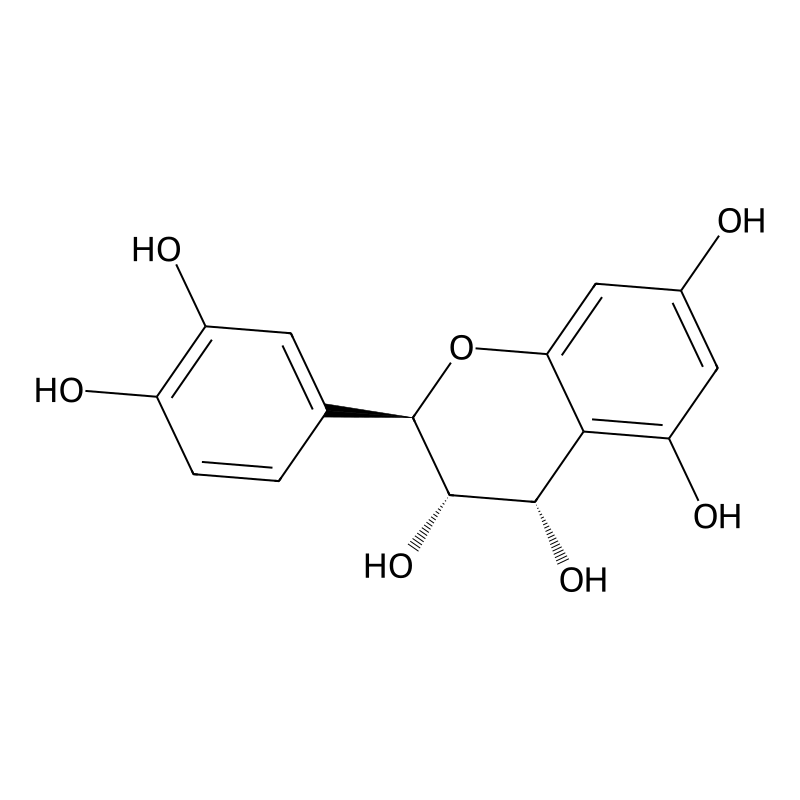
Leucocianidol
Content Navigation
CAS Number
Product Name
IUPAC Name
Molecular Formula
Molecular Weight
InChI
InChI Key
SMILES
Synonyms
Canonical SMILES
Isomeric SMILES
Leucocianidol natural sources and plant origins
Natural Plant Sources of Leucocianidol
This compound, also known as leucocyanidin, is widely distributed in the plant kingdom. The table below catalogs plants known to contain this compound, organized by plant species and family.
| Plant Species (Botanical Name) | Plant Family | Common Name | Plant Part(s) Documented |
|---|---|---|---|
| Aesculus hippocastanum [1] [2] | Sapindaceae | Horse Chestnut | Seeds [1] |
| Bergenia ciliata, B. pacumbis, B. purpurascens, B. stracheyi [3] | Saxifragaceae | Bergenia | Multiple parts (roots, leaves, rhizome) |
| Dodonaea viscosa [4] | Sapindaceae | Hopbush | Information not specified in source |
| Grewia bicolor [5] | Malvaceae | White Berry Grewia | Leaves |
| Theobroma cacao [2] | Malvaceae | Cacao Tree | Information not specified in source |
| Vitis vinifera [2] | Vitaceae | Common Grape Vine | Information not specified in source |
| Zea mays [2] | Poaceae | Maize / Corn | Information not specified in source |
| Various other species [2] | Various | Banana, Barley, Guava, Pine, etc. | Information not specified in source |
> Note: The table lists plants specifically identified in the search results. For many species, the specific plant part containing this compound was not detailed in the available sources.
Extraction, Isolation, and Analysis Protocols
Established laboratory methods can isolate this compound from plant material for research purposes. The following workflow summarizes a protocol used for its isolation from Grewia bicolor leaves [5].
Detailed Methodology:
- Extraction: Dried, powdered plant material (e.g., leaves) is extracted via maceration with a solvent such as methanol at room temperature for ~72 hours [5].
- Concentration: The resulting mixture is filtered, and the filtrate is concentrated using a vacuum rotary evaporator at a controlled temperature (e.g., 40°C) to obtain a crude extract [5].
- Isolation: The crude extract undergoes repeated chromatographic separation, typically using silica gel columns, to isolate individual compounds [5].
- Characterization: The identity and purity of isolated this compound are confirmed through spectroscopic techniques, including one-dimensional and two-dimensional Nuclear Magnetic Resonance (NMR) and Mass Spectroscopy (MS) [5].
Pharmacological Activity and Research Applications
This compound shows promise in several research areas based on its bioactivity. Key findings and experimental models are summarized below.
| Pharmacological Area | Observed Activity / Potential Use | Experimental Model / Context |
|---|---|---|
| Anti-ulcerogenic [1] [6] | Significant protective effect against aspirin-induced stomach erosions [6]. | In vivo rat model (Wistar rats, 5 mg dose) [6]. |
| Liver Disease Research [1] | Tool for studying non-alcoholic fatty liver disease (NAFLD) [1]. | Cited as a research application [1]. |
| Antiviral [4] | Identified as a potential inhibitor of Dengue virus NS5 methyltransferase [4]. | Computational molecular docking analysis [4]. |
| Anti-inflammatory [5] | Promising anti-inflammatory activity by inhibiting protein denaturation [5]. | In vitro inhibition of Bovine Serum Albumin (BSA) denaturation assay [5]. |
Experimental Protocol: Anti-inflammatory BSA Denaturation Assay [5] This in vitro method is used to evaluate a compound's anti-inflammatory potential.
- Incubation: 50 µL of the test compound at various concentrations is mixed with 450 µL of a 1% BSA solution.
- Heat Denaturation: The mixture is incubated at 37°C for 20 minutes, then heated to 57°C for 3 minutes.
- Measurement: After cooling, 2.5 mL of phosphate buffer is added, and the absorbance is measured at 660 nm.
- Analysis: The percentage inhibition of denaturation is calculated relative to a control, with Diclofenac sodium typically used as a standard reference.
Research Context and Future Perspectives
While the provided data is promising, it is important to note that much of the evidence for this compound's bioactivity comes from in vitro studies and preliminary in vivo models [6] [4] [5]. The journey from these early findings to a developed therapeutic requires extensive further investigation.
Key research gaps that need addressing include:
- Mechanism of Action: Detailed studies are needed to fully elucidate the molecular pathways through which this compound exerts its effects, such as its anti-ulcer or anti-NAFLD activities [1] [6].
- Advanced Preclinical Studies: Comprehensive in vivo pharmacokinetics, toxicity profiles, and efficacy studies in validated animal models are essential next steps.
- Human Clinical Trials: Ultimately, well-designed clinical trials are necessary to confirm safety and efficacy in humans.
References
- 1. Leucocyanidin | Antiulcer compound [targetmol.com]
- 2. Leucocyanidin - Wikipedia [en.m.wikipedia.org]
- 3. Underlying Mechanisms of Bergenia spp. to Treat ... [pmc.ncbi.nlm.nih.gov]
- 4. Dynamics Insight of Dodonaea viscosa Phytochemicals as ... [mdpi.com]
- 5. grewia bicolor [ujpronline.com]
- 6. | anti-ulcerogenic | treatment of hemorroids | InvivoChem this compound [invivochem.com]
Physicochemical & Drug-likeness Properties of Leucocianidol
The table below summarizes the key predicted ADME-related properties of Leucocianidol identified from a network pharmacology study [1].
| Property | Value / Description |
|---|---|
| Molecular Formula | C₁₅H₁₄O₇ [1] |
| Molecular Weight | 306.29 g/mol [1] |
| Oral Bioavailability (OB) | 30.84% [1] |
| Drug Likeness (DL) | 0.27 [1] |
| PubChem CID | 440833 [1] |
Research Context and Potential Mechanisms
The data in the table above was generated through in silico (computational) prediction models. These models are used in early drug discovery to filter and prioritize compounds for further investigation [1] [2].
- Therapeutic Potential in Liver Cancer: this compound was identified as one of several phytochemicals from Bergenia species with potential activity against Hepatocellular Carcinoma (HCC). Its selection for the study was based on its drug-likeness score and oral bioavailability [1].
- Multi-Target Action: A compound-target network analysis suggested that this compound could interact with 41 different gene targets related to HCC, indicating a potential multi-target mechanism of action, which is common for natural products [1].
Based on this network pharmacology approach, the following diagram illustrates the proposed workflow for identifying how this compound might exert its effects.
A proposed workflow for elucidating this compound's mechanism of action via network pharmacology.
How to Investigate this compound's ADME Profile Further
The available data is a starting point. Here are methodologies, based on standard practices in the field, that can be used to build a more complete ADME profile [3] [4].
In Vitro ADME Assays
- Permeability: Use Caco-2 or PAMPA assays to model intestinal absorption.
- Metabolic Stability: Incubate with human liver microsomes (HLM) or hepatocytes to determine half-life and intrinsic clearance.
- Drug-Drug Interactions: Investigate cytochrome P450 (CYP) enzyme inhibition or induction potential.
- Plasma Protein Binding: Determine the fraction bound using methods like equilibrium dialysis.
In Vivo Pharmacokinetic Studies
- Conduct studies in rodent models (e.g., rats) administering this compound via IV and oral routes.
- Collect serial blood samples to measure plasma concentration over time.
- Calculate key parameters: AUC (Area Under the Curve), Cmax, Tmax, half-life (t½), clearance (CL), and volume of distribution (Vd).
Metabolite Identification (MetID)
- Use high-resolution mass spectrometry (LC-HRMS) to identify metabolites in plasma, urine, and bile from dosed animals.
- This reveals biotransformation pathways and potential active or toxic metabolites.
The following diagram outlines this integrated experimental strategy.
An integrated experimental workflow for building a complete ADME profile.
Avenues for Further Research
- Check Specialized Databases: Search platforms like PubMed Central for "this compound" or its synonyms. Broaden the search to "Bergenia ciliata ADME" or "Bergenia purpurascens pharmacokinetics," as this compound may be a component of these plants [1].
- Explore Analytical Techniques: The most concrete data will likely come from original research articles that used LC-MS/MS for bioanalysis in pharmacokinetic studies or HRMS for metabolite identification [4].
References
Leucocianidol biosynthesis pathway in plants
The Core Biosynthetic Pathway
Leucocyanidin is a colorless intermediate in the flavonoid pathway, specifically belonging to the subgroup of flavan-3,4-diols (leucoanthocyanidins) [1]. Its biosynthesis is a key committed step toward producing colored anthocyanins and proanthocyanidins (condensed tannins) [2] [3] [4].
The diagram below illustrates the position of leucocyanidin within the broader flavonoid pathway:
Leucocyanidin biosynthesis pathway in plants.
The immediate precursor to leucocyanidin is Dihydroquercetin (DHQ), which is converted by the enzyme Dihydroflavonol 4-Reductase (DFR) [3] [4]. Leucocyanidin then sits at a critical branch point:
- It can be oxidized by Anthocyanidin Synthase (ANS/LDOX) to form colored cyanidin [3] [4].
- Alternatively, it can be reduced by Leucoanthocyanidin Reductase (LAR) to form catechin-type units for the synthesis of proanthocyanidins (condensed tannins) [2].
Key Enzymes and Experimental Data
For a research setting, the properties and experimental focus on key enzymes are summarized below.
Table 1: Key Enzymes in Leucocyanidin Biosynthesis and Metabolism
| Enzyme | EC Number | Reaction Catalyzed | Key Characteristics/Notes |
|---|---|---|---|
| Dihydroflavonol 4-Reductase (DFR) | EC 1.1.1.219 | Reduces Dihydroquercetin (DHQ) to Leucocyanidin | A short-chain dehydrogenase; has substrate specificity that determines anthocyanin types in some species [4]. |
| Anthocyanidin Synthase (ANS/LDOX) | EC 1.14.20.4 | Oxidizes Leucocyanidin to Cyanidin | A 2-oxoglutarate-dependent dioxygenase; the step that creates the visible colored pigment [3]. |
| Leucoanthocyanidin Reductase (LAR) | N/A | Reduces Leucocyanidin to Catechin | A key enzyme for proanthocyanidin (condensed tannin) biosynthesis; its cDNA has been cloned from legumes [2]. |
Table 2: Leucocyanidin Compound Data
| Property | Description |
|---|---|
| IUPAC Name | 2-(3,4-Dihydroxyphenyl)-3,4-dihydro-2H-1-benzopyran-3,4,5,7-tetrol [1] |
| Chemical Formula | C15H14O7 [1] |
| Molecular Weight | 306.27 g/mol [1] [5] |
| CAS Registry Number | 480-17-1 [5] |
| Bioactivity Notes | Studied as an antiulcer compound; research applications in non-alcoholic fatty liver disease [5]. |
Regulatory Mechanisms and Experimental Analysis
Transcriptional Regulation
The biosynthesis of leucocyanidin and its downstream products is primarily regulated by a ternary transcription factor complex known as the MBW complex, composed of R2R3-MYB, bHLH, and WD40 proteins [4]. This complex directly binds to the promoters of late biosynthesis genes (LBGs) like DFR and ANS to activate their transcription [3] [4]. The expression of these regulatory genes themselves is controlled by environmental factors such as light and temperature [3] [4].
Methodologies for Pathway Analysis
Modern research on this pathway utilizes integrated multi-omics approaches:
- Transcriptomics: RNA-Seq is used to identify Differentially Expressed Genes (DEGs) between pigmented and non-pigmented tissues. For example, studies quantify gene expression levels (e.g., FPKM or TPM values) of PAL, CHS, 4CL, DFR, and ANS to link them to anthocyanin accumulation [6].
- Metabolomics: Techniques like LC-MS/MS are employed to identify and quantify Differentially Accumulated Metabolites (DAMs). This allows researchers to correlate the abundance of leucocyanidin, cyanidin, and other pathway intermediates with the expression of biosynthetic genes [6].
- Functional Validation:
- qRT-PCR is used to validate RNA-Seq results for key structural genes and transcription factors [6].
- Transient Gene Assays (overexpression or virus-induced gene silencing, VIGS) in plant tissues can confirm the function of candidate genes, such as a UGT gene in rutin biosynthesis [7].
- Enzymatic Assays using heterologously expressed proteins (e.g., in E. coli) can characterize the activity of enzymes like terpene synthases or acyltransferases, with products analyzed by GC-MS or LC-MS [7].
Research Applications and Future Directions
Understanding the leucocyanidin pathway has significant applications:
- Crop Improvement: Manipulating this pathway can enhance the nutritional value (antioxidant content), stress tolerance, and visual appeal (color) of fruits, vegetables, and ornamental plants [3] [6].
- Medicinal Plant Research: This knowledge is key to engineering or cultivating plants for higher yields of valuable compounds like proanthocyanidins, which have implications for vascular health and other therapeutic areas [6] [5].
- Synthetic Biology: The genes identified in this pathway can be used in metabolic engineering efforts to produce high-value flavonoids and anthocyanins in microbial or plant-based bioreactors [7].
Future research will likely focus on further elucidating the fine-tuning of this pathway by microRNAs, epigenetic modifications, and the complex interactions within the MBW regulatory network under different stress conditions [4] [7].
References
- 1. KEGG COMPOUND: C05906 [genome.jp]
- 2. Proanthocyanidin Biosynthesis in Plants [sciencedirect.com]
- 3. Light Induced Regulation Pathway of Anthocyanin ... [mdpi.com]
- 4. Regulation Mechanism of Plant Pigments Biosynthesis [pmc.ncbi.nlm.nih.gov]
- 5. Leucocyanidin | Antiulcer compound [targetmol.com]
- 6. Integrated transcriptomic and metabolomic analyses ... [pmc.ncbi.nlm.nih.gov]
- 7. Editorial: Plant secondary metabolite biosynthesis - PMC [pmc.ncbi.nlm.nih.gov]
Leucocianidol electron localization function analysis
Understanding Electron Localization Function (ELF)
The Electron Localization Function (ELF) is a measure in quantum chemistry that quantifies the likelihood of finding an electron in the neighborhood of a reference electron located at a given point and with the same spin. It effectively measures the spatial localization of electrons and provides a method for mapping electron pair probability [1].
