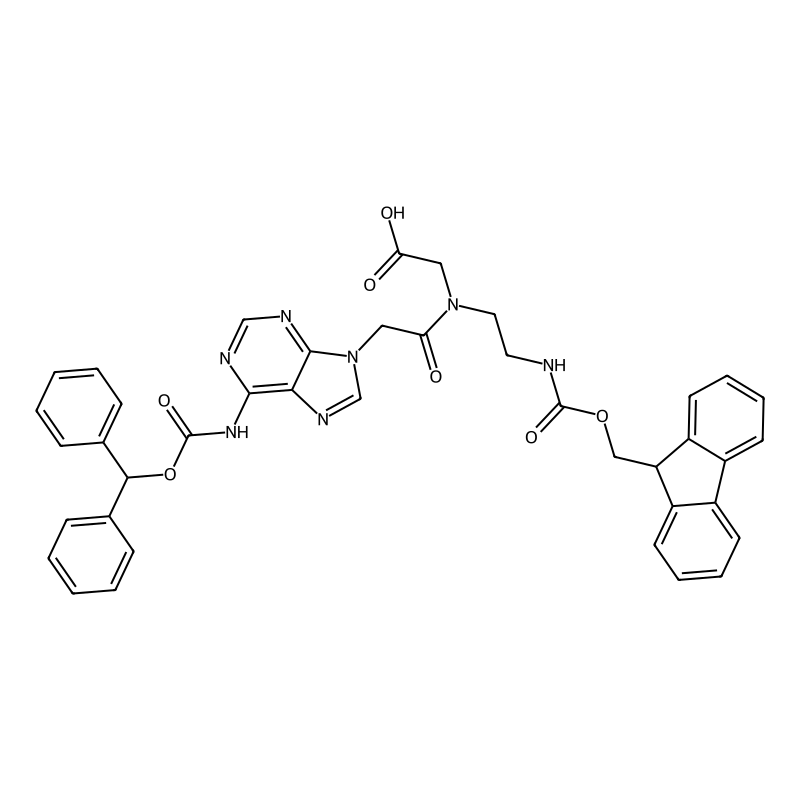
Fmoc-pna-a(bhoc)-oh
Content Navigation
CAS Number
Product Name
IUPAC Name
Molecular Formula
Molecular Weight
InChI
InChI Key
SMILES
Canonical SMILES
Molecular Biology
Application Summary: “Fmoc-pna-a(bhoc)-oh” is used in the synthesis of Peptide Nucleic Acids (PNAs), which are synthetic mimics of DNA and RNA . They are stable, non-toxic, and have found applications in many fields of science, from pure chemistry to drug discovery, nanotechnology, and prebiotic chemistry .
Methods of Application: PNAs are synthesized by solid-phase methods involving assembly of monomers with a tert-butyloxycarbonyl (Boc)/benzyloxycarbonyl (Z = Cbz) protection scheme for the primary amine of the (2-aminoethyl)glycine backbone and nucleobase amino functionalities . These protocols require the use of harsh conditions to release the final oligomer from the solid phase . To overcome this, a Fmoc-based SPS protocol for PNA oligomers was developed . This protocol uses stable, activated pentafluorophenyl esters or the corresponding carboxylic acids in combination with 2-(1H-benzotriazole-1-yl)-1,1,3,3-tetramethyluronium hexafluorophosphate (HBTU)/N-hydroxybenzotriazole (HOBt) to promote coupling of monomers, while 30% piperidine in 20% dimethyl sulfoxide (DMSO) in N-methyl-2-pyrrolidone (NMP) is used for Fmoc removal .
Results or Outcomes: The use of “Fmoc-pna-a(bhoc)-oh” in the synthesis of PNAs has facilitated the exploration of PNA-peptide conjugates as potential antisense antibiotics . This has necessitated fast and efficient synthesis protocols for amounts that facilitate determination of structure-activity relationships and in vivo studies in animal infection models .
Automated Synthesis
Application Summary: “Fmoc-pna-a(bhoc)-oh” is used in the automated synthesis of Peptide Nucleic Acids (PNAs) using microwave-assisted methods .
Methods of Application: The automated synthesis method involves the use of a peptide synthesizer and microwave heating . This method allows for faster and more efficient synthesis of PNAs, which is particularly useful for large-scale production .
Results or Outcomes: The automated synthesis method has been shown to be effective in producing large amounts of PNAs, which are necessary for in vivo studies in animal infection models .
