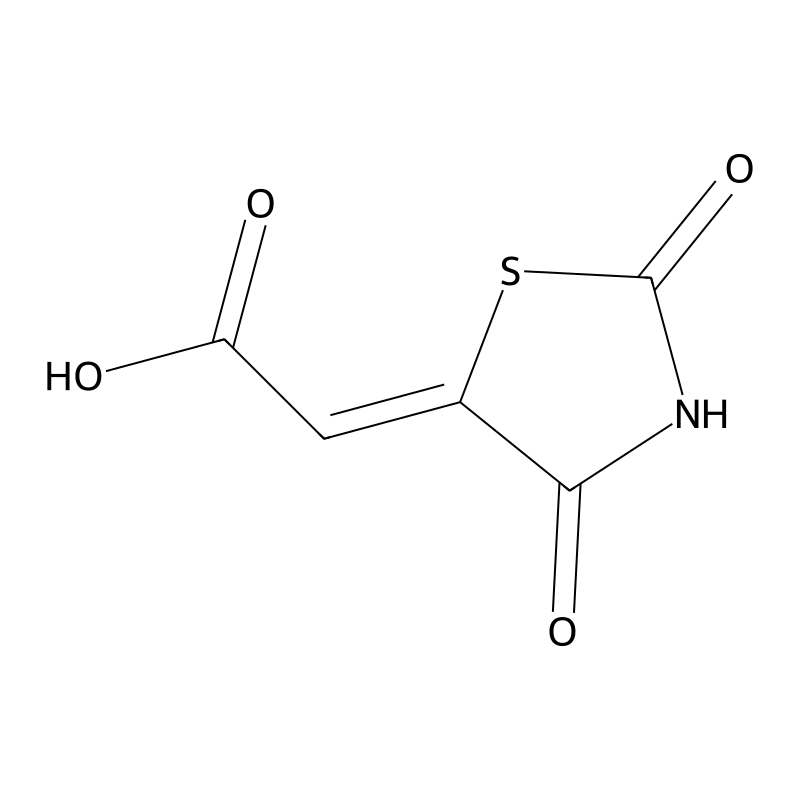
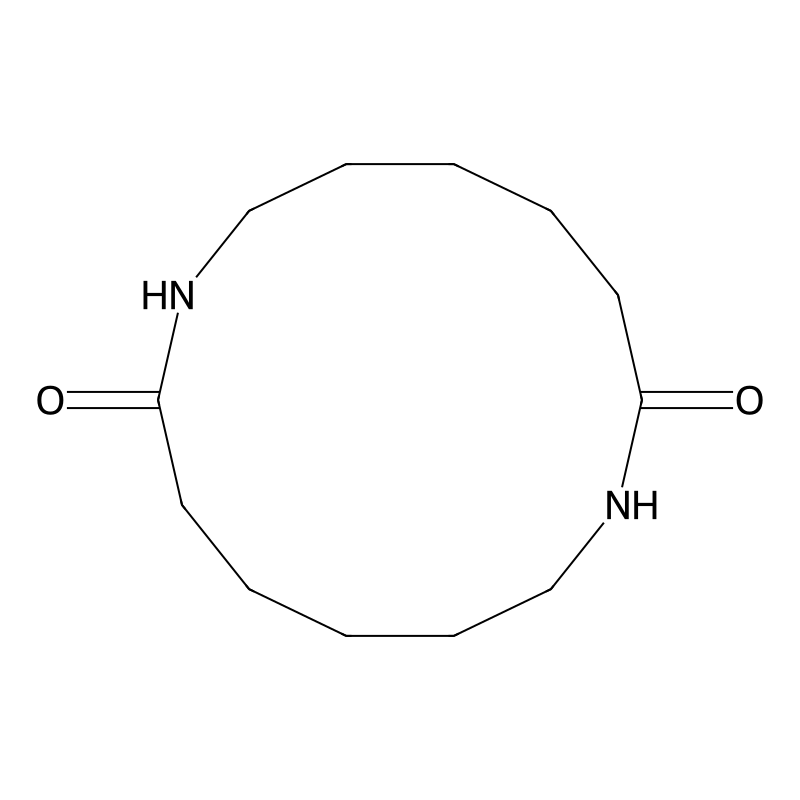
1,8-Diazacyclotetradecane-2,9-dione
Content Navigation
QA/QC labs quantifying extractable impurities in Polyamide-6 melt-spinning face inconsistent results from crude oligomer mixtures. This high-purity cyclic dimer (CAS 56403-09-9) provides exact stoichiometric control and distinct crystallization behavior critical for accurate HPLC/NMR calibration.