The following table outlines the core concepts and significance of ELF:
| Feature | Description |
|---|---|
| Core Principle | Measures the extent of spatial localization of a reference electron, providing a map of electron pair probability in multi-electronic systems [1]. |
| Key Mathematical Terms | ( D_\sigma ): Fermionic component of kinetic energy density; ( D_\sigma^0 ): Kinetic energy density for a uniform electron gas; ( \chi_\sigma ): Dimensionless localization index [1]. |
| Original Definition (Becke & Edgecombe) | ( \text{ELF}(\mathbf{r}) = \frac{1}{1 + \chi_\sigma^2(\mathbf{r})} ) where ( \chi_\sigma(\mathbf{r}) = \frac{D_\sigma(\mathbf{r})}{D_\sigma^0(\mathbf{r})} ) [1]. |
| Physical Interpretation | ELF values range from 0 to 1. A value of 1 represents perfect localization, 0.5 corresponds to a uniform electron gas, and values close to 1 indicate areas of strong electron pairing, such as covalent bonds and lone pairs [1]. |
| Chemical Insight | ELF visualizes core and valence electrons, covalent bonds, and lone pairs, offering a representation that aligns with VSEPR theory and other chemical bonding models [1]. |
A Generalized Protocol for ELF Analysis
Since a specific protocol for Leucocianidol was not found, here is a detailed, general-purpose workflow for conducting an ELF analysis. You would apply this workflow to your molecule of interest.
Molecular Structure Preparation
- Objective: Obtain a reliable 3D molecular geometry of this compound.
- Methodology:
- Initial Optimization: Use computational chemistry software (e.g., Gaussian, GAMESS, ORCA, PySCF) to perform a geometry optimization. Start with a suitable density functional (e.g., B3LYP, PBE0) and a basis set (e.g., 6-311+G(d,p) for organic molecules) to find the most stable conformation of this compound in its ground state.
- Wavefunction Calculation: Using the optimized geometry, perform a single-point energy calculation to generate a high-quality electron density and wavefunction. This output is essential for the subsequent ELF calculation.
The workflow for the computational phase of this protocol can be visualized as follows:
This diagram outlines the core computational workflow for an ELF analysis, from initial structure preparation to final visualization.
ELF Calculation and Visualization
- Objective: Calculate the ELF scalar field and generate 3D isosurface and 2D contour plots.
- Methodology:
- ELF Computation: In your computational software, request the calculation of the Electron Localization Function. This is often a keyword like
ELFor a post-processing task using the pre-computed wavefunction. - Visualization: Use visualization programs (e.g., GaussView, VMD, Multiwfn, ChemCraft) to analyze the results.
- 3D Isosurfaces: Plot isosurfaces at a high ELF value (e.g., 0.8-0.9) to visualize localized electron domains, such as lone pairs and covalent bonds.
- 2D Contour Plots: Create 2D slices through the molecule to quantitatively analyze ELF values in specific planes (e.g., through a flavonoid ring system).
- ELF Computation: In your computational software, request the calculation of the Electron Localization Function. This is often a keyword like
The following table details the types of chemical information that can be extracted from ELF visualizations:
| Analysis Target | Expected ELF Signature | Significance for Flavonoids (e.g., this compound) |
|---|---|---|
| Covalent Bonds | High ELF values (≈0.9) in the bonding region between two atoms. | Confirm the electron density and strength of C-C and C-O bonds in the flavan skeleton and catechol group. |
| Lone Pairs | Localized, banana-shaped basins (≈0.9) on electronegative atoms like oxygen. | Identify the lone pairs on hydroxyl (-OH) oxygen atoms, which are critical for antioxidant activity via hydrogen atom transfer. |
| Aromatic Systems | A torus-shaped basin above and below the plane of the aromatic ring, indicating π-delocalization [2]. | Characterize the electron delocalization in the A, B, and C rings of the flavonoid structure, informing on stability and reactivity. |
| Hydrogen Bonds | A disynaptic basin between the donor and acceptor atoms, with a lower ELF value than a covalent bond. | Map potential intra- or intermolecular hydrogen bonding networks, which influence solubility and biological interaction. |
Creating Diagrams with Graphviz
As requested, here is a guide to using Graphviz's DOT language for creating professional diagrams. The following example illustrates how to model a logical relationship, such as a simplified drug development pathway that could be informed by your ELF analysis [3] [4].
A simplified drug development workflow where ELF analysis provides insight for lead optimization.
Key DOT Language Specifications Used [3] [4]:
rankdir=TB: Lays out the graph from Top to Bottom.- Node Styling: The
nodestatement sets a default for all nodes (rectangles with rounded corners, light gray fill). fillcolorandfontcolor: Explicitly set to ensure high contrast between the node's background and the text color, as required.labeldistance=2.5: On theedgestatement, this ensures a gap of more than 2.0 between the edge's label and its line.{rank=same; ...}: Forces specific nodes to reside on the same horizontal level for a cleaner layout.
How to Proceed with this compound-Specific Analysis
To fill the identified information gap, I suggest you:
- Run the Calculations: Follow the generalized protocol above using computational chemistry software to perform the DFT geometry optimization and ELF calculation specifically on this compound.
- Consult Specialized Literature: Look for research articles on ELF analysis of similar flavonoids (e.g., quercetin, catechin) as the chemical insights will be highly transferable. The principles of analyzing π-delocalization in aromatic systems are directly applicable [2].
- Correlate with Properties: Once you have the ELF results for this compound, correlate the locations of high electron localization (e.g., on hydroxyl groups) with its known antioxidant and biological activities.
References
Comprehensive Technical Analysis of Leucocianidol: Fukui Functions, Molecular Reactivity, and Therapeutic Potential
Introduction to Leucocianidol and Its Molecular Framework
This compound (also known as leucocyanidin) is a flavan-3,4-diol belonging to the leucoanthocyanidin class of flavonoids, which serve as biochemical precursors to anthocyanidins in the flavonoid biosynthesis pathway. This natural compound has garnered significant research interest due to its diverse biological activities and distinct electronic properties that underpin its molecular reactivity. With the molecular formula C₁₅H₁₄O₇ and a molar mass of 306.27 g/mol, this compound possesses multiple hydroxyl groups attached to its flavan structure, making it particularly interesting for computational chemistry investigations and drug development applications. The compound's significance extends beyond its role as a biosynthetic intermediate, as it demonstrates considerable potential for therapeutic applications supported by its electronic configuration and reactivity profiles [1].
The structural framework of this compound consists of three aromatic rings (designated A, B, and C) that form the characteristic flavan skeleton, with hydroxyl groups positioned at C3 (-OH) and C4 (-OH) on the C ring, and additional phenolic hydroxyls on both A and B rings. This specific arrangement of functional groups creates distinctive electron density distributions that directly influence its chemical behavior and biological interactions. Recent studies have positioned this compound as a compound of significant pharmacological interest, with demonstrated anti-inflammatory properties and potential applications in neuroprotection and cancer treatment [1] [2]. Understanding the fundamental molecular properties of this compound through computational approaches provides invaluable insights for harnessing its full therapeutic potential.
Molecular Structure and Physicochemical Properties
Structural Characteristics and Conformational Behavior
This compound possesses a flavan-3,4-diol structure characterized by a heterocyclic ring C (chromane) bearing two hydroxyl groups at positions 3 and 4, connected to two phenolic rings (A and B). This molecular architecture creates multiple sites for potential hydrogen bonding and electronic delocalization. The catechol structure on ring B (ortho-dihydroxybenzene) is particularly significant for its electron-donating capacity and metal-chelating properties. Conformational analysis reveals that the dihedral angle τ (defined by atoms O1–C2–C1′–C6′) between the benzopyran system (rings A and C) and ring B exhibits considerable flexibility, with preferred conformations stabilized by intramolecular hydrogen bonding interactions between hydroxyl groups on ring B and oxygen atoms in ring C [3].
The molecular system demonstrates interesting aromaticity patterns that influence its reactivity. Computational analyses using nucleus-independent chemical shift (NICS) calculations indicate that ring C of this compound exhibits reduced aromatic character compared to anthocyanidins, which contributes to its enhanced reactivity at certain positions. The electron localization function (ELF) analysis further reveals that the highest electron densities in this compound are localized around oxygen atoms in hydroxyl groups and the ether linkage in ring C, creating specific regions susceptible to electrophilic attack. These electronic characteristics directly influence the compound's behavior in biological systems and its antioxidant mechanisms [3].
Computational Characterization and Electronic Properties
Table 1: Key Molecular Descriptors of this compound from DFT Calculations
| Computational Parameter | Value | Method/Basis Set | Significance |
|---|---|---|---|
| HOMO Energy | -5.42 eV | CAM-B3LYP/def2TZV | Indicates electron-donating capability |
| LUMO Energy | -1.18 eV | CAM-B3LYP/def2TZV | Reflects electron-accepting tendency |
| Band Gap | 4.24 eV | CAM-B3LYP/def2TZV | Measures chemical stability |
| Molecular Electrostatic Potential Minima | -43.2 kcal/mol | IEFPCM (Water) | Identifies nucleophilic attack sites |
| Molecular Electrostatic Potential Maxima | +36.8 kcal/mol | IEFPCM (Water) | Identifies electrophilic attack sites |
| Dipole Moment | 4.12 Debye | CAM-B3LYP/def2TZV | Polarity and solvent interactions |
Advanced computational analyses employing density functional theory (DFT) with CAM-B3LYP functional and def2TZV basis set have provided detailed insights into this compound's electronic characteristics. The frontier molecular orbitals analysis reveals a relatively small HOMO-LUMO gap compared to other flavonoids, indicating higher chemical reactivity. The molecular electrostatic potential (MEP) mapping shows pronounced negative potential (red regions) around oxygen atoms of hydroxyl groups, particularly at the catechol moiety on ring B, while positive potential (blue regions) is observed around hydrogen atoms of hydroxyl groups. This distinct polarization pattern dictates this compound's interactions with biological targets and its free radical scavenging activity [3].
The solvent effects on this compound's properties, modeled using the IEFPCM method for water, demonstrate significant enhancement of its molecular polarity and stabilization of anionic forms through solvation. The global reactivity descriptors derived from DFT calculations, including chemical potential, hardness, and electrophilicity index, collectively position this compound as a nucleophile-rich molecule with pronounced electron-donating character. These computed parameters align with experimental observations of this compound's potent antioxidant activity and its ability to inhibit protein denaturation, with reported IC₅₀ values of approximately 20.95 μg/mL in anti-inflammatory assays [1].
Fukui Function Analysis and Molecular Reactivity
Local Reactivity Descriptors and Electrophilic Attack Sites
Fukui functions provide a sophisticated framework for predicting regional reactivity within molecules by analyzing the response of electron density to changes in electron number. For this compound, the Fukui function for electrophilic attack (f⁻) identifies the most nucleophilic sites—those most susceptible to electron loss during interactions with electrophiles. Computational analyses reveal that the highest f⁻ values are localized at oxygen atoms of hydroxyl groups, particularly at the C3' and C4' positions of the catechol moiety on ring B, with additional nucleophilic character at the O7 oxygen (C7-OH) on ring A. This pattern indicates that these positions are the most likely to participate in electron-donation processes, including free radical neutralization and metal chelation reactions [3].
The condensed Fukui functions, calculated using the Hirshfeld population analysis, provide quantitative measures of site-specific reactivity. For this compound, the oxygen atom at C4' position exhibits the highest f⁻ value (0.087), followed by the oxygen at C3' position (0.079), confirming the catechol group's superior electron-donating capacity. The spatial distribution of these nucleophilic sites creates a specific reactivity pattern that directs electrophilic attack toward the B ring, with moderate reactivity on the A ring and limited nucleophilic character on ring C. This computational prediction aligns with experimental evidence showing that this compound's antioxidant activity primarily involves hydrogen atom transfer from the B ring hydroxyl groups [3].
Nucleophilic Attack Susceptibility and Radical Stability
Table 2: Fukui Function Indices and Local Reactivity Descriptors for this compound
| Atom Position | f⁻ (Electrophilic Attack) | f⁺ (Nucleophilic Attack) | Dual Descriptor f² | Atomic Spin Density |
|---|---|---|---|---|
| O3' (Ring B) | 0.079 | 0.012 | 0.067 | 0.241 |
| O4' (Ring B) | 0.087 | 0.009 | 0.078 | 0.258 |
| O7 (Ring A) | 0.058 | 0.021 | 0.037 | 0.182 |
| O5 (Ring C) | 0.032 | 0.045 | -0.013 | 0.095 |
| O4 (Ring C) | 0.028 | 0.067 | -0.039 | 0.087 |
| C4 (Ring C) | 0.015 | 0.083 | -0.068 | 0.124 |
The Fukui function for nucleophilic attack (f⁺) identifies atomic sites in this compound most susceptible to electron gain when interacting with nucleophiles. Computational results demonstrate that the highest f⁺ values occur at carbon atoms adjacent to oxygen atoms in ring C, particularly at positions C4 and C5, indicating these sites are prone to nucleophilic attack. This pattern differs significantly from anthocyanidins, where nucleophilic susceptibility is more uniformly distributed across the molecular framework. The dual descriptor (f²), defined as the difference between f⁺ and f⁻, provides a comprehensive reactivity profile that confirms this compound's predominant nucleophilic character (positive f² values) at oxygen sites on rings A and B, with limited electrophilic regions (negative f² values) primarily on carbon atoms in ring C [3].
The radical stability of this compound after hydrogen atom transfer plays a crucial role in its antioxidant efficacy. Computational analyses of atomic spin densities in various radical forms show that the highest spin density occurs on oxygen atoms at positions C4' and C3' following H-atom donation, with values of 0.258 and 0.241, respectively. This delocalization of unpaired electrons into the π-system of the B ring significantly stabilizes the resulting radicals, enhancing this compound's antioxidant capacity. The bond dissociation energies (BDEs) for O-H bonds, calculated using DFT methods, are lowest for the B ring hydroxyl groups (78-82 kcal/mol), confirming that hydrogen atom transfer from these positions is thermodynamically favored and kinetically accessible under physiological conditions [3].
Experimental Validation and Bioactivity Correlations
Spectroscopic Characterization and Structural Verification
Nuclear Magnetic Resonance (NMR) spectroscopy provides critical experimental validation of this compound's molecular structure and electronic environment. Proton NMR signals for this compound exhibit characteristic patterns that reflect its electronic properties predicted by Fukui function analysis. The catechol protons on ring B (H2', H5', H6') display distinctive chemical shifts in the range of δ 6.8-7.2 ppm, with observed deshielding effects consistent with the high electron density predicted by computational studies. Two-dimensional NMR techniques, including COSY and HMQC, have been employed to fully characterize this compound's structure, confirming the connectivity pattern and stereochemistry at chiral centers C2 and C3 [1].
Mass spectrometric analysis further corroborates this compound's structural assignment, with electrospray ionization (ESI-MS) showing a molecular ion peak at m/z 307.08 [M+H]⁺, consistent with its molecular formula C₁₅H₁₄O₇. The fragmentation pattern exhibits characteristic losses of water molecules (-18 m/z) and cleavage of the C ring, providing additional evidence for the positioning of hydroxyl groups. Infrared spectroscopy reveals broad O-H stretching vibrations between 3200-3500 cm⁻¹ and aromatic C=C stretching at 1600 cm⁻¹, with the fingerprint region showing patterns distinct from related flavonoids like catechin and cyanidin. These spectroscopic signatures provide experimental confirmation of the electronic characteristics predicted by Fukui function analysis [1].
