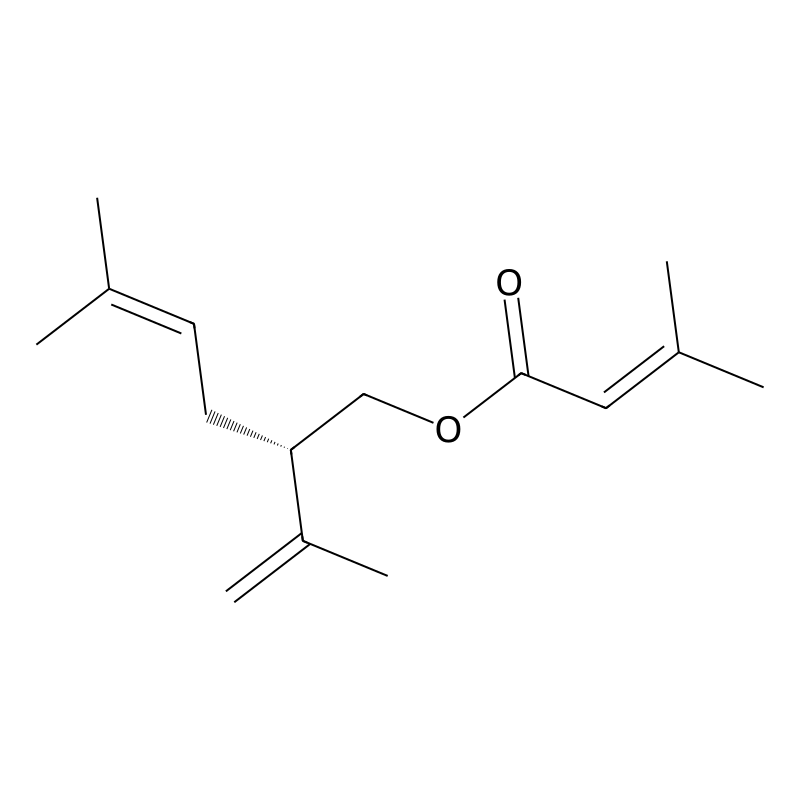
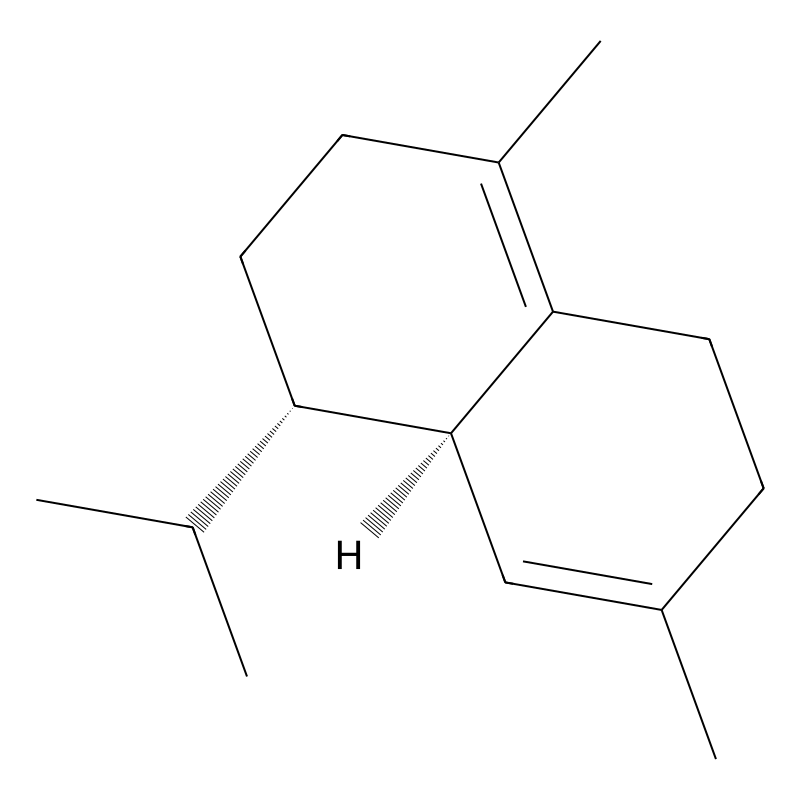
(+)-delta-Cadinene
Content Navigation
Researchers using crude cadinene mixtures face co-elution of α-, γ-isomers, compromising GC-MS quantification and enzymatic assay validity. This ≥95% pure (+)-delta-Cadinene standard solves these challenges: • Enables baseline-resolved GC-MS differentiation of δ-cadinene isomer for accurate metabolomic profiling. • Serves as stereospecific substrate for (+)-delta-cadinene synthase (DCS) in gossypol biosynthesis, essential for kinetic modeling. • Delivers consistent solubility (30 mg/mL DMSO) for reliable dose-response studies. Global shipping with CoA.