- Quantifies the primary agglomerate-causing species with exact α/β crystal forms.
- Enables precise ligand design with dual amide coordination, essential for robust MOFs and supramolecular assemblies.
- Thermal stability >340 °C ensures integrity under high-temperature processing.
Procurement from SMolecule ensures batch-to-batch consistency for reliable analytical and synthetic workflows.
CAS Number
Product Name
IUPAC Name
Molecular Formula
Molecular Weight
InChI
InChI Key
SMILES
Synonyms
Canonical SMILES
Purity
Package Size
1,8-Diazacyclotetradecane-2,9-dione (CAS 56403-09-9), commonly known as the cyclic dimer of epsilon-caprolactam, is a 14-membered macrocyclic diamide. In industrial and analytical contexts, it serves as a critical reference standard for quantifying extractable impurities in Polyamide-6 production, where its distinct crystallization behavior directly impacts melt-spinning efficiency. Beyond its role as an analytical benchmark, the compound's rigid macrocyclic structure, dual amide functionalities, and exceptional thermal stability make it a specialized building block for supramolecular assemblies, metal-organic frameworks (MOFs), and coordination chemistry. Procurement of the high-purity compound ensures reproducible coordination environments and exact stoichiometric control that cannot be achieved with crude oligomer mixtures or linear precursors .
Research & Procurement Fit
Substituting 1,8-diazacyclotetradecane-2,9-dione with its monomeric precursor (epsilon-caprolactam) or crude Nylon-6 oligomer mixtures fundamentally compromises both analytical and synthetic workflows. The monomer lacks the 14-membered macrocyclic cavity and exhibits a drastically lower melting point, rendering it useless for high-temperature supramolecular applications or macrocyclic coordination. Crude oligomer extracts, while cheap, contain variable ratios of linear and cyclic species, making them unsuitable for precise stoichiometric ligand design or quantitative QA/QC calibration. Furthermore, attempting to substitute it with other 14-membered macrocycles like cyclam (a pure tetramine) fails because the diamide functionality of 1,8-diazacyclotetradecane-2,9-dione provides a completely different electronic environment, shifting coordination from basic amine nitrogens to amide oxygen/nitrogen sites, which is critical for specific MOF topologies and catalytic metal stabilization [1].
Substitution Risk
Thermal Stability and Phase Transition
1,8-Diazacyclotetradecane-2,9-dione exhibits exceptional thermal stability driven by strong intermolecular hydrogen bonding, forming distinct alpha and beta crystal structures. Quantitative thermal analysis demonstrates that the pure cyclic dimer has a melting point of approximately 341–347 °C, which is over 270 °C higher than its monomeric counterpart, epsilon-caprolactam (Tm = 69 °C). Furthermore, the cyclic dimer undergoes a specific endothermic solid-state transition from beta to alpha crystals at ~242 °C before melting [1]. This high-temperature stability and predictable phase transition make the pure compound indispensable for high-temperature supramolecular synthesis and for accurately modeling the agglomeration phenomena that disrupt industrial melt-spinning processes.
| Evidence Dimension | Melting Point and Phase Transition Temperature |
| Target Compound Data | Tm = 341–347 °C; β-to-α transition at ~242 °C |
| Comparator Or Baseline | Epsilon-caprolactam (Tm = 69 °C) |
| Quantified Difference | >270 °C increase in melting point |
| Conditions | Solid-state differential scanning calorimetry (DSC) and XRD |
Procuring the pure cyclic dimer is essential for high-temperature material applications and for calibrating models of solid-state agglomeration in polymer processing.