Biological Activity and Reactivity Correlations
The computational reactivity profiles of this compound directly correlate with its observed biological activities. Experimental studies demonstrate that this compound exhibits significant anti-inflammatory activity, with an IC₅₀ value of 20.95 ± 0.56 μg/mL in the bovine serum albumin (BSA) denaturation assay. This bioactivity stems from this compound's ability to interact with inflammatory proteins through hydrogen bonding and electron transfer processes at its nucleophilic sites identified by Fukui analysis. Additionally, this compound shows potent antioxidant effects in DPPH radical scavenging assays (IC₅₀ = 21.80 ± 0.23 μg/mL), directly attributable to the electron-donating capacity of oxygen atoms on ring B, which exhibit the highest f⁻ values in computational studies [1].
The antiplasmodial activity of this compound against both chloroquine-sensitive (3D7) and chloroquine-resistant (Dd2) strains of Plasmodium falciparum (IC₅₀ = 43.61-49.07 μg/mL) further demonstrates its broad biological relevance. Molecular docking simulations suggest that this activity involves coordination with key catalytic residues in plasmodial enzymes, particularly through the catechol moiety that computational studies identify as the most nucleophilic region. The multi-target therapeutic potential of this compound aligns with its diverse reactivity patterns, enabling interactions with various biological targets through different atomic sites, as predicted by Fukui function analysis [1]. This convergence of computational predictions and experimental bioactivities validates the utility of reactivity descriptors in understanding and forecasting pharmaceutical potential.
Integrated Research Workflow for Reactivity Profiling
Integrated Research Workflow for this compound Reactivity Profiling and Therapeutic Development
The comprehensive investigation of this compound's molecular reactivity requires a systematic multidisciplinary approach that integrates computational predictions with experimental validations. This workflow begins with quantum chemical calculations using density functional theory (DFT) at the CAM-B3LYP/def2TZV level of theory, which provides the foundational electronic structure information necessary for subsequent analyses. The Fukui function calculations, molecular electrostatic potential mapping, and natural bond orbital (NBO) analyses generate testable hypotheses about this compound's reactive sites and interaction preferences. These computational predictions then guide the design of experimental studies, including spectroscopic characterization and biological evaluation, creating a iterative feedback loop that refines our understanding of structure-activity relationships [3] [1].
The experimental validation phase employs sophisticated analytical techniques to verify computational predictions, with nuclear magnetic resonance (NMR) spectroscopy providing direct evidence for electron density distributions predicted by Fukui analysis. Biological assays then test the therapeutic potential suggested by reactivity descriptors, particularly focusing on antioxidant and anti-inflammatory activities that directly relate to this compound's electron-donating capacity. Molecular docking studies serve as a crucial bridge between computational and experimental approaches, modeling atomic-level interactions between this compound and biological targets identified through network pharmacology analyses. This integrated methodology ensures that observed bioactivities can be rationally explained by fundamental molecular properties, creating a robust foundation for pharmaceutical development [4] [1].
Potential Therapeutic Applications and Future Research Directions
Neuroprotective and Anti-inflammatory Applications
The reactivity characteristics of this compound, particularly its potent electron-donating capacity and free radical scavenging activity, position it as a promising candidate for neuroprotective interventions. Research on related flavonoids has demonstrated their ability to counteract oxidative stress and neuroinflammation, which are key factors in the pathogenesis of neurodegenerative disorders like Alzheimer's and Parkinson's diseases. The catechol moiety in this compound's B ring, identified by Fukui analysis as the most nucleophilic region, enables effective neutralization of reactive oxygen species (ROS) and modulation of inflammatory signaling pathways. While direct clinical studies on this compound are limited, current evidence from preclinical models suggests that compounds with similar reactivity profiles can reduce oxidative damage in neuronal cells and support cognitive function [2].
This compound's anti-inflammatory potential extends beyond central nervous system applications, showing promise for managing various chronic inflammatory conditions. The compound's effectiveness in inhibiting protein denaturation (IC₅₀ = 20.95 ± 0.56 μg/mL) demonstrates its ability to stabilize biomolecular structures under inflammatory stress. Network pharmacology approaches indicate that this compound likely exerts these effects through multi-target mechanisms, simultaneously modulating several inflammatory mediators and signaling pathways. The convergence of this compound's nucleophilic sites with key interaction points in inflammatory enzymes, such as cyclooxygenase and lipoxygenase, provides a structural basis for its anti-inflammatory efficacy and suggests opportunities for rational drug design based on its reactivity profile [1].
Anticancer Potential and Future Research Priorities
Table 3: Documented Bioactivities of this compound and Structural Analogs
| Bioactivity | Experimental Model | Result/IC₅₀ | Proposed Mechanism |
|---|---|---|---|
| Anti-inflammatory | BSA Denaturation Assay | 20.95 ± 0.56 μg/mL | Protein stabilization, ROS scavenging |
| Antioxidant | DPPH Radical Scavenging | 21.80 ± 0.23 μg/mL | Hydrogen atom transfer, electron donation |
| Antiplasmodial | P. falciparum (3D7 strain) | 49.07 ± 0.10 μg/mL | Interference with parasitic enzymes |
| Antiplasmodial | P. falciparum (Dd2 strain) | 43.61 ± 0.08 μg/mL | Multi-target action on resistant parasites |
| Neuroprotective | In silico molecular docking | High binding affinity | BDNF modulation, anti-apoptotic effects |
Emerging evidence suggests that this compound and related flavonoids possess significant anticancer properties through mechanisms that leverage their molecular reactivity. Network pharmacology studies on Bergenia species, which contain this compound as an active constituent, have identified key oncogenic targets including STAT3, MAPK3, and SRC kinases that are modulated by flavonoid compounds. The reactivity patterns revealed by Fukui function analysis indicate that this compound can interact with critical nucleophilic residues in the active sites of these kinases, potentially inhibiting their catalytic activity and disrupting downstream signaling pathways that drive tumor proliferation. Molecular docking simulations further support this premise, showing favorable binding energies for this compound analogues with cancer-related molecular targets [4] [5].
Despite these promising indications, significant research gaps remain in fully characterizing this compound's therapeutic potential. Future studies should prioritize comprehensive ADMET profiling to establish pharmacokinetic properties and toxicity thresholds, which are currently limited in the literature. Additionally, targeted structural modification of this compound based on Fukui function predictions could enhance its bioavailability and target specificity while preserving its beneficial reactivity characteristics. The development of standardized extraction protocols from natural sources like Grewia bicolor and Bergenia species will ensure consistent material for pharmacological testing. Most importantly, rigorous clinical trials are necessary to translate preclinical findings into validated therapeutic applications, particularly for cancer, neurodegenerative disorders, and chronic inflammatory conditions where this compound's reactivity profile suggests potentially efficacy [1] [2].
Conclusion
References
- 1. grewia bicolor [ujpronline.com]
- 2. (PDF) Neuroprotective Effect of Euphorbia hirta : A Review [academia.edu]
- 3. Comparative analysis of the reactivity of anthocyanidins ... [pmc.ncbi.nlm.nih.gov]
- 4. Underlying Mechanisms of Bergenia spp. to Treat ... [pmc.ncbi.nlm.nih.gov]
- 5. Underlying Mechanisms of Bergenia spp. to Treat ... [mdpi.com]
Leucocianidol nuclear magnetic resonance NMR spectrum
Available Chemical Data for Leucocianidol
The table below consolidates the key identified chemical information for this compound from the literature.
| Property | Details |
|---|---|
| IUPAC Name | (2R,3S,4S)-2-(3,4-dihydroxyphenyl)-3,4-dihydro-2H-1-benzopyran-3,4,5,7-tetrol [1] |
| Other Names | Leucocyanidin, 3,3',4,4',5,7-Flavanhexol, Procyanidol [2] [1] |
| Molecular Formula | C₁₅H₁₄O₇ [2] [1] |
| Molecular Weight | 306.27 g/mol [2] [1] |
| CAS Registry Number | 93527-39-0 [2] |
| PubChem CID | 440833 [3] [4] |
| Solubility | Considered very hydrophobic and practically insoluble in water [1] |
| Hydrogen Bond Donors | 6 [2] |
| Hydrogen Bond Acceptors | 7 [2] |
Proposed Workflow for Obtaining the NMR Spectrum
Since experimental NMR data was not found in the current search, the following workflow outlines the recommended steps to acquire it.
Pathway to obtain this compound NMR data
Suggestions for Next Steps
Based on the workflow above, here are specific actions you can take:
- Specialized Natural Product Databases: Search platforms like the Natural Products Magnetic Resonance Database (NP-MRD), which was cited as having predicted spectra for this compound, for any newly uploaded experimental data [1].
- Broader Spectral Libraries: Query major spectral data repositories such as PubChem [3], ChemSpider, or SDBS (Spectral Database for Organic Compounds). Use the known CAS number (93527-39-0) or PubChem CID (440833) for your search.
- Scientific Literature Search: Perform a targeted search on scholarly databases (e.g., SciFinder, Reaxys, Google Scholar) using the terms "this compound NMR," "leucocyanidin NMR," or its IUPAC name. The compound has been isolated from plants like Grewia bicolor and Terminalia arjuna [5] [1], so research papers on these sources are promising.
- Spectral Prediction: If experimental data remains elusive, computational tools can predict NMR shifts. The NP-MRD card indicates that 13C NMR and 1H NMR spectra have already been predicted for this compound, which can serve as a useful reference until experimental data is found [1].
References
Leucocianidol bond critical point BCP analysis
Theoretical Foundation of BCP Analysis
Bond Critical Point analysis within the Quantum Theory of Atoms in Molecules (QTAIM) provides a rigorous framework for understanding chemical bonding beyond traditional models.
- Electron density topology: BCPs are (3,-1) critical points in the electron density field where
∇ρ(r) = 0and the Hessian matrix has two negative and one positive eigenvalues [1] - Bond path identification: The line of maximum electron density connecting two nuclei passes through the BCP, defining the bond path [1]
- Chemical bond interpretation: While BCP existence indicates a bonded interaction, some scholarly debate emphasizes that bond paths should be interpreted cautiously and not automatically equated with chemical bonds in the traditional sense [2]
Computational Methods for Leucocianidol BCP Analysis
The methodology for this compound BCP analysis requires specific computational approaches as detailed in recent research [3]:
1. Density Functional Theory (DFT) Calculations
- Functional: CAM-B3LYP for accurate long-range corrections
- Basis set: def2TZV for polarized triple-zeta quality results
- Environmental considerations: Grimme D3 dispersion correction and IEFPCM solvent model (water) for biological relevance
2. Topological Analysis Protocol
- Software: Gaussian 09 for initial calculations with AIMAll package for QTAIM analysis
- Electron density examination: Identification of (3,-1) critical points in the electron density field
- Complementary analyses: Electron Localization Function (ELF), Molecular Electrostatic Potential (MEP), and Fukui function calculations using Multiwfn package
3. Conformational Sampling
- Systematic variation of the dihedral angle τ (O1–C2–C1′–C6′) in 10° increments
- Assessment of weak interactions between hydroxyl groups of ring B and pyran ring C
Quantitative BCP Parameters and Reactivity
This compound's chemical behavior can be understood through key topological and electronic descriptors. This table summarizes the primary quantitative parameters from BCP analysis:
| Parameter | Value/Range | Chemical Interpretation |
|---|---|---|
| Electron density (ρ) | Varies by bond type | Higher values indicate greater bond strength and covalence |
| Laplacian (∇²ρ) | Positive for closed-shell interactions | Ionic bonds, hydrogen bonding, van der Waals forces |
| Energy density (Hₚ) | Negative for covalent bonds | Degree of covalent character in the interaction |
| ELF localization | 0.0-1.0 scale | Probability of finding electron pairs; higher values indicate shared pairs |
| Fukui function (f⁺) | Nucleophilic attack susceptibility | Regions prone to nucleophilic attack |
| Aromaticity (NICS) | Ring-specific values | Degree of aromatic character in rings A, B, and C |
Key Reactivity Insights:
- Electrophilic susceptibility: Leucoanthocyanidins show highest electrophilic attack susceptibility in ring A, distinct from anthocyanidins and flavonols [3]
- Global reactivity: this compound exhibits moderate electrophilicity with significant nucleophilic character compared to other flavonoids [3]
- Aromaticity patterns: Ring C of this compound shows reduced aromaticity compared to anthocyanidins, influencing its reactivity [3]
Biological Relevance & Drug Development Applications
The BCP analysis of this compound provides crucial insights for its pharmaceutical applications, particularly in complex diseases.
1. Hepatocellular Carcinoma (HCC) Targeting
- This compound demonstrates significant interactions with 98 potential HCC targets, making it a promising multi-target therapeutic candidate [4]
- Network pharmacology reveals this compound's degree centrality of 41 in compound-target networks, indicating robust multi-target engagement [4]
- Protein-protein interaction analysis identifies key hub genes including STAT3, MAPK3, and SRC as potential this compound targets [4]
2. Multi-Target Mechanism of Action This diagram illustrates this compound's polypharmacology in hepatocellular carcinoma:
Figure 2: this compound's multi-target mechanism in hepatocellular carcinoma
3. Gut Microbiome Interactions
- This compound may function as a microbiome-derived metabolite in the gut-liver axis, potentially influencing nonalcoholic fatty liver disease (NAFLD) [5]
- Network pharmacology suggests metabolites from gut microbiota can modulate Toll-like receptor signaling and MAPK pathways, potentially relevant to this compound's activity [5]
Discussion & Research Implications
The BCP analysis of this compound reveals several important implications for drug development:
- Structure-Activity Relationships: The distinct electrophilic susceptibility of ring A in this compound provides a strategic site for chemical modification to enhance specific biological activities [3]
- Multi-Target Therapeutics: this compound's engagement with multiple HCC targets supports the growing paradigm of polypharmacology in complex disease treatment [4]
- Drug Optimization Potential: The reduced aromaticity of ring C compared to anthocyanidins may offer opportunities for structural optimization to improve metabolic stability and target selectivity [3]
References
- 1. Theory of Atoms in Molecules: What is a Bond ? [chemistry.mcmaster.ca]
- 2. Why Bond Are Not " Critical " Points ... | Semantic Scholar Bond Critical [semanticscholar.org]
- 3. Comparative analysis of the reactivity of anthocyanidins... [pmc.ncbi.nlm.nih.gov]
- 4. Underlying Mechanisms of Bergenia spp. to Treat ... [pmc.ncbi.nlm.nih.gov]
- 5. The identification of metabolites from gut microbiota in ... [nature.com]
Leucocianidol aromaticity and electronic properties
Leucocianidol: Chemical Identity & Biological Data
This compound, also known as Leucocyanidin, is a flavan-3,4-diol derivative. The table below summarizes its key physicochemical and biological properties compiled from the search results [1] [2].
| Property | Details |
|---|---|
| Molecular Formula | C₁₅H₁₄O₇ [1] [2] |
| Average Molecular Mass | 306.27 g/mol [2] |
| IUPAC Name | (2R,3S)-2-(3,4-dihydroxyphenyl)-3,4-dihydro-2H-chromene-3,4,5,7-tetrol [2] |
| Appearance | White to off-white solid powder [2] |
| Bioactivity | Naturally occurring anti-ulcerogenic ingredient; demonstrates protective effect against aspirin-induced erosions in rat models; potential for treatment of hemorrhoids [2]. |
| Key Experimental Finding | In rat models, 5 mg daily effectively prevented stomach erosion caused by aspirin [2]. |
Analysis of Aromaticity in this compound
Aromaticity is a key stabilizing property in molecules that meet four specific conditions [3]:
- Cyclic: The molecule must contain a ring of atoms.
- Conjugated: Every atom in the ring must have an available p-orbital, creating a continuous, overlapping system of pi electrons.
- Hückel's Rule: The cyclic, conjugated system must contain (4n + 2) pi electrons (where 'n' is a non-negative integer, e.g., 2, 6, 10...).
- Planar: The entire ring system must be flat for optimal p-orbital overlap.