CAS Number
Product Name
IUPAC Name
Molecular Formula
Molecular Weight
InChI
InChI Key
SMILES
Synonyms
Canonical SMILES
Isomeric SMILES
Purity
Package Size
(+)-delta-Cadinene (CAS 483-76-1) is a highly purified bicyclic sesquiterpene utilized primarily as a stereospecific analytical standard and an enzymatic substrate in agricultural biotechnology and pharmacognosy. Unlike crude sesquiterpene mixtures or essential oil extracts, the isolated (+)-enantiomer provides a defined molecular weight of 204.35 g/mol and a standardized solubility profile (30 mg/mL in DMSO or DMF) . Procurement of the ≥95% pure compound is critical for researchers requiring baseline-resolved chromatographic data or absolute stereochemical fidelity when mapping plant defense pathways, specifically the biosynthesis of gossypol and related phytoalexins [1].
Research Fit
Substituting pure (+)-delta-Cadinene with crude botanical extracts (such as cade oil) or mixed cadinene isomers inherently compromises both analytical resolution and enzymatic assay validity. Essential oils often contain up to 27% delta-cadinene but are heavily contaminated with alpha- and gamma-isomers that co-elute in standard GC-MS workflows, preventing accurate absolute quantification [1]. Furthermore, in biosynthetic studies involving (+)-delta-cadinene synthase (DCS), the enzyme exhibits strict stereospecificity; racemic mixtures or (-)-delta-cadinene fail to act as biologically relevant intermediates for downstream gossypol production [2]. Consequently, utilizing non-purified or stereochemically ambiguous substitutes introduces severe reproducibility artifacts in both metabolomic profiling and in vitro bioassays.
Substitution Risk
Enzyme Stereospecificity in Biosynthesis
In assays evaluating the catalytic fidelity of sesquiterpene cyclases, the pure (+)-enantiomer is the exclusive biological intermediate. (+)-delta-cadinene synthase (DCS) converts farnesyl diphosphate into (+)-delta-cadinene with >98% exclusivity, sharply contrasting with promiscuous cyclases (e.g., gamma-humulene synthase) that yield over 50 mixed products [1]. Utilizing the pure (+)-isomer is therefore mandatory for downstream kinetic modeling.
| Evidence Dimension | Product/Intermediate Exclusivity |
| Target Compound Data | >98% stereospecific intermediate formation |
| Comparator Or Baseline | Promiscuous terpene cyclases (52 mixed products) |
| Quantified Difference | Near-absolute stereochemical fidelity vs. highly mixed output |
| Conditions | In vitro enzymatic assays with Gossypium arboreum DCS |
Procuring the exact (+)-enantiomer ensures that metabolic engineering and kinetic studies accurately reflect the native gossypol biosynthesis pathway without chiral interference.