Hydrolytic Ring-Opening Resistance
The 14-membered ring of 1,8-diazacyclotetradecane-2,9-dione is highly resistant to hydrolytic ring-opening compared to standard lactams. Thermodynamic and kinetic modeling shows that the amino-assisted ring-opening of the cyclic dimer represents the highest free energy barrier (the rate-determining step) in polyamide depolymerization sequences [1]. While epsilon-caprolactam readily polymerizes under standard hydrolytic conditions at 250 °C, the cyclic dimer remains largely intact, requiring specialized lanthanide trisamido catalysts (e.g., Ln(N(TMS)2)3) or extreme conditions to force depolymerization[2]. This kinetic stability ensures that the macrocyclic core remains intact when utilized as a ligand or structural unit in aggressive chemical environments.
| Evidence Dimension | Hydrolytic Ring-Opening Reactivity |
| Target Compound Data | High free energy barrier; stable under standard hydrolytic conditions at 250 °C |
| Comparator Or Baseline | Epsilon-caprolactam (readily undergoes ring-opening polymerization) |
| Quantified Difference | Cyclic dimer requires specialized lanthanide catalysts for ring-opening, whereas the monomer polymerizes spontaneously under basic/hydrolytic conditions. |
| Conditions | Aqueous/hydrolytic reaction conditions at elevated temperatures (240-250 °C) |
Buyers designing robust macrocyclic ligands or stable copolymers must procure the cyclic dimer to ensure the 14-membered ring survives downstream synthetic steps.
Coordination Chemistry and Ligand Geometry
As a 14-membered macrocycle, 1,8-diazacyclotetradecane-2,9-dione provides a unique coordination environment distinct from standard polyamine macrocycles like cyclam (1,4,8,11-tetraazacyclotetradecane). While cyclam utilizes four highly basic amine nitrogens (pKa ~10-11) to chelate metals, the cyclic dimer functions as a neutral diamide (predicted pKa ~16.05) . This structural difference shifts the primary metal coordination sites to the amide oxygen or nitrogen atoms, resulting in distinct shifts in the C=O and N-H vibrational frequencies upon metal binding. This unique electronic profile allows for the stabilization of different metal oxidation states and the formation of MOFs with alternative pore structures and surface areas compared to traditional tetramine ligands.
| Evidence Dimension | Coordination Sites and Basicity |
| Target Compound Data | Neutral diamide coordination (predicted pKa ~16.05); amide O/N binding |
| Comparator Or Baseline | Cyclam (Tetramine coordination, pKa ~10-11) |
| Quantified Difference | ~5-6 unit difference in pKa; shift from pure amine to amide-directed chelation |
| Conditions | Metal complexation in solution and solid-state MOF formation |
Procuring this specific diamide macrocycle allows researchers to access coordination geometries and metal stabilization profiles impossible to achieve with standard basic cyclam ligands.
Reference Standard for Polyamide-6 Extractables
Because of its specific alpha/beta crystallization behavior and low solubility, 1,8-diazacyclotetradecane-2,9-dione is the primary species responsible for agglomeration during Nylon-6 melt-spinning. Procuring the high-purity compound is essential for calibrating HPLC and NMR instruments in industrial QA/QC labs to accurately quantify and mitigate this specific extractable impurity [1].
MOF Building Block
Leveraging its extreme thermal stability (Tm > 340 °C) and unique diamide coordination profile, the compound is an ideal macrocyclic ligand for synthesizing robust MOFs. It provides a less basic, more rigid coordination environment than cyclam, making it suitable for specialized gas adsorption or catalytic MOFs that must operate at elevated temperatures .
Supramolecular Assembly Precursor
The molecule's ability to form strong, highly ordered intermolecular hydrogen-bonded networks (which drive its high melting point and hydrolytic resistance) makes it a valuable structural unit in supramolecular chemistry. It is utilized to engineer self-assembling materials and advanced polymers where the integrity of the 14-membered ring must be maintained under aggressive processing conditions .