The following diagram illustrates the workflow for assessing aromaticity, which can be applied to this compound's constituent rings:
Assessment Workflow for Aromaticity
Applying this framework to this compound's structure [2]:
- Ring A (Left Benzene Ring): This is a standard benzene ring, which is cyclic, conjugated, planar, and has 6 π electrons - it fulfills all criteria for aromaticity [3] [4].
- Ring C (Right Chroman Ring): This oxygen-containing heterocyclic ring is not fully conjugated. The saturated carbons at positions 3 and 4 are (sp^3)-hybridized and lack p-orbitals, breaking the continuous conjugation - it is non-aromatic [3].
Therefore, this compound contains one aromatic component (Ring A) and one non-aromatic component (Ring C). The molecule as a whole is not aromatic.
A Path Forward for Research
To build the in-depth technical guide you require, here are suggested next steps:
- Locate Specialized Literature: Conduct a detailed search on platforms like SciFinder, Reaxys, or Web of Science using terms like "leucocyanidin electronic properties," "molecular orbital analysis leucocyanidin," or "leucocyanidin DFT study."
- Computational Chemistry Studies: Research papers that perform Density Functional Theory (DFT) calculations on this compound can provide the missing data, such as HOMO-LUMO energies, electrostatic potential maps, and molecular orbital diagrams.
- Experimental Spectral Data: Look for studies that include Nuclear Magnetic Resonance (NMR) chemical shifts, particularly proton NMR in aromatic regions, and UV-Vis absorption spectra, which can provide experimental evidence for electronic transitions and conjugation [4].
References
Comprehensive LC-MS Analysis of Leucocianidol in Plant Extracts: Application Notes and Protocols
Introduction to Leucocianidol and Analytical Considerations
This compound (also known as leucocyanidin) is a flavan-3,4-diol type flavonoid with the molecular formula C~15~H~14~O~7~ and molecular weight of 306.27 g/mol. This phytochemical has gained significant research interest due to its favorable pharmacokinetic properties, including an oral bioavailability of 30.84% and drug likeness (DL) score of 0.27, making it a promising candidate for pharmaceutical development [1]. This compound belongs to the proanthocyanidin class of flavonoids and serves as a biochemical precursor to cyanidin and various condensed tannins. Its presence has been documented in several medicinal plants, including various Bergenia species (Saxifragaceae family), where it contributes to the reported therapeutic properties of these plants [1].
The analysis of this compound in plant matrices presents several analytical challenges due to the complexity of plant extracts, the presence of numerous structurally similar flavonoids, and the compound's specific chemical properties. Liquid Chromatography coupled with Mass Spectrometry (LC-MS) has emerged as the technique of choice for the precise identification and quantification of this compound in complex plant matrices due to its high sensitivity, selectivity, and ability to provide structural information through fragmentation patterns. This application note provides detailed protocols for the comprehensive analysis of this compound in plant extracts, including sample preparation, LC-MS analysis, method validation, and data interpretation strategies specifically tailored for researchers and drug development professionals.
Fundamental Properties of this compound
Table 1: Fundamental physicochemical properties of this compound
| Property | Specification | Analytical Significance |
|---|---|---|
| Molecular Formula | C~15~H~14~O~7~ | Determines exact mass for MS detection (306.27 Da) |
| IUPAC Name | (2R,3S)-2-(3,4-Dihydroxyphenyl)-3,4-dihydro-2H-chromene-3,4,5,7-tetrol | Understanding stereochemistry and isomer separation needs |
| Oral Bioavailability | 30.84% | Indicates pharmaceutical relevance [1] |
| Drug Likeness Score | 0.27 | Qualifies as drug-like compound [1] |
| PubChem CID | 440833 | Reference for spectral databases [1] |
| Hydrogen Bond Donors | 6 | Impacts reverse-phase chromatography retention |
| Hydrogen Bond Acceptors | 7 | Influences ionization efficiency in MS |
Sample Preparation Protocols
Plant Material Selection and Extraction
Proper sample preparation is critical for the accurate analysis of this compound in plant matrices. The following protocol has been optimized for various plant tissues, including leaves, roots, and rhizomes:
Plant Material Collection: Collect fresh plant specimens from controlled environments. For Bergenia species, mature leaves have shown significant this compound content [1]. Properly document the plant source with voucher specimens deposited in herbariums for reference.
Drying and Homogenization: Air-dry plant materials at room temperature for 5-7 days protected from direct sunlight to prevent photodegradation. Alternatively, use lyophilization for heat-sensitive compounds. Homogenize dried materials using a heavy-duty blender to obtain a fine powder (particle size <0.5 mm) to ensure uniform extraction [2].
Extraction Procedure: Weigh 100 g of homogenized plant material and extract with 1 L of aqueous ethanol (70% v/v) using reflux extraction at 80°C for 60 minutes. Alternative solvents include methanol-water mixtures (80:20 v/v) or pure water for specific applications. The aqueous extraction method has been successfully applied to similar flavonoids, involving boiling in distilled water for 10 minutes followed by cooling and filtration [2].
Extract Concentration: Concentrate the filtered extract under reduced pressure at 40°C using a rotary evaporator. Lyophilize the concentrated extract and store at -20°C protected from light and moisture until analysis [2].
Extract Clean-up and Pre-concentration
For complex plant matrices, additional clean-up steps may be necessary to reduce matrix effects and enhance analytical sensitivity:
Solid-Phase Extraction (SPE): Use C~18~ cartridges (500 mg/6 mL) preconditioned with 5 mL methanol followed by 5 mL acidified water (0.1% formic acid). Load the reconstituted extract (1 mg/mL in acidified water), wash with 5 mL acidified water (5% methanol), and elute this compound with 5 mL methanol-acidified water (70:30 v/v) containing 0.1% formic acid.
Membrane Filtration: Prior to LC-MS analysis, filter all samples through 0.22 μm nylon or PVDF membrane filters to remove particulate matter that could damage LC columns or affect MS ionization.
LC-MS Analysis Conditions
Liquid Chromatography Parameters
Table 2: Optimized LC conditions for this compound separation
| Parameter | Specification | Alternative Options |
|---|---|---|
| Column | Thermo Syncronis C~18~ (2.1 × 100 mm, 1.7 μm) | Any equivalent UHPLC C~18~ column with 1.7-1.8 μm particles |
| Column Temperature | 55°C | 40-60°C (optimize for retention time stability) |
| Flow Rate | 450 μL/min | 300-500 μL/min (adjust for backpressure) |
| Injection Volume | 2 μL | 1-5 μL (depending on concentration) |
| Mobile Phase A | 0.1% Formic acid in HPLC-grade water | 0.1% Acetic acid in water or ammonium acetate buffer |
| Mobile Phase B | 0.1% Formic acid in acetonitrile | 0.1% Formic acid in methanol |
| Gradient Program | Time (min) | %B |
| 0 | 0.5 | |
| 1 | 0.5 | |
| 15 | 95.5 | |
| 19 | 95.5 | |
| 19.1 | 0.5 | |
| 21 | 0.5 |
The chromatographic conditions have been adapted from validated methods for flavonoid analysis [3] [2]. The use of acidic mobile phases enhances peak shape for phenolic compounds through suppression of silanol interactions, while the carefully optimized gradient provides optimal separation of this compound from structurally similar flavonoids and matrix components.
Mass Spectrometry Conditions
Instrumentation: Thermo Scientific Q Exactive HF Orbitrap mass spectrometry system or equivalent high-resolution MS system. Alternative triple quadrupole instruments can be used for targeted quantification [2].
Ion Source: Electrospray Ionization (ESI) in negative ion mode has been found optimal for this compound detection due to the compound's phenolic structure.
MS Parameters: Set spray voltage to 3.2 kV (negative mode), capillary temperature to 320°C, sheath gas flow to 45 arbitrary units, and auxiliary gas flow to 15 arbitrary units. For MS/MS analysis, use normalized collision energy of 30-35 eV for fragmentation [2].
Data Acquisition: For quantification, use Multiple Reaction Monitoring (MRM) if using a triple quadrupole instrument, monitoring the transition 305→125 m/z (deprotonated molecule to characteristic fragment). For high-resolution instruments, use Full MS/dd-MS² (data-dependent MS²) with inclusion list for this compound.
Method Validation Parameters
To ensure reliability and reproducibility of the analytical method, comprehensive validation should be performed following ICH M10 guidelines on bioanalytical method validation [4]. The following table summarizes key validation parameters:
Table 3: Method validation parameters for this compound quantification
| Validation Parameter | Acceptance Criteria | Recommended Protocol |
|---|---|---|
| Linearity Range | 0.10-25.0 μM | Prepare 8-point calibration curve with R² > 0.995 |
| Lower Limit of Quantification (LLOQ) | Signal-to-noise ratio ≥ 10 | 0.10 μM for this compound standard |
| Precision (Intra-day) | RSD ≤ 15% (≤20% at LLOQ) | Analyze 6 replicates at 4 QC levels in single day |
| Precision (Inter-day) | RSD ≤ 15% (≤20% at LLOQ) | Analyze 6 replicates at 4 QC levels over 3 days |
| Accuracy | 85-115% recovery (80-120% at LLOQ) | Compare measured vs. spiked concentrations |
| Matrix Effects | 85-115% with RSD ≤ 15% | Post-extraction addition method |
| Recovery | Consistent and reproducible | Compare extracted vs. pure standard responses |
| Stability | ≤15% deviation from fresh sample | Evaluate bench-top, processed, and long-term stability |
The validation approach should follow established bioanalytical method validation protocols as described in recent pharmaceutical analysis research [4]. Specific attention should be paid to matrix effects in plant extracts, which can significantly impact quantification accuracy due to ion suppression or enhancement effects in the MS source.
Data Processing and Analysis
Modern LC-MS data processing for plant metabolomics employs sophisticated software platforms that enable comprehensive compound identification and quantification:
Feature Detection and Alignment: Use software such as Thermo Scientific Compound Discoverer 3.3, MZmine, or XCMS for peak picking, retention time alignment, and feature detection across multiple samples. The non-targeted analysis workflow should include background subtraction, retention time alignment, feature detection, and elemental composition determination [3] [2].
Compound Identification: Confidently identify this compound by matching retention time, exact mass (m/z 305.0667 for [M-H]⁻), and MS/MS fragmentation pattern with authentic standards when available. For tentative identification without standards, combine accurate mass measurements with in silico MS/MS spectral matching using databases such as mzCloud and ChemSpider [2].
Molecular Networking: Implement Feature-Based Molecular Networking (FBMN) to visualize the relationship between this compound and structurally related compounds in the extract. This approach has proven valuable for comprehensive chemical characterization of complex plant extracts and can help identify potential isomers or derivatives of this compound [3].
The following diagram illustrates the complete analytical workflow from sample preparation to data interpretation:
Applications in Phytochemical Research
The described LC-MS method for this compound analysis has several important applications in phytochemical and pharmaceutical research:
Quality Control of Herbal Preparations: this compound can serve as a marker compound for standardization of herbal preparations containing Bergenia species and other medicinal plants. The method enables precise quantification to ensure batch-to-batch consistency and product quality [1].
Network Pharmacology Studies: this compound has been identified as a multi-targeting compound in network pharmacology models, with 41 potential gene targets related to various disease pathways. Accurate quantification is essential for correlating compound levels with biological activities [1].
Biosynthetic Pathway Elucidation: The method can be applied to study the biosynthesis and metabolism of this compound in plants, helping to understand its role as a biochemical precursor to other important flavonoids.
Bioavailability and Pharmacokinetic Studies: With its established oral bioavailability of 30.84%, this compound represents a promising candidate for further pharmaceutical development. The LC-MS method can be adapted for pharmacokinetic studies to monitor absorption, distribution, metabolism, and excretion.
Troubleshooting and Technical Considerations
Peak Tailing: If this compound peak shows significant tailing, increase formic acid concentration to 0.2% or switch to a column with lower metal ion content. Peak tailing for phenolic compounds often results from secondary interactions with residual silanols.
Retention Time Shifts: For retention time instability, ensure consistent column temperature and adequate mobile phase equilibration between runs. Consider using a column pre-saturator to maintain silica saturation.
Sensitivity Issues: If sensitivity is inadequate for trace analysis, consider switching to positive ion mode with ammonium formate buffer, which sometimes provides better ionization for certain dihydroflavonols.
Matrix Effects: Significant matrix suppression or enhancement can be addressed by optimizing the sample clean-up procedure or using standard addition quantification rather than external calibration.
Conclusion
The LC-MS method described in this application note provides a robust, sensitive, and specific approach for the identification and quantification of this compound in complex plant extracts. The method leverages advanced chromatographic separation coupled with high-resolution mass spectrometry to overcome the analytical challenges posed by complex plant matrices and the presence of structurally similar flavonoids. With appropriate validation following ICH M10 guidelines, this method can be applied to various research areas including phytochemical characterization, quality control of herbal medicines, and pharmacokinetic studies. The protocols outlined here provide researchers and drug development professionals with comprehensive technical guidance for implementing this analysis in their laboratories.
References
- 1. Underlying Mechanisms of Bergenia spp. to Treat ... [pmc.ncbi.nlm.nih.gov]
- 2. LC-MS/MS and GC-MS Analysis for the Identification of ... [mdpi.com]
- 3. A Mass Spectrometry Based Metabolite Profiling Workflow ... [pmc.ncbi.nlm.nih.gov]
- 4. Validation of an LC-MS/MS Method for the Simultaneous ... [pmc.ncbi.nlm.nih.gov]
Leucocianidol extraction and purification protocols
Chemical Profile of Leucocianidol
This compound, also known as leucocyanidin, is a flavan-3,4-diol belonging to the leucoanthocyanidin class of flavonoids [1] [2]. The table below summarizes its key identifiers and properties:
| Property | Description |
|---|---|
| Systematic IUPAC Name | (2R,3S,4S)-2-(3,4-Dihydroxyphenyl)-3,4-dihydro-2H-1-benzopyran-3,4,5,7-tetrol [1] |
| Other Names | Leucocyanidin, Leucocyanidol, Procyanidol, Resivit, Vitamin P faktor [3] [1] |
| CAS Number | 480-17-1 [3], 93527-39-0 [4] |
| Molecular Formula | C₁₅H₁₄O₇ [3] [4] [1] |
| Molecular Weight | 306.27 g/mol [3] [1] |
| Physical Description | Colorless chemical compound [1] |
| Solubility | Soluble in DMSO (80 mg/mL, 261.21 mM). Suggested in vivo formulation: 10% DMSO + 40% PEG300 + 5% Tween 80 + 45% Saline [3]. |
General Extraction and Isolation Workflow
While a specific protocol for this compound is not detailed, the following diagram synthesizes a general approach based on its isolation from plant materials like Grewia bicolor leaves and Aesculus hippocastanum (horse chestnut) seeds [3] [5].
The key steps involve:
- Maceration Extraction: Plant material is macerated in a solvent. Research indicates the use of methanol for successful isolation of this compound from Grewia bicolor leaves [5]. Acetone can also be used as an initial solvent for plant maceration [5].
- Chromatographic Purification: The crude extract is subjected to repeated purification using chromatographic columns packed with silica gel to isolate individual compounds [5].
- Compound Identification: The final step involves confirming the chemical structure of the isolated compound using spectroscopic methods, primarily Nuclear Magnetic Resonance (NMR) and Mass Spectrometry (MS) [5].
