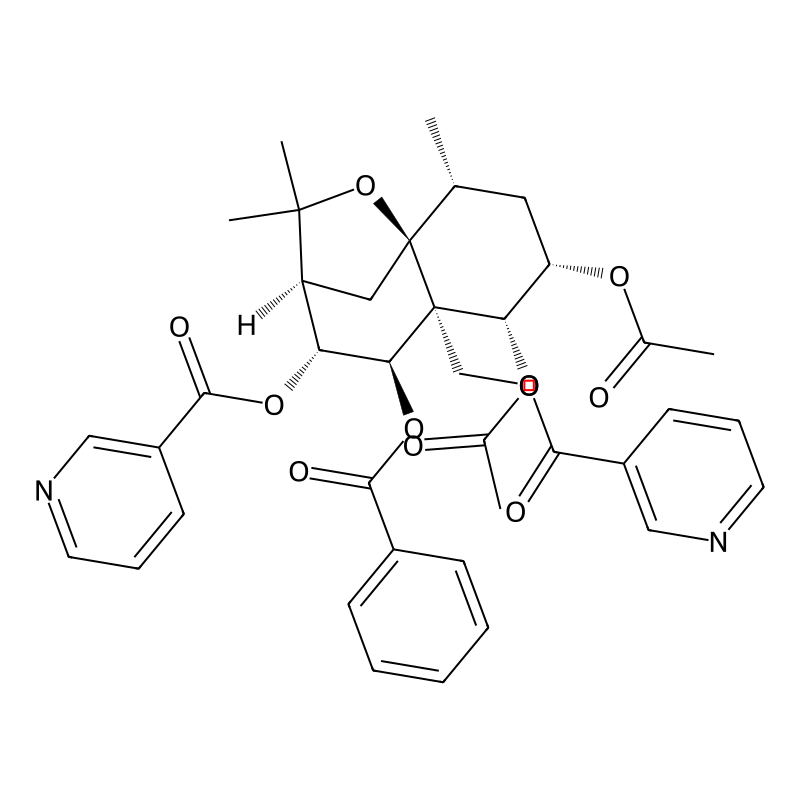
Catheduline E2
Content Navigation
CAS Number
Product Name
IUPAC Name
Molecular Formula
Molecular Weight
InChI
InChI Key
SMILES
Canonical SMILES
Isomeric SMILES
Catheduline E2 (CAS: 61231-06-9) is a high-molecular-weight, highly oxygenated sesquiterpene polyester alkaloid originally isolated from Catha edulis. Structurally, it consists of a dihydro-β-agarofuran (euonyminol) core that is specifically esterified with two acetate, one benzoate, and two nicotinate moieties, resulting in a molecular weight of 700.7 g/mol[1]. In procurement and industrial research, Catheduline E2 is primarily sourced as a high-purity analytical reference standard. It is essential for the chemotaxonomic profiling of complex botanical extracts, the calibration of advanced mass spectrometry methods, and as a rigorous late-stage benchmark in the total synthesis of agarofuran macrolides[2]. Its precise esterification pattern makes it a far more specific and stable target for standardization than simple monoamine alkaloids or crude plant mixtures.
References
Substituting Catheduline E2 with generic khat alkaloids (such as cathinone) or unesterified precursor cores (like euonyminol) fundamentally compromises analytical and synthetic workflows [1]. Cathinone is highly volatile and degrades rapidly into cathine upon plant harvesting or drying, making it an unreliable marker for the long-term stability testing of botanical extracts. Conversely, while euonyminol provides the basic nonahydroxydihydro-β-agarofuran skeleton, it lacks the complex steric hindrance and electronic environment of the fully esterified macrolide [2]. Using unesterified cores fails to accurately calibrate liquid chromatography retention times or mass spectrometry fragmentation patterns for intact cathedulins, necessitating the procurement of the exact, fully functionalized Catheduline E2 standard.
Long-Term Stability as an Analytical Marker
For the standardization of botanical extracts, marker stability is critical. Catheduline E2 remains intact in dried or lyophilized plant matrices over extended periods (>months). In contrast, the simple phenylalkylamine cathinone degrades rapidly (often within 48 hours post-harvest) into cathine and norephedrine[1]. This difference in degradation kinetics means that Catheduline E2 provides a reliable quantitative marker for assessing the original phytochemical profile of aged or processed samples.
| Evidence Dimension | Chemical stability in dried botanical matrix |
| Target Compound Data | Catheduline E2: Stable for >months in dried/processed samples |
| Comparator Or Baseline | Cathinone: Rapid degradation within 48 hours of harvesting |
| Quantified Difference | Orders of magnitude longer shelf-life as an intact analytical marker |
| Conditions | Post-harvest drying and long-term extract storage |
Buyers developing QA/QC protocols for botanical extracts must procure Catheduline E2 to ensure their reference standards do not degrade during routine laboratory storage.
