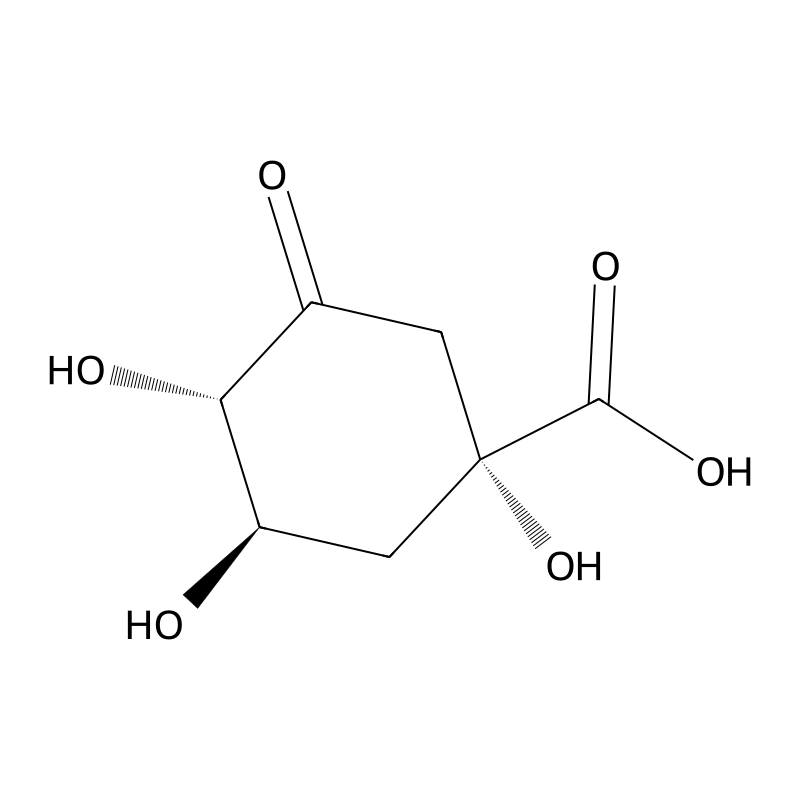
3-Dehydroquinic acid
Content Navigation
CAS Number
Product Name
IUPAC Name
Molecular Formula
Molecular Weight
InChI
InChI Key
SMILES
Synonyms
Canonical SMILES
Isomeric SMILES
3-Dehydroquinic acid (CAS 10534-44-8) is a pivotal carbocyclic intermediate in the shikimate pathway, distinguished from its structural analog quinic acid by the presence of a C-3 ketone group[1]. As the obligate native substrate for 3-dehydroquinate dehydratase (DHQase), it is essential for the biosynthesis of aromatic amino acids in bacteria, fungi, and plants[2]. In procurement and industrial research, highly pure 3-dehydroquinic acid is prioritized over crude extracts or synthetic proxies because its exact stereochemistry and functional group presentation are strictly required to accurately measure enzymatic kinetics, screen novel antimicrobial or herbicidal inhibitors, and map metabolic flux in engineered microbial strains [3].
Research Fit
Generic substitution with upstream precursors like quinic acid or downstream products like 3-dehydroshikimic acid completely fails in functional assays due to strict enzymatic specificity [1]. Quinic acid lacks the C-3 ketone moiety, rendering it incapable of forming the essential covalent Schiff base (imine) intermediate with the catalytic lysine residue of Type I DHQase, resulting in zero catalytic turnover [2]. Similarly, utilizing crude microbial lysates introduces competing enzymes (such as DHQ synthase or shikimate dehydrogenase) that rapidly alter substrate concentrations, destroying assay reproducibility [3]. Consequently, procuring pure 3-dehydroquinic acid is mandatory for isolating DHQase activity, ensuring reliable baseline kinetics, and avoiding the false-positive inhibition signals common with off-target structural analogs.
Substitution Risk
Direct substrate for DHQase; enters shikimate pathway without prior modification.
Requires oxidation to DHQ via quinoprotein dehydrogenase before DHQase recognition; introduces additional enzymatic dependency.
Downstream dehydration product; not recognized as substrate by DHQase; redox state and pathway junction context differ.
References
- [1] Wikipedia contributors. '3-dehydroquinate dehydratase.' Wikipedia, The Free Encyclopedia.
- [2] González-Bello, C., et al. 'Quinate-based ligands for irreversible inactivation of the bacterial virulence factor DHQ1 enzyme.' Digital CSIC (2023).
- [3] UniProt Consortium. 'aroD - 3-dehydroquinate dehydratase - Salmonella typhi.' UniProtKB.