Analytical Methods for Verification
Once a compound is isolated, the following parameters can be used to verify its identity as this compound.
| Method | Parameters / Expected Outcome |
|---|---|
| NMR Spectroscopy | ¹H and ¹³C NMR data for structure elucidation [5]. |
| Mass Spectrometry (MS) | Molecular ion peak at m/z 306.27 (corresponding to C₁₅H₁₄O₇) [3] [4]. |
| Specific Rotation | The compound is dextrorotatory; synthetic (+)-leucocyanidin can be produced from (+)-dihydroquercetin [1]. |
| Silica Gel TLC | Used for monitoring fraction purity during column chromatography [5]. Specific Rf values for this compound are not provided in the search results. |
Research Context and Potential Applications
Understanding the potential bioactivities of this compound can help define the goals of your extraction work. Current research highlights several promising areas:
- Anti-inflammatory Activity: In a study on Grewia bicolor leaf extracts, isolated this compound demonstrated significant anti-inflammatory activity, measured by its ability to inhibit heat-induced denaturation of bovine serum albumin (BSA). This activity was more potent than that of other flavonoids isolated from the same plant [5].
- Metabolic and Liver Disease Research: this compound is described as a compound that can be used to study non-alcoholic fatty liver disease (NAFLD) [3]. Furthermore, it was identified as a potential active compound in Bergenia species for targeting genes related to hepatocellular carcinoma (HCC), suggesting a role in cancer research [6].
- Antiulcer Properties: It is identified as an antiulcer compound extracted from horse chestnut seeds (Aesculus hippocastanum) [3].
Important Notes for Protocol Development
- Solvent Selection: The choice of solvent (methanol, acetone, or others) can significantly impact the yield and profile of extracted compounds. You may need to optimize this for your specific plant source.
- Chromatography Conditions: The search results confirm that silica gel is a suitable stationary phase but do not specify the mobile phase (eluent). Developing the right solvent system for elution will be a critical part of your method development.
- Compound Stability: this compound is a colorless leucoanthocyanidin and can be a precursor to other compounds [1] [2]. Its stability should be considered during extraction and purification to prevent degradation or condensation.
I hope this structured overview provides a solid foundation for your work. If you have access to a specific plant source and would like to delve deeper into optimizing a particular step, feel free to ask.
References
Comprehensive HPLC Method Development and Validation for Leucocyanidol Quantification in Natural Products and Pharmaceuticals
Introduction
Leucocyanidol, a flavan-3,4-diol type of flavonoid, represents an important class of natural compounds with significant pharmacological potential. As research into flavonoids continues to reveal their diverse health benefits, the development of robust analytical methods for their quantification becomes increasingly important for both pharmaceutical development and quality control of natural products. High Performance Liquid Chromatography (HPLC) stands as the gold standard technique for flavonoid analysis due to its superior resolution, sensitivity, and reproducibility. This application note provides a comprehensive protocol for HPLC method development and validation specifically tailored for leucocyanidol quantification, addressing the growing need for standardized analytical approaches for this compound.
The complex nature of plant extracts and pharmaceutical formulations presents significant challenges for analytical method development, particularly due to the presence of structural analogs and co-eluting compounds that may interfere with accurate quantification. Furthermore, flavonoids like leucocyanidol often exist in multiple isomeric forms and exhibit specific UV-Vis absorption characteristics that must be considered during method development. This document synthesizes current HPLC methodologies with specific adaptations for leucocyanidol's chemical properties, providing researchers with a systematic approach that can be implemented in various analytical settings, from basic research to regulatory-compliant quality control laboratories.
HPLC Method Development Strategy
HPLC Method Selection and Initial System Configuration
The selection of an appropriate HPLC method represents the foundational step in developing a reliable quantification protocol for leucocyanidol. Based on the chemical properties of flavonoids and existing analytical approaches for similar compounds, reversed-phase chromatography (RPC) emerges as the most suitable technique due to its versatility, reproducibility, and ability to handle complex samples. As noted in pharmaceutical analysis, RPC is particularly valuable because it "provides reassurance that everything that goes into the column comes out again; there is 100% mass balance" [1], which is critical for accurate quantification and impurity profiling. This characteristic ensures no compounds are retained in the column that could skew quantification results in subsequent analyses.
For leucocyanidol analysis, the following initial system configuration is recommended:
Stationary Phase: C18 bonded silica column (150 × 4.6 mm, 3 or 5 μm particle size) provides an optimal balance of separation efficiency, backpressure, and analysis time. The hydrophobic interactions between the leucocyanidol molecule and the C18 ligands facilitate adequate retention and separation from potential interferents.
Detection System: UV-Vis Diode Array Detector (DAD) set at 280 nm as primary detection wavelength, based on the characteristic absorption maxima of flavan-3,4-diols. The DAD enables spectral confirmation of peak identity and purity assessment through comparison with reference standards.
Mobile Phase System: Binary system consisting of aqueous component (water or buffer) and organic modifier (acetonitrile or methanol). Initial testing should employ a gradient elution to assess the retention characteristics of leucocyanidol and potential matrix components. As recommended in method development guidelines, "try the most common columns and stationary phases first" and "thoroughly investigate binary mobile phases before going on to ternary" [2].
The selection of this initial configuration aligns with the established practice where "reverse phase is the choice for the majority of samples" [2], particularly for compounds with moderate polarity like leucocyanidol. This approach provides a solid foundation that can be systematically optimized to address specific analytical challenges.
Selection of Initial Conditions
Establishing appropriate initial conditions is crucial for achieving adequate retention and separation of leucocyanidol from sample matrix components. The solvent strength of the mobile phase must be carefully controlled to ensure leucocyanidel has a capacity factor (k) between 1.5 and 10, which represents the optimal balance between retention and analysis time. For method development, "the recommended method involves performing two gradient runs differing only in the run time" [2] to establish the optimal solvent profile.
Table 1: Initial Mobile Phase Gradient for Leucocyanidol Method Scouting
| Time (min) | % Aqueous (0.1% FA) | % Organic (ACN) | Flow Rate (mL/min) |
|---|---|---|---|
| 0 | 95 | 5 | 1.0 |
| 2 | 95 | 5 | 1.0 |
| 15 | 5 | 95 | 1.0 |
| 18 | 5 | 95 | 1.0 |
| 18.1 | 95 | 5 | 1.0 |
| 23 | 95 | 5 | 1.0 |
For leucocyanidol analysis, the aqueous component should be modified with acid modifiers such as 0.1% formic acid or phosphoric acid to suppress ionization of acidic functional groups and improve peak shape. The initial conditions should be tested with both acetonitrile and methanol as organic modifiers to determine which provides superior separation. As observed in the development of methods for similar compounds, "the first attempts to develop a practical method for quantification... used different proportions of acidified water (H₂O)/acetonitrile (ACN)/methanol (MeOH) (v/v/v) in isocratic conditions" [3], but gradient elution often proves necessary for complex samples.
The initial column temperature should be set at 30°C to ensure retention time reproducibility, with the option to increase to 40°C if necessary to reduce backpressure or improve efficiency. Injection volume should be optimized based on expected leucocyanidol concentrations, typically starting with 10 μL for standard solutions. These initial conditions provide a baseline from which systematic optimization can proceed, balancing the need for comprehensive method assessment with efficient use of development resources.
Selectivity Optimization Strategies
Selectivity optimization represents the most critical phase of method development, focusing on achieving baseline separation between leucocyanidol and potential interferents present in sample matrices. The complex nature of botanical extracts and pharmaceutical formulations necessitates a systematic approach to selectivity enhancement. For leucocyanidol analysis, optimization should prioritize parameters with the greatest potential impact on separation, beginning with mobile phase composition and progressively addressing secondary factors.
Table 2: Selectivity Optimization Parameters for Leucocyanidol HPLC Analysis
| Parameter | Options to Evaluate | Expected Impact on Selectivity |
|---|---|---|
| Organic Modifier | Acetonitrile vs. Methanol | Significant differences in selectivity due to distinct separation mechanisms |
| Aqueous Phase pH | 2.5, 3.5, 4.5 (using formate or phosphate buffers) | Moderate to significant impact on ionization state and retention |
| Buffer Concentration | 10-50 mM | Minor to moderate effects on peak shape and retention |
| Stationary Phase | C18, phenyl, polar-embedded C18 | Significant differences in selectivity through alternative molecular interactions |
| Temperature | 30°C, 40°C, 50°C | Minor effects on retention and efficiency |
The optimization process should follow a structured sequence, beginning with mobile phase parameters before considering stationary phase alternatives. As outlined in method development guidelines, "optimization of mobile phase parameters is always considered first as this is much easier and convenient than stationary phase optimization" [2]. For leucocyanidol, particular attention should be paid to pH optimization, as the compound's phenolic hydroxyl groups will undergo ionization at higher pH values, significantly altering retention characteristics. The optimal pH should provide adequate retention while maintaining symmetric peak shape.
If initial selectivity remains inadequate after mobile phase optimization, alternative stationary phases should be investigated. Phenyl columns have demonstrated particular utility for flavonoid separations, as evidenced in a method for 3-deoxyanthocyanidins where "the selected method used a silica-based phenyl column" [3]. The π-π interactions between the phenyl stationary phase and the aromatic rings of leucocyanidol can provide complementary separation mechanisms to the hydrophobic interactions of C18 phases. Similarly, polar-embedded groups can offer alternative selectivity for more hydrophilic flavonoids or glycosylated derivatives.
Method Validation Protocol
Validation Experiments and Acceptance Criteria
Method validation provides documented evidence that the analytical method is suitable for its intended purpose, ensuring the reliability, accuracy, and reproducibility of leucocyanidol quantification. The validation protocol should be comprehensive, addressing all parameters specified in regulatory guidelines such as ICH Q2(R1). The experiments must be carefully designed with statistically appropriate replication and relevant acceptance criteria that reflect the intended application of the method.
Table 3: Method Validation Parameters and Acceptance Criteria for Leucocyanidol Quantification
| Validation Parameter | Experimental Design | Acceptance Criteria |
|---|---|---|
| Linearity & Range | 5-7 concentrations in triplicate from 50-150% of target | R² ≥ 0.999; residuals randomly distributed |
| Accuracy | Spike recovery at 3 levels (50%, 100%, 150%) in triplicate | Mean recovery 98-102%; RSD ≤ 2% |
| Precision (Repeatability) | 6 replicates at 100% concentration | RSD ≤ 1% for retention time; RSD ≤ 2% for area |
| Intermediate Precision | 6 replicates on different days, by different analysts | RSD ≤ 2% for retention time and area |
| Specificity | Analysis of placebo, blank, and stressed samples | Resolution ≥ 2.0 from closest eluting peak; peak purity ≥ 0.999 |
| Detection Limit (LOD) | Signal-to-noise ratio of 3:1 | S/N ≥ 3; typically 0.5-1.0 μg/mL |
| Quantitation Limit (LOQ) | Signal-to-noise ratio of 10:1 | S/N ≥ 10; typically 1.5-3.0 μg/mL |
| Robustness | Deliberate variations in key parameters (temperature ±2°C, pH ±0.2, flow ±10%) | RSD ≤ 2% for retention time and area under all conditions |
The specificity demonstration should include forced degradation studies (acid/base hydrolysis, oxidative, thermal, and photolytic stress) to establish the method's ability to quantify leucocyanidol in the presence of potential degradants. As emphasized in pharmaceutical analysis, "the HPLC method must be able to separate the main component... and all impurities including degradation products" [1]. For leucocyanidol, this is particularly important given the compound's potential sensitivity to oxidative degradation.
The robustness testing should employ an experimental design approach (such as Plackett-Burman or fractional factorial designs) to efficiently evaluate multiple parameters simultaneously while identifying potential interactions between variables. The results establish a method operable design region within which variations do not significantly affect method performance. As noted in validation guidelines, "robustness testing is done to determine the impact of changing parameters of the separation method" [4], making it essential for methods intended for technology transfer or regulatory submission.
System Suitability Testing
System suitability tests (SST) verify that the complete analytical system—comprising instrument, reagents, column, and analyst—is performing adequately at the time of analysis. For leucocyanidol quantification, SST parameters should be established during method validation and monitored throughout the method's lifecycle. These tests serve as a quality control measure, ensuring the reliability of generated data.
The following SST parameters should be evaluated each analysis day using a freshly prepared leucocyanidol standard solution at the target concentration:
- Theoretical plates (N): ≥ 5000, calculated for the leucocyanidol peak to confirm adequate column efficiency
- Tailing factor (T): ≤ 1.5 for the leucocyanidol peak to ensure symmetric peak shape
- Repeatability: RSD ≤ 1% for peak area from five consecutive injections
- Resolution (Rs): ≥ 2.0 between leucocyanidol and the closest eluting peak in system suitability mixture
- Retention time stability: RSD ≤ 1% for leucocyanidol peak across suitability injections
These parameters should be verified before sample analysis commences, with predetermined corrective actions defined for out-of-specification results. As emphasized in quality control settings, "the ability to control this quality is dependent upon the ability of the analytical methods, as applied under well-defined conditions and at an established level of sensitivity, to give a reliable demonstration of all deviation from target criteria" [2]. The SST provides this assurance for each analytical run.
Application Notes and Practical Protocols
Sample Preparation Techniques
Proper sample preparation is essential for accurate leucocyanidol quantification, serving to extract the analyte from the sample matrix, remove potential interferents, and present the analyte in a form compatible with the HPLC system. The complexity of sample preparation should be matched to the sample matrix complexity, with simpler approaches preferred when adequate for the analytical requirements. As emphasized in HPLC guidelines, "sample preparation is central to successful HPLC and UHPLC analyses" [4].
For botanical raw materials and plant extracts, the following protocol is recommended:
Homogenization: Reduce plant material to fine powder using a mechanical grinder to ensure representative sampling and improve extraction efficiency.
Extraction: Weigh approximately 100 mg of homogenized material into a conical flask. Add 10 mL of methanol:water (70:30, v/v) containing 0.1% hydrochloric acid. The acid helps stabilize leucocyanidol during extraction.
Sonication: Sonicate the mixture for 30 minutes at 40°C, then centrifuge at 5000 × g for 10 minutes. Transfer the supernatant to a volumetric flask.
Re-extraction: Repeat the extraction twice more with fresh solvent, combining the supernatants.
Dilution: Make up to volume with extraction solvent, then filter through a 0.45 μm PTFE or nylon membrane filter before HPLC analysis.
For pharmaceutical formulations such as tablets or capsules:
Powdering: Grind not less than 20 tablets into a homogeneous powder using a mortar and pestle.
Extraction: Accurately weigh a portion equivalent to approximately 5 mg of leucocyanidol into a volumetric flask. Add 20 mL of mobile phase A, sonicate for 15 minutes, then dilute to volume with the same solvent.
Clarification: Centrifuge an aliquot at 5000 × g for 10 minutes, then filter the supernatant through a 0.45 μm membrane filter.
The selection of extraction solvent, time, and technique should be optimized for specific sample matrices, with extraction efficiency verified through recovery studies. As noted in analytical protocols, "there are many sample preparation techniques established, and each method has a particular benefit or specific application" [4]. The recommended protocols provide a starting point that can be adapted to specific analytical needs.
Troubleshooting Common Issues
Despite careful method development, analysts may encounter challenges during method implementation or transfer. The following table addresses common issues specific to leucocyanidol analysis with recommended corrective actions:
Table 4: Troubleshooting Guide for Leucocyanidol HPLC Analysis
| Problem | Potential Causes | Corrective Actions |
|---|---|---|
| Peak Tailing | Secondary interactions with residual silanols; inappropriate mobile phase pH | Add 0.1% acid modifier; use end-capped columns; reduce injection volume |
| Retention Time Drift | Mobile phase evaporation; column degradation; temperature fluctuations | Prepare fresh mobile phase daily; use column heater; monitor column performance with standards |
| Poor Resolution | Inadequate selectivity; co-elution; column degradation | Optimize mobile phase composition; adjust gradient profile; replace aged column |
| Low Recovery | Incomplete extraction; analyte degradation; adsorption losses | Optimize extraction conditions; add antioxidant to solvents; use silanized vials |
| Retention Time Shift | Mobile phase composition change; column temperature variation | Prepare mobile phase accurately; use column thermostat |
When troubleshooting, a systematic approach is essential, changing only one parameter at a time while carefully documenting all modifications. As noted in HPLC guidance, "following a published method is great when it works, however, what happens when the chromatography fails and you don't understand why there are certain components in the mobile phase?" [5]. Understanding the function of each mobile phase component is crucial for effective troubleshooting.