Application Fit Matrix
XLogP3
Hydrogen Bond Acceptor Count
Hydrogen Bond Donor Count
Exact Mass
Monoisotopic Mass
Heavy Atom Count
UNII
Other CAS
Wikipedia
A simple assay for 6-aminohexanoate-oligomer-hydrolase using N-(4-nitrophenyl)-6-aminohexanamide
Hisataka Taguchi, Makoto Wakamatsu, Kenji Aso, Shin Ono, Takashi Shin, Takashi AkamatsuPMID: 22867796 DOI: 10.1016/j.jbiosc.2012.07.006
Abstract
We synthesized N-(4-nitrophenyl)-6-aminohexanamide (AHpNA) and used it as a substrate in a kinetic study of 6-aminohexanoate-hydrolase (NylB), a nylon oligomer-hydrolyzing enzyme. NylBs derived from Arthrobacter sp. KI72 and Pseudomonas sp. NK87 hydrolyzed AHpNA as well as a 6-aminohexanoic acid dimer, a known substrate for NylB. The K(m) values of the NylB from Arthrobacter sp. KI72 and Pseudomonas sp. NK87 for AHpNA were 0.5 mM and 2.0 mM, respectively.X-ray crystallographic analysis of 6-aminohexanoate-dimer hydrolase: molecular basis for the birth of a nylon oligomer-degrading enzyme
Seiji Negoro, Taku Ohki, Naoki Shibata, Nobuhiro Mizuno, Yoshiaki Wakitani, Junya Tsurukame, Keiji Matsumoto, Ichitaro Kawamoto, Masahiro Takeo, Yoshiki HiguchiPMID: 16162506 DOI: 10.1074/jbc.M505946200
Abstract
6-Aminohexanoate-dimer hydrolase (EII), responsible for the degradation of nylon-6 industry by-products, and its analogous enzyme (EII') that has only approximately 0.5% of the specific activity toward the 6-aminohexanoate-linear dimer, are encoded on plasmid pOAD2 of Arthrobacter sp. (formerly Flavobacterium sp.) KI72. Here, we report the three-dimensional structure of Hyb-24 (a hybrid between the EII and EII' proteins; EII'-level activity) by x-ray crystallography at 1.8 A resolution and refined to an R-factor and R-free of 18.5 and 20.3%, respectively. The fold adopted by the 392-amino acid polypeptide generated a two-domain structure that is similar to the folds of the penicillin-recognizing family of serine-reactive hydrolases, especially to those of d-alanyl-d-alanine-carboxypeptidase from Streptomyces and carboxylesterase from Burkholderia. Enzyme assay using purified enzymes revealed that EII and Hyb-24 possess hydrolytic activity for carboxyl esters with short acyl chains but no detectable activity for d-alanyl-d-alanine. In addition, on the basis of the spatial location and role of amino acid residues constituting the active sites of the nylon oligomer hydrolase, carboxylesterase, d-alanyl-d-alanine-peptidase, and beta-lactamases, we conclude that the nylon oligomer hydrolase utilizes nucleophilic Ser(112) as a common active site both for nylon oligomer-hydrolytic and esterolytic activities. However, it requires at least two additional amino acid residues (Asp(181) and Asn(266)) specific for nylon oligomer-hydrolytic activity. Here, we propose that amino acid replacements in the catalytic cleft of a preexisting esterase with the beta-lactamase fold resulted in the evolution of the nylon oligomer hydrolase.Nylon oligomer degradation gene, nylC, on plasmid pOAD2 from a Flavobacterium strain encodes endo-type 6-aminohexanoate oligomer hydrolase: purification and characterization of the nylC gene product
S Kakudo, S Negoro, I Urabe, H OkadaPMID: 8285701 DOI: 10.1128/aem.59.11.3978-3980.1993
Abstract
A new type of nylon oligomer degradation enzyme (EIII) was purified from an Escherichia coli clone harboring the EIII gene (nylC). This enzyme hydrolyzed the linear trimer, tetramer, and pentamer of 6-aminohexanoate by an endo-type reaction, and this specificity is different from that of the EI (nylA gene product) and EII (nylB gene product). Amino acid sequencing and sodium dodecyl sulfate-polyacrylamide gel electrophoresis of the purified EIII demonstrated that the enzyme is made of two polypeptide chains arising from an internal cleavage between amino acid residues 266 and 267.Plasmid control of 6-aminohexanoic acid cyclic dimer degradation enzymes of Flavobacterium sp. KI72