Synthesis of PNA Monomers
Application Summary: “Fmoc-pna-a(bhoc)-oh” is used in the synthesis of PNA monomers .
Methods of Application: The synthesis of PNA monomers involves the use of a Boc protecting group strategy . To overcome the solubility problem of carboxymethyl-guanine derivative, a 2-trimethylsilylethyl group is introduced at O6 as a second protecting group .
Results or Outcomes: The synthesis of PNA monomers using “Fmoc-pna-a(bhoc)-oh” has been successful, and these monomers can be used interchangeably with standard Fmoc PNA monomers .
Biological Probes
Application Summary: “Fmoc-pna-a(bhoc)-oh” is used in the creation of biological probes .
Methods of Application: The biological probes are created by using PNA oligomers, which are synthesized using "Fmoc-pna-a(bhoc)-oh" . These probes are then used to detect specific sequences of DNA or RNA in a biological sample .
Results or Outcomes: The use of these biological probes has allowed for the detection of specific genetic diseases, providing a powerful tool for diagnosis and research .
Nano-Scaffold Components
Application Summary: “Fmoc-pna-a(bhoc)-oh” is used in the creation of nano-scaffold components .
Methods of Application: The nano-scaffold components are created by using PNA oligomers, which are synthesized using "Fmoc-pna-a(bhoc)-oh" . These components are then used in the construction of nanostructures for various applications .
Results or Outcomes: The use of these nano-scaffold components has allowed for the creation of complex nanostructures, providing a powerful tool for nanotechnology .
Diagnostic Tools for Genetic Diseases
Application Summary: “Fmoc-pna-a(bhoc)-oh” is used in the creation of diagnostic tools for genetic diseases .
Methods of Application: The diagnostic tools are created by using PNA oligomers, which are synthesized using "Fmoc-pna-a(bhoc)-oh" . These tools are then used to detect specific sequences of DNA or RNA associated with genetic diseases .
Results or Outcomes: The use of these diagnostic tools has allowed for the detection of specific genetic diseases, providing a powerful tool for diagnosis and research .
Fmoc-pna-a(bhoc)-oh, also known as Fmoc-Peptide Nucleic Acid-A(Bhoc)-OH, is a modified nucleic acid compound characterized by its unique backbone structure. It incorporates a fluorenylmethyloxycarbonyl (Fmoc) protecting group and a benzhydryloxycarbonyl (Bhoc) group, which are crucial for its synthesis and stability. The compound is identified by the CAS number 186046-82-2 and plays a significant role in the field of nucleic acid chemistry, particularly in the synthesis of Peptide Nucleic Acids (PNA) that exhibit enhanced binding properties compared to traditional nucleic acids like DNA and RNA .
- Fmoc Deprotection: The Fmoc group is removed using a 20% piperidine solution in dimethylformamide, allowing for subsequent coupling reactions.
- Coupling Reactions: The activated monomer is coupled to the growing PNA chain, facilitated by the Bhoc group, which protects the exocyclic amino groups during synthesis.
- Cleavage and Deprotection: Final cleavage from the resin and removal of protective groups can be achieved under mild conditions, typically involving acidic treatment to yield the free PNA .
Fmoc-pna-a(bhoc)-oh exhibits significant biological activity due to its ability to hybridize with complementary DNA or RNA strands. The neutrality of its backbone enhances binding affinity, leading to stronger interactions with target sequences compared to traditional nucleic acids. This property makes it particularly useful in applications such as gene targeting and antisense therapies . Additionally, it has been shown to have higher sequence specificity, which is beneficial for diagnostic applications.
The synthesis of Fmoc-pna-a(bhoc)-oh typically follows a solid-phase approach:
- Preparation of Resin: A suitable resin is chosen to support the growing PNA chain.
- Fmoc Deprotection: The initial Fmoc group is removed.
- Monomer Coupling: The Bhoc-protected monomer is activated and coupled to the deprotected amine.
- Repetition of Cycles: Steps 2 and 3 are repeated for each nucleotide addition until the desired length is achieved.
- Final Cleavage: The completed PNA oligomer is cleaved from the resin and deprotected to yield the final product .
Fmoc-pna-a(bhoc)-oh has diverse applications in molecular biology and biotechnology:
- Gene Targeting: Its high binding affinity allows for effective targeting of specific genes.
- Diagnostics: Utilized in assays for detecting specific nucleic acid sequences.
- Therapeutics: Potential use in antisense oligonucleotide therapies due to its ability to inhibit gene expression.