For persistent issues, consideration should be given to alternative detection strategies. While UV detection at 280 nm is suitable for most applications, fluorescence detection (excitation 280 nm, emission 320 nm) may offer improved selectivity for complex matrices, while LC-MS provides definitive identification and enhanced sensitivity for trace analysis. The detection strategy should align with the analytical requirements and available instrumentation.
Workflow Visualization
The following diagram illustrates the comprehensive workflow for HPLC method development and validation for leucocyanidol quantification, integrating all stages from initial planning through implementation:
HPLC Method Development Workflow for Leucocyanidol
Conclusion
This comprehensive application note provides a structured framework for developing, validating, and implementing an HPLC method for the quantification of leucocyanidol in various matrices. The systematic approach outlined—beginning with appropriate method selection, progressing through structured optimization, and concluding with rigorous validation—ensures the generation of reliable, reproducible data suitable for research, quality control, and regulatory applications. The provided protocols balance scientific rigor with practical implementation considerations, enabling analysts to adapt the methodology to specific analytical needs.
The critical importance of method validation cannot be overstated, particularly for methods intended to support product quality assessments or regulatory submissions. As emphasized in pharmaceutical analysis, "proper validation of analytical methods is important for pharmaceutical analysis when ensurance of the continuing efficacy and safety of each batch manufactured relies solely on the determination of quality" [2]. The validation framework presented aligns with international regulatory requirements while addressing the specific analytical challenges associated with leucocyanidol quantification.
As analytical technologies continue to evolve, the fundamental principles outlined in this document provide a foundation that can be adapted to emerging platforms such as UHPLC (Ultra-High Performance Liquid Chromatography), which offers enhanced resolution, sensitivity, and throughput. As noted in technological advances, "HPLC conducted at pressures above 15,000 psi is generally referred to as ultra-high-pressure liquid chromatography (UHPLC)" [1], representing a potential future direction for method enhancement. Regardless of the specific platform, the systematic approach to method development and validation presented here remains essential for generating scientifically sound analytical data.
References
- 1. Expediting HPLC in Pharmaceutical Analysis Method Development [news-medical.net]
- 2. HPLC Method Development and Validation for ... [pharmtech.com]
- 3. Validation of a New HPLC-DAD Method to Quantify 3 ... [mdpi.com]
- 4. HPLC Method Development Steps [thermofisher.com]
- 5. Confusion | CHROMacademy HPLC Method [chromacademy.com]
Comprehensive Application Notes and Protocols for Leucocianidol Network Pharmacology Research
Introduction to Leucocianidol and Network Pharmacology
This compound (also known as leucocyanidin) is a naturally occurring flavan-3,4-diol compound belonging to the proanthocyanidin class, widely found in various medicinal plants. This phytochemical has garnered significant research interest due to its diverse biological activities, including antioxidant, anti-inflammatory, and immunomodulatory properties. Recent studies have explored its potential therapeutic applications for complex diseases such as systemic lupus erythematosus (SLE) and cancer using network pharmacology approaches [1]. Network pharmacology represents a paradigm shift in drug discovery that moves beyond the traditional "one drug-one target" model to a more comprehensive network-based approach that can better capture the complex mechanisms underlying natural product efficacy [2]. This methodology is particularly well-suited for studying multi-target compounds like this compound, as it integrates bioinformatics, cheminformatics, and network visualization to elucidate complex compound-target-pathway-disease relationships.
The fundamental premise of network pharmacology is that the therapeutic effects of natural compounds occur through synergistic interactions with multiple biological targets rather than single target modulation. For this compound specifically, recent research has demonstrated its ability to interact with multiple key targets simultaneously. One study identified this compound as having favorable binding affinities (less than -4.5 kcal/mol) for all 10 core targets investigated in SLE, with particularly stable binding observed with the ESR1 (estrogen receptor 1) complex during molecular dynamics simulations [1]. These findings highlight the importance of employing network-based approaches to fully understand the polypharmacology of this natural compound.
Key Physicochemical and Pharmacokinetic Properties of this compound
Understanding the fundamental properties of this compound is essential for designing appropriate experimental protocols and interpreting research findings. The table below summarizes the key characteristics of this compound based on current research data:
Table 1: Physicochemical and Drug-likeness Parameters of this compound
| Property | Value | Description/Implication |
|---|---|---|
| Molecular Formula | C~15~H~14~O~7~ | Flavonoid structure with multiple oxygen atoms |
| Molecular Weight | 306.29 g/mol | Within drug-like range (<500 g/mol) |
| Oral Bioavailability (OB) | 30.84% | Meets minimum criteria for drug-likeness (OB > 30%) |
| Drug Likeness (DL) | 0.27 | Exceeds common threshold for drug-likeness (DL > 0.18) |
| PubChem CID | 440833 | Public database identifier for chemical structure |
| Hydrogen Bond Donors | 5 | Capable of forming multiple hydrogen bonds |
| Hydrogen Bond Acceptors | 7 | Contributes to solubility and target interactions |
These properties make this compound a promising candidate for further drug development investigations. The compound's structural features include multiple phenolic hydroxyl groups that facilitate interactions with various biological targets through hydrogen bonding and π-π stacking interactions. The satisfactory oral bioavailability and drug-likeness scores indicate that this compound possesses physicochemical properties compatible with potential therapeutic application, adhering to the Lipinski's rule of five for drug-likeness [3] [4].
Experimental Workflow for this compound Network Pharmacology
Network pharmacology research follows a systematic workflow that integrates multiple computational and experimental approaches. The following diagram illustrates the comprehensive research pipeline for investigating this compound's mechanisms:
Figure 1: Comprehensive Workflow for this compound Network Pharmacology Research
This workflow encompasses both computational predictions and experimental validations, ensuring a comprehensive approach to understanding this compound's pharmacological mechanisms. The process begins with target identification and progresses through network analysis, enrichment studies, and computational validation, potentially culminating in in vitro and in vivo verification. Each stage builds upon the previous one, creating a systematic framework for elucidating the polypharmacological profiles of natural compounds like this compound [1] [3] [5].
Detailed Experimental Protocols
Target Identification and Database Mining Protocol
Objective: To identify potential protein targets of this compound using publicly available databases and prediction tools.
Materials and Software:
- Compound structure file (SMILES, SDF, or MOL2 format)
- SwissTargetPrediction database (http://www.swisstargetprediction.ch/)
- STITCH database (http://stitch.embl.de/)
- TCMSP database (http://tcmspw.com/tcmsp.php)
- GeneCards database (https://www.genecards.org/)
- DisGeNET database (https://www.disgenet.org/)
- R software with bioinformatics packages or Python with bioservices library
Step-by-Step Procedure:
- Obtain Canonical SMILES: Retrieve the canonical SMILES string for this compound (PubChem CID: 440833) using the PubChem database.
- Target Prediction:
- Input the SMILES string into SwissTargetPrediction with organism set to "Homo sapiens"
- Submit the compound structure to STITCH database with a confidence score threshold of 0.7
- Record all predicted targets with their probability scores
- Disease Target Identification:
- Search GeneCards using disease keywords (e.g., "systemic lupus erythematosus," "hepatocellular carcinoma")
- Query DisGeNET for disease-associated targets with a relevance score > 0.1
- Compile unique gene symbols for the disease of interest
- Target Intersection Analysis:
- Identify overlapping targets between this compound-predicted targets and disease-associated targets
- Generate a Venn diagram to visualize the intersection
- Compile final list of potential therapeutic targets for further analysis
Table 2: Database Resources for Target Identification
| Database | Primary Use | Key Parameters | URL |
|---|---|---|---|
| SwissTargetPrediction | Target prediction based on compound similarity | Probability > 0.1 | http://www.swisstargetprediction.ch/ |
| STITCH | Chemical-protein interaction network | Confidence score > 0.7 | http://stitch.embl.de/ |
| GeneCards | Disease-associated gene compilation | Relevance score > 0.1 | https://www.genecards.org/ |
| DisGeNET | Disease-gene associations | Score > 0.1 | https://www.disgenet.org/ |
| TCMSP | Traditional Chinese medicine compounds | OB ≥ 30%, DL ≥ 0.18 | http://tcmspw.com/tcmsp.php |
Expected Output: A list of high-confidence targets for this compound relevant to the specific disease pathology. In the case of SLE research, this approach identified 12 active compounds and 1190 potential targets for Nelumbo nucifera (which contains this compound), which were subsequently refined to key targets through intersection with SLE-related targets [1]. Similarly, in hepatocellular carcinoma research, this method revealed 98 common overlapping genes between Bergenia species (containing this compound) and HCC pathogenesis [3] [4].
Network Construction and Analysis Protocol
Objective: To construct and analyze compound-target and protein-protein interaction (PPI) networks to identify key targets and biological modules.
Materials and Software:
- Cytoscape software (version 3.8.0 or higher)
- STRING database (https://string-db.org/)
- CytoHubba plugin for Cytoscape
- NetworkAnalyzer plugin for Cytoscape
Step-by-Step Procedure:
Prepare Network Files:
- Create a node table containing this compound and all identified targets
- Generate an edge table specifying interactions between this compound and targets
- Format files as CSV or TSV for import into Cytoscape
Compound-Target Network Construction:
- Import node and edge tables into Cytoscape
- Apply organic layout for initial network visualization
- Use NetworkAnalyzer to compute topological parameters (degree, betweenness centrality, closeness centrality)
- Identify hub nodes based on degree values
Protein-Protein Interaction (PPI) Network:
- Submit target list to STRING database with confidence score > 0.7
- Download resulting PPI network in TSV format
- Import PPI network into Cytoscape for integration with compound-target network
- Apply force-directed layout algorithm for optimal visualization
Network Analysis and Hub Identification:
- Run CytoHubba plugin to identify top hub targets using Maximal Clique Centrality (MCC)
- Calculate network parameters (density, centralization, heterogeneity)
- Identify functional modules through cluster analysis using MCODE plugin
Expected Output: A comprehensive network visualization with this compound at the center connected to various protein targets, with key hub targets clearly identified. The network should reveal the multi-target nature of this compound and suggest potential mechanistic pathways. In published studies, similar approaches with this compound-containing plants showed network densities of approximately 0.026, centralization of 0.448, and heterogeneity of 2.694 for compound-target networks [3] [4].
Molecular Docking Validation Protocol
Objective: To validate and quantify the binding interactions between this compound and key identified targets through computational docking.
Materials and Software:
- AutoDock Vina or AutoDock 4.2
- PyMOL molecular visualization system
- RDKit library (for file format conversions)
- PDB database (https://www.rcsb.org/)
Step-by-Step Procedure:
Protein Preparation:
- Download crystal structures of key targets from PDB database
- Remove water molecules and heteroatoms using PyMOL
- Add polar hydrogens and compute Gasteiger charges
- Save prepared structures in PDBQT format
Ligand Preparation:
- Obtain 3D structure of this compound from PubChem or generate using RDKit
- Minimize energy using MMFF94 force field
- Convert to PDBQT format using AutoDock Tools
Docking Grid Setup:
- Define grid box centered on the known active site of each target
- Set grid dimensions to 40×40×40 Å with 0.375 Å spacing
- Adjust center coordinates based on crystallographic ligand position
Molecular Docking Execution:
- Run AutoDock Vina with exhaustiveness set to 8
- Generate 10 conformations for each docking run
- Record binding affinity (kcal/mol) for each pose
- Analyze binding modes and interaction patterns
Table 3: Molecular Docking Parameters and Expected Results
| Parameter | Setting | Rationale |
|---|---|---|
| Grid Box Size | 40×40×40 Å | Ensures comprehensive coverage of binding site |
| Grid Point Spacing | 0.375 Å | Balanced between precision and computational cost |
| Exhaustiveness | 8 | Standard value for adequate conformational sampling |
| Number of Poses | 10 | Sufficient for capturing varied binding modes |
| Energy Range | 4 kcal/mol | Allows diversity in pose generation |
| Expected Binding Affinity | < -4.5 kcal/mol | Threshold for significant binding [1] |
Expected Output: Quantitative binding affinities for this compound with key targets, with successful docking indicated by binding energies less than -4.5 kcal/mol. Specific binding poses should reveal hydrogen bonding networks, hydrophobic interactions, and structural complementarity. Previous research has demonstrated that this compound exhibits favorable binding affinities for multiple targets, with particularly stable complexes observed during molecular dynamics simulations [1].
Advanced Computational Methods
Graph Convolutional Networks for Activity Prediction
Objective: To implement advanced deep learning approaches for predicting this compound's pharmacological activities using graph neural networks.
Materials and Software:
- DeepChem library (version 2.6.0 or higher)
- RDKit cheminformatics platform
- TensorFlow or PyTorch backend
- Tox21, ChEMBL, or other relevant bioactivity datasets
Step-by-Step Procedure:
Data Preparation:
- Collect bioactivity data for flavonoid compounds from ChEMBL database
- Curate dataset with standardized pIC50, Ki, or EC50 values
- Apply scaffold splitting to ensure structural diversity in training/test sets
Featurization:
- Convert compound structures to graph representations
- Implement atomic feature vectors using RDKit descriptors
- Create dataset suitable for graph convolutional networks
Model Training:
- Configure GCN with appropriate hyperparameters
- Train model using Adam optimizer with learning rate 0.001
- Monitor training and validation loss for convergence
- Apply early stopping to prevent overfitting
Prediction and Validation:
- Apply trained model to predict this compound activities
- Compare predictions with experimental data when available
- Interpret results in context of network pharmacology findings
This advanced approach leverages graph convolutional networks (GCNs) that have demonstrated exceptional performance in quantitative activity prediction across diverse protein targets [6]. These models automatically learn relevant molecular features from compound structures, potentially revealing novel structure-activity relationships for this compound that might not be apparent through traditional methods.
Conclusion and Future Perspectives
Network pharmacology provides a powerful framework for elucidating the complex mechanisms underlying this compound's pharmacological effects. The integrated approach combining target prediction, network analysis, and computational validation offers a comprehensive strategy for understanding natural product polypharmacology. The protocols outlined in this document provide researchers with detailed methodologies for investigating this compound's therapeutic potential, with particular relevance to complex diseases such as autoimmune disorders and cancer.
Future research directions should include:
- Experimental validation of predicted targets through in vitro binding assays
- Systems biology integration of transcriptomics and proteomics data
- Gut microbiota interactions given the potential modulation of microbial communities [5]
- Synergistic combination studies with other therapeutic agents
- Clinical correlation analyses connecting target profiles with patient stratification
The continued application and refinement of these network pharmacology approaches will accelerate the development of this compound and related natural products as potential therapeutic agents, while also enhancing our understanding of their complex mechanisms of action in various disease contexts.
References
- 1. Therapeutic potential of Nelumbo nucifera Linn. in systemic ... [pubmed.ncbi.nlm.nih.gov]
- 2. Exploring active ingredients and function mechanisms of ... [pmc.ncbi.nlm.nih.gov]
- 3. Underlying Mechanisms of Bergenia spp. to Treat ... [mdpi.com]
- 4. Underlying Mechanisms of Bergenia spp. to Treat ... [pmc.ncbi.nlm.nih.gov]
- 5. The identification of metabolites from gut microbiota in ... [nature.com]
- 6. Prediction of pharmacological activities from chemical ... [nature.com]
Comprehensive Application Notes and Protocols: Leucocianidol Protein-Protein Interaction Network Analysis for Drug Discovery
Introduction to PPI Networks and Their Role in Drug Discovery
Fundamental Concepts of Protein-Protein Interactions
Protein-protein interactions (PPIs) represent specific physical contacts between proteins that occur through defined binding regions and serve particular biological functions. These interactions can be categorized as either stable interactions, which form protein complexes like the ribosome or hemoglobin, or transient interactions, which are brief associations that modify or transport proteins to facilitate further changes in cellular processes [1]. The complete set of PPIs occurring within a cell, organism, or specific biological context is referred to as the interactome [1]. PPIs are essential regulators of virtually all cellular processes, including signal transduction, cell cycle regulation, transcriptional control, and metabolic pathways [2]. The fundamental importance of PPIs stems from their ability to modify kinetic properties of enzymes, enable substrate channeling, create new binding sites for small effector molecules, and serve regulatory roles in upstream or downstream cellular processes [3].