S Negoro, H Shinagawa, A Nakata, S Kinoshita, T Hatozaki, H OkadaPMID: 7400094 DOI: 10.1128/jb.143.1.238-245.1980
Abstract
Flavobacterium sp. K172, which is able to grow on 6-aminohexanoic acid cyclic dimer as the sole source of carbon and nitrogen, and plasmid control of the responsible enzymes, 6-aminohexanoic acid cyclic dimer hydrolase and 6-aminohexanoic acid linear oligomer hydrolase, were studied. The wild strain of K172 harbors three kinds of plasmid, pOAD1 (26.2 megadaltons), pOAD2 (28.8 megadaltons), and pOAD3 (37.2 megadaltons). The wild strain K172 was readily cured of its ability to grow on the cyclic dimer by mitomycin C, and the cyclic dimer hydrolase could not be detected either as catalytic activity or by antibody precipitation. No reversion of the cured strains was detected. pOAD2 was not detected in every cured strain tested but was restored in a transformant. The transformant recovered both of the enzyme activities, and the cyclic dimer hydrolase of the transformant was immunologically identical with that of the wild strain. All of the strains tested, including the wild, cured, and transformant ones, possessed identical pOAD3 irrespective of the metabolizing activity. Some of the cured strains possessed pOAD1 identical with the wild strain, but the others harbored plasmids with partially altered structures which were likely to be derived from pOAD1 by genetic rearrangements such as deletion, insertion, or substitution. These results suggested that the genes of the enzymes were borne on pOAD2.Plasmid-determined enzymatic degradation of nylon oligomers
S Negoro, T Taniguchi, M Kanaoka, H Kimura, H OkadaPMID: 6305910 DOI: 10.1128/jb.155.1.22-31.1983
Abstract
The nylon oligomer (6-aminohexanoic acid cyclic dimer) degradation genes on plasmid pOAD2 of Flavobacterium sp. KI72 were cloned into Escherichia coli vector pBR322. The locus of one of the genes, the structural gene of 6-aminohexanoic acid linear oligomer hydrolase, was determined by constructing various deletion plasmids and inserting the lacUV5 promoter fragment of E. coli into the deletion plasmid. Two kinds of repeated sequences (RS-I and RS-II) were detected on pOAD2 by DNA-DNA hybridization experiments. These repeated sequences appeared five times (RS-I) or twice (RS-II) on pOAD2. One of the RS-II regions and the structural gene of the hydrolase overlapped.DNA-DNA hybridization analysis of nylon oligomer-degradative plasmid pOAD2: identification of the DNA region analogous to the nylon oligomer degradation gene
S Negoro, S Nakamura, H OkadaPMID: 6327604 DOI: 10.1128/jb.158.2.419-424.1984
Abstract
Fine structure of the gene of 6-aminohexanoic acid cyclic dimer hydrolase, one of the enzymes responsible for the degradation of the nylon oligomer (6-aminohexanoic acid cyclic dimer), on the plasmid pOAD2 harbored in Flavobacterium sp. KI72 was determined by constructing miniplasmids from plasmid pNDH5 (a hybrid plasmid consisting of pBR322 and a 9.1-kilobase-pair HindIII fragment of pOAD2 ). The 6-aminohexanoic acid cyclic dimer hydrolase produced by cells of Escherichia coli C600 harboring pNDH5 or its miniplasmid was examined immunologically and electrophoretically and was found to be identical to that of Flavobacterium sp. KI72 . A fragment of pOAD2 (17.2- to 19.1-kilobase-pair region on pOAD2 ) was detected as hybridized fragment by Southern blotting experiments, indicating the presence of the DNA region analogous to the 6-aminohexanoic acid cyclic dimer hydrolase gene on the plasmid.Explore Compound Types