comparison in kinetic or washout studies.
Distinct isoform affinity and incomplete off-target characterization may alter target engagement patterns.
References
- [1] Schepetkin, I. A., et al. 'Identification and Characterization of a Novel Class of c-Jun N-terminal Kinase Inhibitors.' Molecular Pharmacology 81.6 (2012): 832-845.
- [2] Schepetkin, I. A., et al. 'Synthesis, Biological Evaluation, and Molecular Modeling of 11H-indeno[1,2-b]quinoxalin-11one Derivatives and Tryptanthrin-6-Oxime as c-Jun N-terminal Kinase Inhibitors.' European Journal of Medicinal Chemistry (2014).
JNK3 Selectivity for CNS Modeling
IQ-3 demonstrates a distinct preference for JNK3, which is primarily expressed in the CNS, over the ubiquitously expressed JNK1 and JNK2 isoforms. While the benchmark inhibitor SP600125 is pan-reactive and slightly prefers JNK1/2, IQ-3 achieves a ~3.6 to 4.4-fold selectivity window for JNK3[1].
| Evidence Dimension | Kinase Binding Affinity (Kd / IC50) |
| Target Compound Data | IQ-3 Kd = 66 nM (JNK3), 240 nM (JNK1), 290 nM (JNK2) |
| Comparator Or Baseline | SP600125 IC50 = 90 nM (JNK3), 40 nM (JNK1), 40 nM (JNK2) |
| Quantified Difference | IQ-3 favors JNK3 by >3.6-fold; SP600125 favors JNK1/2 by 2.25-fold. |
| Conditions | Cell-free kinase binding assay / competitive profiling |
Enables researchers to selectively probe JNK3-driven neurodegenerative pathways without knocking out essential JNK1/2 housekeeping activity in peripheral tissues.
Enhanced Binding Reduces Solvent Toxicity
The addition of the O-(2-furoyl)oxime group to the indenoquinoxaline core in IQ-3 significantly improves its binding affinity to the JNK3 ATP-binding pocket compared to the parent compound IQ-1. This structural modification facilitates critical hydrogen bonding interactions with Asn152, Gln155, and Met149, allowing for lower effective concentrations .
| Evidence Dimension | JNK3 Binding Affinity (Kd) |
| Target Compound Data | IQ-3 Kd = 66 nM |
| Comparator Or Baseline | IQ-1 Kd = 100 nM |
| Quantified Difference | 34% improvement in JNK3 binding affinity. |
| Conditions | Recombinant JNK3 competitive binding assay |
The tighter active-site binding allows for lower effective dosing, reducing the required DMSO concentration and minimizing solvent-induced cytotoxicity in sensitive primary cell workflows.
Elimination of TRK-A Off-Target Interference
Many JNK inhibitors, including structurally related tryptanthrin derivatives, exhibit confounding off-target activity against tropomyosin-related kinase A (TRK-A). IQ-3 completely lacks binding affinity for TRK-A, ensuring high specificity for JNK pathways [1].
| Evidence Dimension | TRK-A Binding Affinity |
| Target Compound Data | IQ-3 shows no binding to TRK-A |
| Comparator Or Baseline | Tryptanthrin-6-oxime shows high affinity for TRK-A |
| Quantified Difference | Complete elimination of TRK-A cross-reactivity. |
| Conditions | 97-kinase KINOMEscan competitive binding panel at 10 μM |
Prevents confounding interference with nerve growth factor (NGF) signaling, which is critical when modeling neurodegenerative diseases.
Cytokine Suppression in Monocytic Assays
Beyond cell-free affinity, IQ-3 translates its JNK3 inhibition into highly reproducible functional suppression of inflammatory signaling in live cells. It effectively blocks LPS-induced NF-κB/AP-1 transcriptional activity and downstream cytokine release in standard human monocytic models, providing a reliable baseline for lot-to-lot assay consistency[1].
| Evidence Dimension | Inhibition of LPS-induced NF-κB/AP-1 activity |
| Target Compound Data | IQ-3 IC50 = 1.4 μM |
| Comparator Or Baseline | Uninhibited LPS-stimulated baseline (100% activation) |
| Quantified Difference | Dose-dependent reduction to basal levels with an IC50 of 1.4 μM. |
| Conditions | THP1-Blue monocytic cells stimulated with LPS |
Validates that the biochemical JNK selectivity translates into robust, quantifiable suppression of inflammatory signaling, ensuring reproducible performance in mainstream industrial in vitro models.
Neurodegeneration and Stroke Models
Because JNK3 is predominantly expressed in the CNS and is a key driver of neuronal apoptosis, IQ-3 is the preferred inhibitor for in vitro and in vivo models of Alzheimer's, Parkinson's, and ischemic stroke. Its lack of TRK-A interference ensures that neurotrophic survival signals remain unconfounded during testing [1].
Anti-Inflammatory Drug Screening
IQ-3 serves as a highly reliable benchmark compound in screening assays evaluating novel indenoquinoxaline derivatives or other small molecules. Its well-characterized IC50 (1.4 μM) for suppressing LPS-induced NF-κB/AP-1 activity in THP1-Blue cells provides a strict quantitative baseline for hit-to-lead optimization .
Kinase Selectivity Profiling
In broad kinase screening panels, IQ-3 is utilized as a positive control for JNK3-specific binding. Its distinct selectivity profile (Kd = 66 nM for JNK3 vs. >240 nM for JNK1/2) allows researchers to differentiate JNK3-mediated responses from pan-JNK or off-target MAPK pathway inhibition, a critical requirement for validating new kinase-targeted therapeutics[2].
Application Fit
References
- [1] Schepetkin, I. A., et al. 'Synthesis, Biological Evaluation, and Molecular Modeling of 11H-indeno[1,2-b]quinoxalin-11one Derivatives and Tryptanthrin-6-Oxime as c-Jun N-terminal Kinase Inhibitors.' European Journal of Medicinal Chemistry (2014).
- [3] Schepetkin, I. A., et al. 'Identification and Characterization of a Novel Class of c-Jun N-terminal Kinase Inhibitors.' Molecular Pharmacology 81.6 (2012): 832-845.
XLogP3
Hydrogen Bond Acceptor Count
Exact Mass
Monoisotopic Mass
Heavy Atom Count
Explore Compound Types