- Research Tools: Employed in various research settings for studying nucleic acid interactions and functions .
Studies have demonstrated that Fmoc-pna-a(bhoc)-oh interacts more effectively with complementary DNA than traditional DNA-DNA interactions. This is attributed to its neutral backbone, which reduces charge repulsion during hybridization. Research indicates that these interactions can be quantitatively assessed using techniques such as fluorescence resonance energy transfer (FRET) and surface plasmon resonance (SPR) to evaluate binding kinetics and affinities .
Several compounds share structural similarities with Fmoc-pna-a(bhoc)-oh but differ in their protective groups or backbone modifications:
| Compound Name | Key Features | Unique Aspects |
|---|---|---|
| Fmoc-PNA-G(Bhoc)-OH | Similar structure with guanine base | Enhanced binding specificity for guanine |
| Fmoc-PNA-C(Bhoc)-OH | Incorporates cytosine base | Variability in hybridization properties |
| Fmoc-PNA-T-OH | Thymine base incorporation | Utilized primarily in gene silencing studies |
These compounds highlight the versatility of Peptide Nucleic Acids and their potential applications across various fields of research and medicine.
Solid-Phase Synthesis Protocols for Nα-Fmoc/Nε-Bhoc Protected Monomers
Solid-phase synthesis of Fmoc-PNA-A(Bhoc)-OH relies on acid-labile resins such as Sieber amide or PAL, which facilitate cleavage under mild trifluoroacetic acid (TFA) conditions [3]. The protocol begins with resin swelling in N-methylpyrrolidone (NMP), followed by iterative cycles of Fmoc deprotection using 20% piperidine in NMP. Activation of the monomer’s carboxyl group is achieved via HBTU (O-benzotriazole-N,N,N',N'-tetramethyluronium hexafluorophosphate) or HATU (1-[bis(dimethylamino)methylene]-1H-1,2,3-triazolo[4,5-b]pyridinium 3-oxid hexafluorophosphate) in the presence of diisopropylethylamine (DIPEA), enabling efficient amide bond formation with the growing PNA chain [3] [4].
A critical advantage of the Fmoc/Bhoc strategy lies in its compatibility with base-sensitive functional groups. Unlike traditional tBoc/Z chemistry, which requires harsh TFA treatments for deprotection, the Bhoc group on adenine’s exocyclic amine is selectively removed under acidic conditions without compromising the Fmoc-protected backbone [2] [3]. Capping unreacted amino groups with acetic anhydride minimizes deletion sequences, ensuring stepwise coupling efficiencies exceeding 98% for oligomers up to 20 residues [3].
Table 1: Reagents for Solid-Phase Synthesis
| Component | Role | Concentration/Volume |
|---|---|---|
| HBTU/HATU | Carboxylate activation | 2–3 equivalents |
| DIPEA | Base catalyst | 4–6 equivalents |
| Piperidine | Fmoc deprotection | 20% v/v in NMP |
| Acetic anhydride | Capping agent | 1:25:25 in NMP:pyridine |
Orthogonal Deprotection Strategies in PNA Oligomerization
Orthogonal protection schemes are essential for introducing modified bases or fluorophores during PNA synthesis. The Bhoc group on adenine’s N6 position demonstrates stability toward piperidine, allowing selective Fmoc removal at the N-terminus without premature deprotection [2] [4]. Subsequent cleavage of Bhoc requires TFA in the presence of scavengers like m-cresol, which prevent side reactions such as tert-butylation [3].
Recent advancements incorporate dual-protected monomers, such as Fmoc-PNA-U'-(Dde)-OH, where the Dde (1-(4,4-dimethyl-2,6-dioxocyclohexylidene)ethyl) group enables post-synthetic labeling at specific sites [4]. For example, hydrazine-mediated Dde removal permits conjugation of fluorescein or Cy5 dyes to the 5-position of uracil, a strategy adaptable to adenine-modified PNAs through analogous Bhoc/Dde combinations [4]. This orthogonal approach preserves backbone integrity while expanding functionalization capabilities.
Chromatographic Purification and Mass Spectrometric Validation Approaches
Purification of Fmoc-PNA-A(Bhoc)-OH oligomers employs reversed-phase high-performance liquid chromatography (RP-HPLC) on C18 columns heated to 55°C to disrupt secondary structures [5]. A gradient of 0.1% TFA in water (buffer A) to 0.1% TFA in acetonitrile (buffer B) resolves full-length products from truncated sequences, with PNAs typically eluting between 32%–37% buffer B [5]. Post-HPLC, matrix-assisted laser desorption/ionization time-of-flight mass spectrometry (MALDI-TOF-MS) using α-cyano-4-hydroxycinnamic acid confirms molecular weights within 0.1% accuracy [6].