Substrate Competence and Schiff-Base Formation in Type I DHQase Assays
In functional assays targeting Type I DHQase, 3-Dehydroquinic acid demonstrates a high catalytic turnover (kcat = 48 to 255 s⁻¹) due to its ability to form a covalent imine intermediate [1]. In contrast, quinic acid, which lacks the C-3 ketone, exhibits zero turnover and cannot initiate the catalytic cycle[2].
| Evidence Dimension | Catalytic turnover (kcat) via Schiff-base intermediate |
| Target Compound Data | kcat = 48 to 255 s⁻¹ (forms essential covalent imine intermediate) |
| Comparator Or Baseline | Quinic acid (kcat = 0 s⁻¹) |
| Quantified Difference | Absolute requirement of the C-3 ketone for catalytic activation; quinic acid yields zero turnover. |
| Conditions | Purified Type I DHQase (e.g., S. aureus), in vitro kinetic assay at pH 7.2-8.0. |
Procurement of exact DHQ is non-negotiable for target-based antimicrobial screening against Type I DHQase, as structural analogs completely fail to initiate turnover.
Spontaneous Degradation Control and Handling Stability
3-Dehydroquinic acid is susceptible to non-enzymatic dehydration into 3-dehydroshikimic acid, which creates high background noise at 234 nm. Maintaining the compound at a mildly acidic pH (e.g., pH 5.0) significantly suppresses this spontaneous degradation compared to physiological or alkaline pH (pH ≥ 7.5)[1], ensuring a stable baseline for spectrophotometric assays [2].
| Evidence Dimension | Non-enzymatic dehydration rate to 3-dehydroshikimic acid |
| Target Compound Data | High stability with negligible spontaneous dehydration at pH 5.0 |
| Comparator Or Baseline | 3-Dehydroquinic acid at pH ≥ 7.5 |
| Quantified Difference | Rapid non-enzymatic conversion to 3-dehydroshikimic acid at alkaline pH, creating high background absorbance at 234 nm. |
| Conditions | Aqueous buffer storage and assay preparation monitored via 234 nm UV absorbance. |
Guides formulation and storage protocols; buyers must ensure proper handling conditions to prevent the costly loss of the active substrate before assay execution.
Kinetic Differentiation for Type I vs Type II Target Profiling
3-Dehydroquinic acid serves as a universal substrate for both Type I and Type II DHQase, but yields vastly different kinetic profiles. In Type I enzymes (bacterial), it exhibits a low micromolar Michaelis constant (Km = 18 - 54 µM)[1]. In Type II enzymes (fungal/mycobacterial), the Km is typically one to two orders of magnitude higher [2].
| Evidence Dimension | Michaelis constant (Km) |
| Target Compound Data | Km = 18 - 54 µM (Type I DHQase) |
| Comparator Or Baseline | Type II DHQase assays (Km = >500 µM to millimolar range) |
| Quantified Difference | 10x to 100x higher binding affinity in Type I (cis-dehydration) vs Type II (trans-dehydration) enzymes. |
| Conditions | Comparative enzymatic profiling across bacterial (Type I) and fungal/mycobacterial (Type II) targets. |
Validates the use of DHQ as a universal but kinetically distinct probe for differentiating Type I vs Type II targets in broad-spectrum drug discovery.
High-Throughput Antimicrobial Screening
Utilizing 3-dehydroquinic acid as the native substrate to identify competitive or irreversible inhibitors of DHQase in pathogens like MRSA or Salmonella typhi, monitored via real-time UV absorbance at 234 nm [1].
Structural Biology and Rational Drug Design
Employing the pure compound for co-crystallization or molecular dynamics simulations with Type I DHQase to map the catalytic lysine and design transition-state analogs [2].
Metabolic Flux Analysis in Engineered Microbes
Using the compound as an analytical reference standard in HPLC to quantify intermediate pooling and optimize the biosynthesis of high-value aromatic compounds in industrial fermentation [3].
Application Fit Matrix
References
- [1] ResearchGate. 'A Target to Combat Antibiotic Resistance: Biochemical and Biophysical Characterization of 3-Dehydroquinate Dehydratase from Methicillin-Resistant Staphylococcus aureus.' (2024).
- [2] González-Bello, C., et al. 'Quinate-based ligands for irreversible inactivation of the bacterial virulence factor DHQ1 enzyme.' Digital CSIC (2023).
- [3] BRENDA Enzyme Database. Information on EC 4.2.1.10 - 3-dehydroquinate dehydratase.
Physical Description
XLogP3
Hydrogen Bond Acceptor Count
Hydrogen Bond Donor Count
Exact Mass
Monoisotopic Mass
Heavy Atom Count
UNII
Wikipedia
Explore Compound Types