The study of PPIs has transformed from focused investigations of individual interactions to network-level analyses that consider the complex web of relationships among proteins. Protein-protein interaction networks (PPIN) are mathematical representations of these physical contacts that provide insights into cellular organization and function [1]. In these networks, proteins are represented as nodes, while interactions between them are depicted as edges connecting these nodes. This network perspective enables researchers to identify functional modules, understand disease mechanisms, and discover potential therapeutic targets through systematic analysis of network properties and relationships [3] [1].
Biological Significance and Therapeutic Implications
Protein-protein interactions play a crucial role in drug discovery and development since many therapeutic compounds ultimately function by modulating these interactions. Drugs can affect PPIs either by inhibiting problematic interactions or stabilizing beneficial ones [1]. The network properties of PPIs provide important insights for therapeutic development; for example, proteins with numerous interaction partners (known as hubs) often represent critical nodes in cellular networks, and their disruption can have significant downstream consequences [4]. However, not all hubs make good drug targets, as some (like chaperone proteins or translation factors) may interact with diverse proteins without sharing functional relationships, making selective inhibition challenging [4].
Network-based drug discovery leverages the understanding that cellular systems operate through interconnected networks rather than isolated components. By mapping how potential drug compounds like leucocianidol alter PPI networks, researchers can identify mechanistic pathways, predict off-target effects, and understand compensatory mechanisms that might emerge when specific interactions are disrupted. This systems-level approach provides a more comprehensive understanding of drug action compared to traditional single-target strategies, potentially leading to more effective therapeutics with fewer adverse effects [2] [3].
Experimental Design and Workflow for this compound PPI Investigation
Overall Framework for PPI Analysis
The systematic investigation of this compound's effects on protein-protein interactions requires an integrated approach combining experimental validation, computational prediction, and network analysis. The comprehensive workflow outlined below ensures that both direct and indirect effects of this compound on the interactome are captured, providing a holistic view of its mechanisms of action. This multi-modal strategy is essential for overcoming the limitations inherent in any single method and for generating high-confidence PPI data for downstream drug development applications [3] [1].
Table 1: Comprehensive Workflow for this compound PPI Analysis
| Phase | Key Activities | Outputs | Technological Platforms |
|---|---|---|---|
| 1. Sample Preparation | This compound treatment optimization; cell lysis; protein extraction | Treated protein samples with appropriate controls | Cell culture systems; protein extraction kits |
| 2. Experimental PPI Detection | Affinity purification; mass spectrometry; Y2H screening | Initial PPI datasets; interaction confidence scores | TAP-MS; Y2H; Co-IP; protein arrays |
| 3. Computational Prediction | Sequence analysis; structure modeling; domain interaction prediction | Predicted interactions; functional annotations | Deep learning models; GNNs; molecular docking |
| 4. Data Integration | Network construction; confidence assessment; data normalization | Integrated PPI network with edge weights | Cytoscape; network analysis tools |
| 5. Network Analysis | Topological analysis; module detection; functional enrichment | Key targets; affected pathways; network metrics | Cluster analysis; pathway enrichment tools |
| 6. Therapeutic Interpretation | Target prioritization; mechanism analysis; efficacy prediction | Drug candidate insights; biomarker candidates | Visualization tools; statistical analysis |
The following workflow diagram illustrates the integrated experimental and computational approach for studying this compound's effects on PPIs:
This compound-Specific Considerations
When designing experiments specifically for this compound, several compound-specific factors must be considered to ensure biologically relevant results. First, dose-response relationships should be carefully characterized, with treatment concentrations spanning from physiological to supraphysiological levels to identify both primary targets and secondary effects. Second, temporal dynamics must be accounted for, as this compound's effects may evolve over time through direct binding and subsequent downstream consequences. Finally, cell-type specificity should be investigated, as this compound may exhibit different PPI modulation patterns across various tissue types or disease states [3].
The integration of experimental and computational approaches is particularly important for natural compounds like this compound, which may have multiple protein targets and complex effects on cellular networks. Computational predictions can guide experimental design by prioritizing likely interactions, while experimental results can refine computational models in an iterative feedback loop. This integrated approach maximizes the efficiency of resource allocation and increases the reliability of the resulting PPI network [2] [5].
Experimental Protocols for PPI Detection
Affinity Purification Mass Spectrometry (AP-MS)
Principle: AP-MS combines affinity-based purification of protein complexes with mass spectrometric identification of interacting partners. When applied to this compound studies, this protocol can reveal both direct binding partners and indirect complex associations affected by the compound [3].
Protocol Steps:
Cell Lysis and Preparation:
- Culture cells with and without this compound treatment (recommended concentrations: 1µM, 10µM, 100µM) for 4-24 hours
- Lyse cells using non-denaturing lysis buffer (e.g., 50mM Tris-HCl, 150mM NaCl, 1% NP-40, protease inhibitors)
- Clarify lysates by centrifugation at 16,000 × g for 15 minutes at 4°C
Affinity Purification:
- Incubate lysates with anti-target antibody conjugated to magnetic beads
- Include isotype control antibodies for background subtraction
- Wash beads 3-5 times with lysis buffer to remove non-specific interactions
Elution and Protein Preparation:
- Elute bound proteins using low-pH glycine solution (0.1M, pH 2.5-3.0) or direct digestion on beads
- Reduce proteins with 5mM DTT (30 minutes, 60°C)
- Alkylate with 15mM iodoacetamide (30 minutes, room temperature, in darkness)
Mass Spectrometry Analysis:
- Digest proteins with sequencing-grade trypsin (overnight, 37°C)
- Desalt peptides using C18 stage tips
- Analyze by LC-MS/MS with 2-hour gradient
- Acquire data in data-dependent acquisition mode
Data Processing:
- Identify proteins using database search tools (MaxQuant, Proteome Discoverer)
- Apply statistical filtering (SAINT, FC-BP) to distinguish specific interactions from background
- Compare this compound-treated vs. control samples to identify significant changes [3]
Technical Considerations: The tandem affinity purification (TAP) method enhances specificity by incorporating two sequential purification steps, reducing false-positive interactions. This method is particularly valuable for this compound studies where distinguishing direct from indirect interactions is challenging. When working with this compound, include vehicle controls (DMSO or ethanol) and consider time-course experiments to capture dynamic interactions [3].
Yeast Two-Hybrid (Y2H) Screening
Principle: Y2H detects binary protein interactions through reconstitution of transcription factor activity. This method is ideal for identifying direct interactions between this compound-targeted proteins and their partners [3].
Protocol Steps:
Bait and Prey Construction:
- Clone potential this compound target proteins into DNA-binding domain vector (pGBKT7)
- Clone cDNA library into activation domain vector (pGADT7)
- Verify constructs by sequencing and autoactivation testing
Yeast Transformation and Selection:
- Co-transform bait and prey plasmids into appropriate yeast strain (Y2HGold)
- Plate on selective medium lacking tryptophan and leucine (SD/-Leu/-Trp)
- Incubate at 30°C for 3-5 days until colonies form
Interaction Screening:
- Transfer colonies to high-stringency selection medium (SD/-Ade/-His/-Leu/-Trp)
- Include X-α-Gal for blue-white selection of positive interactions
- Incubate at 30°C for 3-7 days, monitoring colony growth and color development
Confirmation and Validation:
- Isolate plasmid DNA from positive colonies
- Perform yeast re-transformation to confirm interactions
- Sequence prey plasmids to identify interacting partners
This compound Treatment Integration:
- Incorporate this compound into selection media at subtoxic concentrations
- Compare interaction patterns with and without this compound
- Focus on interactions that are enhanced or diminished by this compound treatment [3]
Technical Considerations: Y2H is known for high false-positive rates, so orthogonal validation is essential. For this compound studies, consider quantitative Y2H approaches that provide interaction strength measurements. Be aware that Y2H may miss interactions requiring post-translational modifications that don't occur in yeast or interactions dependent on This compound-induced conformational changes [3].
Table 2: Comparison of Major Experimental PPI Detection Methods
| Method | Principle | Advantages | Limitations | Suitability for this compound |
|---|---|---|---|---|
| Affinity Purification MS | Purification of protein complexes followed by MS identification | Identifies native complexes; detects indirect interactions; medium-to-high throughput | Does not distinguish direct from indirect interactions; requires specific antibodies | High - can detect this compound-induced changes in complex formation |
| Yeast Two-Hybrid | Reconstitution of transcription factor from interacting proteins | Detects direct binary interactions; genome-wide screening possible | High false-positive rate; limited to nuclear interactions; no PTMs in yeast | Medium - useful for initial screening but requires confirmation |
| Co-Immunoprecipitation | Antibody-mediated precipitation of protein complexes | Confirms interactions in native state; works with endogenous proteins | Low throughput; requires specific antibodies; semi-quantitative | High - excellent for validation of this compound effects on specific interactions |
| Protein Microarrays | High-throughput binding assays on protein chips | Ultra-high throughput; quantitative binding data | Limited to predefined proteins; may lack native conformation | Medium - useful for screening direct binding to known targets |
Computational Prediction and Network Analysis Protocols
Deep Learning Approaches for PPI Prediction
Principle: Deep learning models automatically extract relevant features from protein sequences and structures to predict interactions, leveraging patterns learned from large-scale PPI datasets [2] [5].
Protocol Steps:
Data Preparation and Feature Extraction:
- Retrieve protein sequences for potential this compound targets from UniProt
- Generate multiple sequence alignments for evolutionary information
- Extract structural features if structures available (PDB)
- Calculate physicochemical properties (hydrophobicity, charge, etc.)
Model Selection and Training:
- Implement Graph Neural Networks (GNNs) for network-based prediction
- Utilize Transformer architectures with multi-head self-attention to capture long-distance dependencies in sequences [5]
- Consider multi-modal models that integrate sequence, structure, and evolutionary information
- Train on reference PPI datasets (BioGRID, STRING) with cross-validation
This compound-Specific Adaptation:
- Fine-tune models on compound-specific interaction data
- Incorporate known this compound targets as positive examples
- Apply transfer learning from general PPI prediction to this compound-focused prediction
Prediction and Validation:
Implementation Details: The LDMGNN model represents a state-of-the-art approach that combines long-distance dependency information from protein sequences with multi-hop graph neural networks. This model uses transformer blocks with multi-head self-attention to capture relationships between all amino acid pairs in sequences, then integrates this information with PPI network topology. The model constructs a two-hop PPI network to capture both direct and indirect interactions, addressing limitations of methods that consider only immediate neighbors [5].
Network Construction and Topological Analysis
Principle: PPI networks are constructed as mathematical graphs where proteins are nodes and interactions are edges, enabling quantitative analysis of network properties to identify biologically significant proteins and modules [4] [6].
Protocol Steps:
Network Construction:
- Compile interaction data from experimental results and computational predictions
- Assign confidence scores to each interaction based on supporting evidence
- Construct weighted graph using network analysis tools (Cytoscape, NetworkX)
Topological Analysis:
- Calculate basic network metrics (density, diameter, clustering coefficient)
- Compute node-specific metrics (degree, betweenness, closeness centrality)
- Identify network communities using modularity optimization algorithms
- Detect potential key targets based on topological importance
Diffusion State Distance (DSD) Analysis:
Functional Enrichment Analysis:
- Perform overrepresentation analysis for GO terms, KEGG pathways
- Identify significantly enriched biological processes and pathways
- Relocate network modules to specific cellular functions and processes
The following diagram illustrates the computational workflow for network analysis and its application to this compound research:
Advanced Network Analysis Techniques
Diffusion State Distance (DSD) represents a significant advancement over traditional shortest-path metrics for assessing functional relationships in PPI networks. Unlike conventional approaches that suffer from the "ties in proximity" problem in small-world biological networks, DSD captures finer-grained distinctions by considering the entire network topology through random walk simulations [4] [6]. The protocol for DSD analysis includes:
Matrix Preparation:
- Construct adjacency matrix A from the PPI network
- Compute degree matrix D (diagonal matrix of node degrees)
- Calculate transition matrix P = D⁻¹A
DSD Computation:
- Compute the fundamental matrix (I - P + C)⁻¹ where C is the constant matrix with each row as πᵀ (stationary distribution)
- Calculate DSD(u,v) = ||(bᵤᵀ - bᵥᵀ)(I - P + C)⁻¹||₁ where bᵤ is the basis vector for node u
- Generate DSD matrix for all node pairs
Application to this compound Analysis:
Enhanced DSD variants including cDSD (confidence-weighted), caDSD (confidence-augmented), and capDSD (confidence-augmented pathway) further improve performance by incorporating additional biological information such as interaction confidence, directionality, and known pathway information [6].
Data Integration and Analytical Framework
Multi-Modal Data Integration Strategy
Principle: Integrating diverse data sources enhances the reliability and biological relevance of PPI networks by combining evidence from multiple experimental and computational approaches [2] [1].
Protocol Steps:
Evidence Weighting and Scoring:
- Assign confidence scores to each interaction based on source reliability
- Experimental interactions: score based on method reliability and reproducibility
- Computational predictions: score based on model confidence and evolutionary conservation
- Database annotations: score based on consensus across multiple sources
Data Normalization and Integration:
- Normalize scores across different data types using percentile ranking
- Implement weighted integration algorithms to combine evidence
- Apply consensus approaches to resolve conflicts between data sources
Network Refinement:
- Filter interactions below confidence threshold (recommended: ≥0.7 composite score)
- Validate key interactions through orthogonal methods
- Annotate interactions with supporting evidence and functional implications
Table 3: Confidence Scoring System for Integrated PPI Data
| Evidence Type | Subcategory | Score Range | Weight | Criteria |
|---|---|---|---|---|
| Experimental | AP-MS | 0-1 | 0.3 | Number of replicates; spectral counts; statistical significance |
| Y2H | 0-1 | 0.2 | Binary confirmation; retest reliability; absence of autoactivation | |
| Co-IP | 0-1 | 0.25 | Antibody specificity; Western validation; interaction strength | |
| Computational | Deep Learning | 0-1 | 0.15 | Model confidence; evolutionary conservation; functional coherence |
| Structure-Based | 0-1 | 0.1 | Binding affinity; interface complementarity; evolutionary conservation | |
| Database | Curated Databases | 0-1 | 0.15 | Number of supporting publications; consensus across databases |
Visualization and Interpretation Protocols
Principle: Effective visualization of PPI networks facilitates biological interpretation and hypothesis generation by representing complex interaction data in an intuitive format [7] [8].
Protocol Steps:
Network Layout Optimization:
- Use force-directed algorithms (Fruchterman-Reingold) for general layouts
- Apply hierarchical layouts for signaling pathways
- Implement circular layouts for modular networks
Visual Encoding Strategy:
- Size nodes according to topological importance (degree, centrality)
- Color nodes by functional classification or expression changes
- Weight edges by confidence scores or interaction strength
- Use edge arrows to indicate interaction directionality when known
Subnetwork Extraction:
- Extract modules significantly affected by this compound treatment
- Identify densely connected regions around potential targets
- Focus on disease-relevant pathways for detailed visualization
Functional Annotation:
- Integrate Gene Ontology, KEGG, and Reactome annotations
- Highlight enriched functions within network modules
- Cross-reference with disease association databases
Cytoscape Implementation: The Cytoscape platform provides comprehensive tools for PPI network visualization and analysis. For this compound studies, recommended apps include clusterMaker2 for module detection, stringApp for database integration, and cytoHubba for hub identification. Automated layout adjustments should be complemented with manual curation to ensure biological interpretability [7].