Critical Considerations:
Thermodynamic Parameters of Hybridization
The hybridization dynamics of peptide nucleic acids containing adenine monomers like Fmoc-pna-a(bhoc)-oh demonstrate exceptional sequence specificity and binding affinity when interacting with complementary deoxyribonucleic acid and ribonucleic acid targets [6] [7]. Isothermal titration calorimetry measurements reveal that peptide nucleic acid-deoxyribonucleic acid binding exhibits an average free energy of binding of -6.5 ± 0.3 kJ mol⁻¹ bp⁻¹, corresponding to a microscopic binding constant of approximately 14 M⁻¹ bp⁻¹ for perfectly matched duplexes ranging from 6 to 20 base pairs [6] [8]. The binding constants for peptide nucleic acid-deoxyribonucleic acid hybridization reactions span a remarkable range from 1.8 × 10⁶ M⁻¹ for sequences containing thymine-thymine motifs to 4.15 × 10⁷ M⁻¹ for sequences incorporating guanine-adenine combinations [7] [9].
Table 1: Thermodynamic Parameters of Peptide Nucleic Acid-Deoxyribonucleic Acid Interactions
| Study Parameter | Value | Method | Reference |
|---|---|---|---|
| Peptide nucleic acid-deoxyribonucleic acid binding affinity (6-20 bp) | -6.5 ± 0.3 kJ mol⁻¹ bp⁻¹ | Ultraviolet melting/Isothermal titration calorimetry | [6] [8] |
| Microscopic binding constant | 14 M⁻¹ bp⁻¹ | Ultraviolet melting/Isothermal titration calorimetry | [6] [8] |
| Free energy penalty (single mismatch) | 15 kJ mol⁻¹ bp⁻¹ | Ultraviolet melting | [8] |
| Mismatch binding constant | 0.02 M⁻¹ | Ultraviolet melting | [8] |
| Peptide nucleic acid-deoxyribonucleic acid transition temperature range | 329-343 K | Differential scanning calorimetry | [10] [11] |
| Deoxyribonucleic acid-deoxyribonucleic acid transition temperature range | 322-323 K | Differential scanning calorimetry | [10] [11] |
Sequence Recognition Specificity
The sequence specificity of peptide nucleic acid hybridization demonstrates extraordinary discrimination against mismatched targets, with melting temperatures dropping typically 15-20°C for single mismatches in 9-mer and 12-mer peptide nucleic acid-deoxyribonucleic acid duplexes relative to perfectly matched sequences [8]. This corresponds to a free energy penalty of approximately 15 kJ mol⁻¹ bp⁻¹ per mismatch, resulting in an apparent binding constant of only 0.02 M⁻¹ per mismatch [8]. The impact of mismatches exhibits dependency on neighboring base pairs, with increasing stability of surrounding regions decreasing the effect of introduced mismatches [8].
Hybridization Kinetics and Concentration Dependencies
Kinetic studies reveal that peptide nucleic acid binding to double-stranded deoxyribonucleic acid follows pseudo-first-order kinetics, with the pseudo-first-order rate constant exhibiting a power law dependence on peptide nucleic acid concentration with exponents ranging from 2 to 3 [12]. Under physiological conditions containing major cellular mono- and polycations, 50% binding of peptide nucleic acid to complementary targets occurs within one hour at concentrations of 350 μM, while complete binding requires concentrations up to 500 μM [12]. The binding kinetics demonstrate remarkable selectivity, with peptide nucleic acid sequences showing no detectable binding to targets containing single mismatches under identical conditions [12].