Mass Spectrometry Ionization and Calibration Accuracy
Accurate LC-MS/MS quantification of complex macrolides requires standards that mimic the target's ionization behavior. Catheduline E2 (MW 700.7 g/mol) readily forms characteristic doubly protonated [M+2H]2+ ions (m/z ~351) during electrospray ionization, a feature shared by the broader cathedulin family [1]. Simple monoamine alkaloids only form singly charged [M+H]+ ions at low m/z ranges. Using Catheduline E2 allows analytical chemists to accurately tune collision energies and detect doubly charged precursor ions, which cannot be achieved when using simple alkaloid comparators.
| Evidence Dimension | Primary MS ionization species |
| Target Compound Data | Catheduline E2: Forms distinct doubly protonated [M+2H]2+ ions (m/z ~351) |
| Comparator Or Baseline | Simple alkaloids (Cathinone): Form only singly charged [M+H]+ ions |
| Quantified Difference | Enables tuning for multi-charged high-mass species |
| Conditions | Electrospray ionization (ESI) in LC-MS/MS workflows |
Procuring Catheduline E2 is essential for laboratories needing to calibrate mass spectrometers for the detection of high-molecular-weight, multi-charged secondary metabolites.
Regioselective Validation in Total Synthesis
In the total synthesis of dihydro-β-agarofurans, achieving the correct esterification pattern is a major late-stage hurdle. Catheduline E2 features a specific arrangement of two acetates, one benzoate, and two nicotinates on the euonyminol core [1]. While the unesterified euonyminol core proves the construction of the trans-decalin skeleton, it cannot validate the success of late-stage regioselective acylation protocols. Procuring Catheduline E2 provides the exact NMR and chromatographic reference required to confirm the successful, specific functionalization of the 9 available hydroxyl groups.
| Evidence Dimension | Utility for late-stage synthetic validation |
| Target Compound Data | Catheduline E2: Validates complex regioselective penta-esterification |
| Comparator Or Baseline | Euonyminol: Only validates the unesterified polyol core |
| Quantified Difference | Provides reference data for 5 specific ester linkages absent in the core |
| Conditions | NMR and HPLC validation of synthetic end-products |
Synthetic chemistry groups must procure the fully esterified Catheduline E2 to definitively prove the regioselective success of their macrolide synthesis campaigns.
Chemotaxonomic Profiling and Forensic Standardization
Because Catheduline E2 is stable for months compared to volatile phenylalkylamines (which degrade in 48 hours), it is a highly reliable reference standard for the forensic and chemotaxonomic profiling of Catha edulis and other plants (such as Piper sarmentosum) [1]. It allows for the accurate standardization of extracts without the risk of marker degradation during sample transit or storage.
LC-MS/MS Method Development for Complex Polyesters
Given its ability to form doubly protonated ions at m/z ~351, Catheduline E2 is highly suited for tuning LC-MS/MS instruments [2]. Analytical laboratories use it to establish retention times, optimize collision energies, and map fragmentation pathways for the broader class of high-molecular-weight agarofuran alkaloids.
Late-Stage Benchmark for Agarofuran Total Synthesis
For synthetic organic chemistry groups developing novel routes to highly oxygenated macrolides, Catheduline E2 serves as a definitive proof-of-structure reference [3]. It provides the necessary 1H/13C NMR and chromatographic data to confirm that late-stage regioselective esterifications on the euonyminol core have been executed correctly.
References
- [1] Bioactive-Rich Piper sarmentosum Aqueous Extract Mitigates Osteoarthritic Pathology by Enhancing Anabolic Activity and Attenuating NO-Driven Catabolism in Human Chondrocytes. PMC (2026).
- [2] Use of doubly protonated molecules in the analysis of cathedulins in crude extracts of khat (Catha edulis) by liquid chromatography/serial mass spectrometry. Rapid Commun Mass Spectrom.
- [3] Enantioselective Synthesis of Euonyminol. Journal of the American Chemical Society (2021).
XLogP3
Wikipedia
Dates
Explore Compound Types