Reproducible Antimicrobial Assays
For pharmacological screening, utilizing ≥95% pure (+)-delta-Cadinene eliminates the antagonistic or synergistic effects found in crude plant extracts. The pure compound demonstrates a precise Minimum Inhibitory Concentration (MIC) of 31.25 µg/mL against S. pneumoniae . In contrast, generic essential oil mixtures yield highly variable MICs dependent on seasonal and extraction variables, rendering them unsuitable for rigorous dose-response modeling.
| Evidence Dimension | Minimum Inhibitory Concentration (MIC) |
| Target Compound Data | Exact MIC of 31.25 µg/mL |
| Comparator Or Baseline | Crude botanical extracts (variable/undefined MICs) |
| Quantified Difference | Defined single-molecule threshold vs. batch-dependent variability |
| Conditions | In vitro antimicrobial screening against S. pneumoniae |
Provides a reliable, reproducible baseline for high-throughput antimicrobial drug discovery workflows.
Solvent Compatibility for HTS
The physical handling and formulation of pure (+)-delta-Cadinene significantly outperforms crude terpene resins. The pure liquid compound achieves a standardized solubility of 30 mg/mL in common polar aprotic solvents like DMSO and DMF, as well as Ethanol . Crude extracts often suffer from unpredictable precipitation or require harsh emulsifiers that can induce cytotoxicity in sensitive cell lines (such as OVCAR-3).
| Evidence Dimension | Solubility in DMSO/DMF |
| Target Compound Data | 30 mg/mL |
| Comparator Or Baseline | Crude terpene resins (variable solubility/precipitation) |
| Quantified Difference | Consistent 30 mg/mL solubility vs. unpredictable formulation behavior |
| Conditions | Standard laboratory solvent preparation at room temperature |
Ensures uniform dosing and prevents solvent-induced artifacts in microtiter plate-based cellular assays.
Chemotaxonomy & GC-MS Calibration
Due to its high purity and defined stereochemistry, (+)-delta-Cadinene is the required standard for calibrating GC-MS instruments in metabolomic profiling. It allows researchers to accurately differentiate the (+)-isomer from co-eluting alpha- and gamma-cadinenes, which is essential for mapping plant chemotypes and validating agricultural phenotypes [1].
Phytoalexin Biosynthesis & Metabolic Engineering
As the exclusive intermediate generated by (+)-delta-cadinene synthase, this compound is indispensable for in vitro enzymatic assays. It serves as the baseline substrate for downstream studies investigating the gossypol biosynthesis pathway, enabling precise kinetic modeling that racemic mixtures cannot support [2].
Reproducible Pharmacological Screening
The compound's standardized solubility (30 mg/mL in DMSO) and defined biological activity make it a precise choice for oncology and antimicrobial research. It is utilized to generate reliable dose-response curves, such as determining apoptosis induction in OVCAR-3 human ovarian cancer cells at defined 10-100 µM concentrations, free from the interference of crude extract contaminants .
Application Fit Matrix
XLogP3
Exact Mass
Monoisotopic Mass
Boiling Point
Heavy Atom Count
UNII
Other CAS
Use Classification
2. Govindarajan M, Rajeswary M, Benelli G. δ-Cadinene, Calarene and .δ-4-Carene from Kadsura heteroclita Essential Oil as Novel Larvicides Against Malaria, Dengue and Filariasis Mosquitoes. Comb Chem High Throughput Screen. 2016;19(7):565-71. doi: 10.2174/1386207319666160506123520. PMID: 27151483.
3. Wang YH, Davila-Huerta G, Essenberg M. 8-Hydroxy-(+)-delta-cadinene is a precursor to hemigossypol in Gossypium hirsutum. Phytochemistry. 2003 Sep;64(1):219-25. doi: 10.1016/s0031-9422(03)00270-x. PMID: 12946420.
4. Guo X, Shang X, Li B, Zhou XZ, Wen H, Zhang J. Acaricidal activities of the essential oil from Rhododendron nivale Hook. f. and its main compund, δ-cadinene against Psoroptes cuniculi. Vet Parasitol. 2017 Mar 15;236:51-54. doi: 10.1016/j.vetpar.2017.01.028. Epub 2017 Feb 1. PMID: 28288764.
5. Karami A. Essential oil composition of Ajuga comata Stapf. from Southern Zagros, Iran. Nat Prod Res. 2017 Feb;31(3):359-361. doi: 10.1080/14786419.2016.1236094. Epub 2016 Sep 22. PMID: 27653644.
Explore Compound Types