Table 2: Sequence-Specific Recognition and Binding Kinetics
| Parameter | Value Range | Conditions | Reference |
|---|---|---|---|
| Melting temperature drop (single mismatch) | 15-20°C | 9-12 mer duplexes | [8] |
| Peptide nucleic acid concentration for 50% deoxyribonucleic acid binding | 350 μM | Physiological buffer | [12] |
| Peptide nucleic acid concentration (complete binding) | 500 μM | Physiological buffer | [12] |
| Invasion complex formation time | Minutes to hours | Low salt conditions | [13] [12] |
Backbone-Dependent Hybridization Properties
The unique aminoethylglycine backbone of peptide nucleic acids creates distinct hybridization properties compared to natural nucleic acids [14] [15]. The backbone spacing of approximately 5.7 Å matches optimally with the phosphate spacing in A-form ribonucleic acid, enabling efficient hydrogen-bonding interactions between peptide nucleic acid backbone amides and ribonucleic acid phosphate oxygens [14] [16]. This structural complementarity results in peptide nucleic acid-ribonucleic acid duplexes adopting A-like helical conformations, while peptide nucleic acid-deoxyribonucleic acid duplexes form intermediate structures distinct from both A and B forms [17].
Triplex Invasion Mechanisms in Double-Stranded Nucleic Acid Systems
Triplex Formation Pathways
Peptide nucleic acids containing adenine building blocks like Fmoc-pna-a(bhoc)-oh participate in unique triplex invasion mechanisms that enable recognition of double-stranded deoxyribonucleic acid targets [18] [13]. The invasion process occurs through a distinctive "triplex-first" mechanism, wherein homopyrimidine peptide nucleic acids initially form conventional Hoogsteen triplex structures with the major groove of double-stranded deoxyribonucleic acid before proceeding to complete strand displacement [13]. This mechanism involves the formation of transient tertiary complexes between double-stranded deoxyribonucleic acid and peptide nucleic acid oligomers, facilitated by small-scale opening of the double helix through deoxyribonucleic acid "breathing" dynamics [19] [20].
Strand Displacement Dynamics
The strand displacement process requires the formation of stable peptide nucleic acid-deoxyribonucleic acid-peptide nucleic acid triplexes, where one peptide nucleic acid strand forms an antiparallel Watson-Crick duplex with the purine-rich strand of deoxyribonucleic acid while the second peptide nucleic acid forms a parallel Hoogsteen triplex [21]. This unique binding mode results in displacement of the pyrimidine-rich deoxyribonucleic acid strand as an unpaired loop [18]. The invasion complex formation demonstrates significant sequence selectivity, with multiple structurally different invasion complexes characterized for peptide nucleic acids of varying lengths [13].
Ionic Strength Effects on Invasion
The efficiency of triplex invasion exhibits strong dependence on ionic strength conditions, with increasing salt concentrations severely inhibiting invasion complex formation while favoring conventional triplex structures [13]. Low ionic strength conditions promote invasion mechanisms, whereas physiological salt concentrations require significantly higher peptide nucleic acid concentrations to achieve comparable invasion efficiency [13]. This ionic strength sensitivity distinguishes invasion mechanisms from conventional hybridization processes and represents a critical factor in the biological application of peptide nucleic acids [13].
Length-Dependent Invasion Properties
Systematic studies of peptide nucleic acids ranging from decamers to pentadecamers reveal length-dependent invasion characteristics, with longer peptide nucleic acids forming multiple structurally distinct invasion complexes [13]. Decameric peptide nucleic acids typically form single invasion complexes, while dodecameric sequences generate two distinct structures and pentadecameric peptide nucleic acids produce more than five different invasion complexes [13]. The kinetics of invasion also demonstrate length dependency, with conventional triplex formation occurring much faster than invasion complex formation across all peptide nucleic acid lengths [13].
Nucleation and Breathing Mechanisms
Deoxyribonucleic acid breathing dynamics play a crucial role in facilitating peptide nucleic acid invasion through transient opening of base pairs that create nucleation sites for initial peptide nucleic acid binding [22] [23]. The nucleation process involves approximately four base pairs in the target sequence, with the propensity for local transient openings being sequence-dependent and influenced by thermal fluctuations [24] [22]. Base pair opening preferentially occurs toward the major groove, with sequence-specific dynamics determining the accessibility of potential binding sites [25] [26].
Table 3: Triplex Invasion Mechanism Parameters
| Structural Feature | Measurement | Significance | Reference |
|---|---|---|---|
| Deoxyribonucleic acid breathing nucleation size | ~4 base pairs | Critical nucleation event | [24] [22] |
| Base pair opening preference | Major groove opening | Sequence-dependent dynamics | [26] [25] |
| Triplex formation vs invasion kinetics | Triplex >> Invasion | Kinetic pathway preference | [13] |
| Salt effect on invasion | Severely inhibited | High ionic strength sensitivity | [13] |
Thermodynamic Stability Profiles of Peptide Nucleic Acid:Deoxyribonucleic Acid Chimeric Structures
Differential Scanning Calorimetry Analysis
Comprehensive thermodynamic characterization using differential scanning calorimetry reveals that peptide nucleic acid-deoxyribonucleic acid duplexes exhibit significantly enhanced thermal stability compared to corresponding deoxyribonucleic acid-deoxyribonucleic acid duplexes [10] [11]. The transition temperatures for 10 base pair peptide nucleic acid-deoxyribonucleic acid duplexes range from 329 to 343 K, representing increases of 7-20 K compared to corresponding deoxyribonucleic acid duplexes [10] [11]. Calorimetric transition enthalpies for peptide nucleic acid-deoxyribonucleic acid systems span 209 ± 6 to 283 ± 37 kJ mol⁻¹, demonstrating substantial energetic differences from deoxyribonucleic acid-deoxyribonucleic acid duplexes which range from 72 ± 29 to 236 ± 24 kJ mol⁻¹ [10] [11].
Sequence-Dependent Stability Variations
The thermodynamic stability of peptide nucleic acid-deoxyribonucleic acid duplexes demonstrates pronounced sequence dependency, particularly regarding the distribution of purine and pyrimidine bases between the two strands [27]. Peptide nucleic acid duplexes containing purine-rich peptide nucleic acid strands exhibit significantly greater thermal stability than those with pyrimidine-rich peptide nucleic acid components [27]. For homopurine-homopyrimidine sequences, the thermal stability of peptide nucleic acid(purine)-deoxyribonucleic acid(pyrimidine) duplexes reaches approximately 70°C, while peptide nucleic acid(pyrimidine)-deoxyribonucleic acid(purine) duplexes typically exhibit melting temperatures around 30°C [27].
Enthalpy-Entropy Compensation
Thermodynamic analysis reveals complex enthalpy-entropy compensation behavior in peptide nucleic acid-deoxyribonucleic acid hybridization reactions [27] [7]. Peptide nucleic acid sequences generally exhibit tighter binding affinities than corresponding deoxyribonucleic acid sequences, resulting from smaller entropy changes during hybridization [7] [9]. The binding enthalpies for peptide nucleic acid-deoxyribonucleic acid interactions range from -77 kJ mol⁻¹ for peptide nucleic acid(guanine-thymine) combinations to -194 kJ mol⁻¹ for peptide nucleic acid(cytosine-guanine) sequences [7] [9].
Structural Contributions to Stability
The enhanced stability of peptide nucleic acid-deoxyribonucleic acid duplexes derives from multiple structural factors, including the absence of electrostatic repulsion due to the neutral peptide nucleic acid backbone and optimized hydrogen bonding patterns [27] [15]. The hydrogen bond strengths are significantly increased by peptide nucleic acid backbones compared to natural nucleic acid systems, with the type of backbone exerting substantial influence on the energetic properties of base pairs [15]. The conformational rigidity of peptide nucleic acids, enhanced by backbone constraints, limits the ability of peptide nucleic acid strands to adopt alternative conformations and ultimately increases selectivity in molecular recognition [17].
Temperature-Dependent Thermodynamic Properties
Extrapolation of thermodynamic parameters from melting temperatures to ambient conditions reveals significant discrepancies between differential scanning calorimetry and isothermal titration calorimetry measurements, attributed to temperature-dependent structural changes in single-stranded peptide nucleic acid conformations [10] [11]. The thermodynamic differences in single-strand structures between ambient and transition temperatures contribute substantially to the observed variations, with conformational changes in peptide nucleic acid strands playing a more significant role than corresponding changes in deoxyribonucleic acid strands [10] [11].
Table 4: Thermodynamic Stability Parameters
| Thermodynamic Parameter | Peptide Nucleic Acid-Deoxyribonucleic Acid | Deoxyribonucleic Acid-Deoxyribonucleic Acid | Reference |
|---|---|---|---|
| Transition temperature range | 329-343 K | 322-323 K | [10] [11] |
| Calorimetric enthalpy range | 209-283 kJ mol⁻¹ | 72-236 kJ mol⁻¹ | [10] [11] |
| Binding enthalpy range | -77 to -194 kJ mol⁻¹ | -124 to -223 kJ mol⁻¹ | [7] [9] |
| Purine-rich peptide nucleic acid melting temperature | ~70°C | N/A | [27] |
| Pyrimidine-rich peptide nucleic acid melting temperature | ~30°C | N/A | [27] |
XLogP3
Dates
Explore Compound Types