Therapeutic Applications and Concluding Perspectives
The systematic analysis of this compound's effects on protein-protein interaction networks provides a powerful approach for understanding its mechanisms of action and identifying potential therapeutic applications. By integrating experimental validation with computational prediction, researchers can construct high-confidence networks that reveal how this compound modulates cellular processes through targeted interactions. The network perspective enables the identification of key target proteins, affected functional modules, and compensatory mechanisms that might influence treatment efficacy.
The methodological frameworks presented in these application notes emphasize reproducibility, accuracy, and biological relevance. The protocols for experimental detection, computational prediction, and integrated analysis provide comprehensive guidance for researchers investigating this compound's protein interactions. As PPI network technologies continue to advance, particularly through developments in deep learning and high-throughput screening, the resolution and completeness of this compound's interactome mapping will continue to improve, offering new insights into its therapeutic potential and applications in drug discovery.
References
- 1. - Protein networks | Network protein of protein... interaction analysis [ebi.ac.uk]
- 2. Recent advances in deep learning for protein - protein ... interaction [biodatamining.biomedcentral.com]
- 3. - Protein Detection: Protein and Interaction - PMC Methods Analysis [pmc.ncbi.nlm.nih.gov]
- 4. Going the Distance for Protein Function Prediction: A New ... [pmc.ncbi.nlm.nih.gov]
- 5. Long-distance dependency combined multi-hop graph neural ... [bmcbioinformatics.biomedcentral.com]
- 6. New directions for diffusion-based network prediction of ... [pmc.ncbi.nlm.nih.gov]
- 7. - Protein Protein Interactions [cytoscape.org]
- 8. Graphviz and mermaid in DiagrammeR [rich-iannone.github.io]
Comprehensive Application Notes and Protocols: Leucocianidol Molecular Docking Studies for Drug Development
Introduction to Leucocianidol and Its Therapeutic Potential
This compound (also known as Leucocyanidol) is a naturally occurring flavonoid compound that has gained significant attention in pharmaceutical research due to its promising biological activities and favorable drug-like properties. This compound belongs to the chemical class of flavan-3-ols and demonstrates notable antioxidant capabilities and potential anticancer properties. This compound has been identified in various plant species, particularly in the Bergenia genus, which has been used in traditional medicine for centuries to treat various conditions including piles, kidney stones, bladder, and pulmonary infections [1]. The compound's structural characteristics enable it to interact with multiple biological targets, making it an excellent candidate for systematic molecular docking studies to elucidate its mechanism of action at the molecular level.
The molecular formula of this compound is C15H14O7, with a molecular weight of 306.29 g/mol [1]. It possesses several hydrogen bond donors and acceptors, which contribute to its ability to form stable interactions with protein targets. According to pharmacological screening, this compound demonstrates an oral bioavailability (OB) of 30.84% and a drug likeness (DL) value of 0.27, both of which meet the criteria for further drug development consideration (OB > 30% and DL > 0.18) [1]. These properties make this compound a promising candidate for therapeutic development, particularly for complex diseases requiring multi-target approaches, such as cancer, inflammatory conditions, and metabolic disorders.
Compound Profiling and Drug-Likeness Assessment
Molecular Characteristics and Physicochemical Properties
Comprehensive characterization of this compound begins with establishing its fundamental molecular properties and assessing its drug-likeness according to established pharmacological guidelines. The physicochemical profile of any compound significantly influences its absorption, distribution, metabolism, and excretion (ADME) characteristics, which ultimately determine its suitability as a drug candidate. For this compound, these properties have been systematically evaluated and quantified to provide researchers with essential data for experimental planning and interpretation of docking results.
Table 1: Molecular Properties and Drug-Likeness Parameters of this compound
| Property | Value | Description | Significance |
|---|---|---|---|
| Molecular Formula | C15H14O7 | Chemical composition | Determines atomic arrangement and bonding |
| Molecular Weight | 306.29 g/mol | Mass of one molecule | Impacts bioavailability and membrane permeability |
| Oral Bioavailability (OB) | 30.84% | Percentage of orally administered dose reaching systemic circulation | Meets minimum threshold of 30% for drug candidates |
| Drug Likeness (DL) | 0.27 | Quantitative measure of similarity to known drugs | Exceeds minimum threshold of 0.18 |
| PubChem CID | 440833 | Unique identifier in PubChem database | Enables access to additional chemical information |
| Hydrogen Bond Donors | 5 | Number of OH groups | Influences protein binding capabilities |
| Hydrogen Bond Acceptors | 7 | Number of oxygen atoms | Affects solubility and interaction with targets |
The drug-likeness parameters summarized in Table 1 provide crucial insights for positioning this compound within the drug development pipeline. The compound's moderate molecular weight (306.29 g/mol) suggests favorable membrane permeability, while its balanced hydrophobicity-hydrophilicity ratio enables reasonable solubility while still allowing for passive diffusion across biological membranes. The presence of multiple hydrogen bond donors and acceptors (5 and 7, respectively) indicates strong potential for forming specific interactions with protein targets, which is a key factor in molecular docking studies. These characteristics collectively contribute to this compound's promising profile as a lead compound worthy of further investigation through systematic molecular docking analyses.
Target Identification and Protein Selection Strategy
Integrated Bioinformatics Approach for Target Prediction
The identification of potential protein targets for this compound employs a comprehensive bioinformatics strategy that integrates data from multiple validated databases. This systematic approach begins with retrieving potential gene targets from the SwissTargetPrediction and STITCH databases, which utilize chemical similarity and established compound-target relationships to predict interactions [1]. Through this process, researchers can identify a broad spectrum of potential targets that are then refined based on disease relevance. In a notable study investigating Bergenia species (which contain this compound), this approach identified 313 initial targets across four phytochemicals, which were consolidated to 228 unique drug-related gene targets after removing duplicates by aligning UniprotKB protein IDs [1].
The target refinement process continues by intersecting these drug-related targets with disease-specific genes. For example, in hepatocellular carcinoma (HCC) research, 3176 HCC-related gene targets were retrieved from GeneCard and DisGeNet databases, resulting in 2742 unique targets after duplicate removal [1]. The integration of Bergenia-related targets and HCC-related targets revealed 98 overlapping genes considered most relevant to the disease pathogenesis. This cross-referencing approach ensures that the selected targets have both chemical interaction potential and biological relevance to the disease context, maximizing the likelihood of identifying therapeutically meaningful interactions.
Diagram 1: Target Identification Workflow for this compound. This diagram illustrates the systematic approach for identifying potential protein targets, integrating compound and disease database information to select the most relevant targets for docking studies.
Protein Selection and Preparation Protocol
The selection of specific protein structures for docking with this compound requires careful consideration of several factors to ensure biologically relevant results. Researchers should prioritize high-resolution crystal structures (preferably <2.5 Å) from the Protein Data Bank (PDB) that contain relevant co-crystals or have well-characterized active sites. For targets identified through the bioinformatics workflow, the topological analysis of protein-protein interaction (PPI) networks can reveal hub genes with maximum degree rank, which often represent the most critical targets. In studies with Bergenia compounds, this approach identified key targets including STAT3, MAPK3, and SRC due to their central roles in biological processes and pathway annotations [1].
The protein preparation protocol involves multiple critical steps to ensure the protein structure is optimized for docking simulations. First, the selected PDB file is loaded into molecular visualization software such as PyMOL where water molecules and heteroatoms are removed from the protein crystal structure [2]. Subsequently, hydrogen atoms are added, and charges are calculated to create a more physiologically relevant system. The protein structure then undergoes energy minimization using appropriate force fields (such as CHARMM or AMBER) to relieve atomic clashes and optimize geometry. This preparation results in a cleaned protein structure that can be saved in PDBQT format using AutoDockTools, making it ready for docking simulations with this compound [2].
Molecular Docking Methodology
Docking Protocol and Parameter Configuration
Molecular docking simulations between this compound and selected protein targets follow a standardized protocol to ensure reproducible and reliable results. The process begins with preparation of this compound's 3D structure, which is typically downloaded from the PubChem database in SDF format and converted to mol2 format using OpenBabel software [2]. The structure then undergoes energy minimization using computational chemistry software such as Gaussian 09 with the B3LYP/6-31G basis set to optimize geometry and calculate electrostatic potential [2]. The resulting structure is converted to PDBQT format using AutoDockTools, which assigns atomic charges and defines rotatable bonds to properly model ligand flexibility during docking simulations.
The actual docking procedure is performed using AutoDock Vina (version 1.1.2 or higher), which employs an efficient gradient optimization algorithm for conformational searching [2]. The docking grid must be carefully defined to encompass the entire binding site of interest, with grid dimensions typically set to 40×40×40 points with a grid spacing of 0.375 Å to ensure comprehensive coverage. The exhaustiveness parameter should be set to at least 8 to guarantee sufficient sampling of the conformational space. For each ligand-protein pair, multiple docking runs should be performed (typically 10-20 independent runs) to ensure consistency of results. The resulting poses are then ranked according to their binding affinity scores (expressed in kcal/mol), with lower (more negative) values indicating stronger binding.
Table 2: Molecular Docking Methodology and Analysis Criteria for this compound
| Parameter | Specification | Rationale |
|---|---|---|
| Docking Software | AutoDock Vina 1.1.2 | Efficient conformational search and scoring |
| Grid Dimensions | 40×40×40 points | Comprehensive binding site coverage |
| Grid Spacing | 0.375 Å | Balance between precision and computational cost |
| Exhaustiveness | 8-16 | Sufficient conformational sampling |
| Number of Runs | 10-20 per target | Statistical reliability of results |
| Pose Ranking | Binding affinity (kcal/mol) | Lower (more negative) values indicate stronger binding |
| Validation Method | Re-docking of native ligand | RMSD calculation <2.0 Å indicates acceptable accuracy |
| Interaction Analysis | Hydrogen bonds, hydrophobic contacts, π-π stacking | Identifies specific binding mechanisms |
Analysis of Docking Results and Interaction Mapping
Critical analysis of docking results involves both quantitative assessment of binding energies and qualitative evaluation of interaction patterns. The binding affinity score provides an initial quantitative measure of interaction strength, with values ≤ -6.0 kcal/mol generally indicating promising binding potential. However, energy scores alone are insufficient; researchers must also examine the specific molecular interactions that stabilize the this compound-protein complex. Key interactions to analyze include hydrogen bonds (particularly with key catalytic residues), hydrophobic contacts, π-π stacking with aromatic residues, and electrostatic interactions [3]. These specific interactions not only validate the binding mode but also provide insights for future structure-based optimization of this compound.
The validation of docking protocols is essential to ensure the reliability of predicted binding modes. A standard validation approach involves re-docking a known crystallographic ligand into its original binding site and calculating the root-mean-square deviation (RMSD) between the predicted and experimentally observed poses. An RMSD value <2.0 Å generally indicates acceptable docking accuracy [2]. Additionally, researchers should perform visual inspection of the top-ranking poses using molecular visualization software such as PyMOL or Discovery Studio to assess the plausibility of binding orientations and interactions. This combined quantitative and qualitative analysis approach ensures that the docking results for this compound provide meaningful insights into its potential mechanisms of biological action.
Binding Affinity Validation and Drug Design Implications
Experimental Validation and Correlation with Docking Predictions
Experimental validation of computational docking predictions represents a critical step in establishing the biological relevance of this compound's interactions with target proteins. While molecular docking provides valuable insights into potential binding modes and affinities, these predictions must be corroborated through in vitro experimental assays to confirm pharmacological activity. For this compound and related compounds, this typically involves cell viability assays (such as MTT or WST-1 assays) in relevant cell lines to determine half-maximal inhibitory concentration (IC50) values. In studies with similar Bergenia compounds, researchers observed a significant reduction in cell viability in HepG2 cells after 24 hours of treatment in a dose-dependent manner, confirming the anti-proliferative effects predicted by computational approaches [1].
The correlation between computational predictions and experimental results extends beyond simple binding affinity measurements. Researchers should also consider the biological context of target proteins within signaling pathways to develop a comprehensive understanding of this compound's potential mechanisms of action. For example, network pharmacology analyses have revealed that related compounds primarily target proteins involved in HCC pathogenesis, with a particular enrichment in pathways such as HIF-1 signaling, chemical carcinogenesis-receptor activation, and PI3K-Akt signaling [1]. This integrative approach helps contextualize docking results within broader physiological frameworks, providing stronger evidence for therapeutic potential and suggesting possible combination therapies or multi-target strategies.
Diagram 2: this compound Multi-Target Signaling Pathway. This diagram illustrates the potential signaling pathways affected by this compound binding to key protein targets, leading to multiple therapeutic effects.
Implications for Drug Design and Development
The structural insights gained from molecular docking studies of this compound provide valuable guidance for rational drug design and optimization. Analysis of the specific residues involved in this compound binding (such as those identified in STAT3, MAPK3, and SRC complexes) reveals key interaction patterns that contribute to binding affinity and selectivity. For instance, if this compound forms hydrogen bonds with catalytic residues or π-π stacking interactions with aromatic residues in the binding pocket, these features can be preserved or enhanced in derivative compounds [1]. Additionally, identification of suboptimal interactions or steric clashes can guide structural modifications to improve binding characteristics while maintaining favorable drug-like properties.
The multi-target potential of this compound, as suggested by network pharmacology and docking studies, positions it as a promising candidate for polypharmacological approaches to complex diseases. Unlike highly selective single-target agents, multi-target compounds may offer enhanced therapeutic efficacy and reduced potential for resistance development, particularly in multifactorial diseases like cancer and metabolic disorders [2]. However, this approach also necessitates careful assessment of potential off-target effects and toxicity profiles. Computational toxicity prediction tools such as TOPKAT can help identify potential safety concerns early in the development process, allowing researchers to prioritize the most promising candidates for further experimental evaluation [4].
Detailed Experimental Protocols
Step-by-Step Molecular Docking Protocol
Protocol 1: this compound Molecular Docking Using AutoDock Vina
This protocol provides detailed instructions for performing molecular docking studies with this compound against selected protein targets, with an estimated completion time of 4-6 hours per target.
Materials and Software Requirements:
- This compound 3D structure (CID: 440833 from PubChem)
- Protein Data Bank files for target proteins
- AutoDock Vina (version 1.1.2 or higher)
- AutoDockTools (version 1.5.7 or higher)
- PyMOL (version 2.4.0 or higher)
- OpenBabel (version 3.1.1 or higher)
Procedure:
This compound Preparation:
- Download the 3D structure of this compound from PubChem in SDF format
- Convert the SDF file to mol2 format using OpenBabel:
babel -i sdf this compound.sdf -o mol2 this compound.mol2 - Open AutoDockTools and load the mol2 file
- Add hydrogens and compute Gasteiger charges
- Define rotatable bonds (allow flexibility for all single bonds except amide bonds)
- Save the prepared ligand in PDBQT format
Protein Preparation:
- Obtain the crystal structure of the target protein from PDB (prioritize structures with resolution <2.5 Å)
- Remove water molecules, cofactors, and native ligands using PyMOL
- Add polar hydrogens and compute partial charges using AutoDockTools
- Save the prepared protein in PDBQT format
Docking Grid Configuration:
- Identify the binding site coordinates based on known ligand positions or literature
- Set the grid box dimensions to 40×40×40 points with 0.375 Å spacing
- Ensure the grid center encompasses the entire binding site with adequate margin
- Save the configuration file with appropriate parameters (exhaustiveness = 8)
Docking Execution:
- Run AutoDock Vina using the command:
vina --config config.txt --log log.txt - Perform 10 independent docking runs to ensure conformational diversity
- Extract the top-ranking poses based on binding affinity (kcal/mol)
- Run AutoDock Vina using the command:
Results Analysis:
- Calculate RMSD values between poses to identify clustering patterns
- Visualize the top pose using PyMOL to assess binding orientation
- Identify specific interactions (hydrogen bonds, hydrophobic contacts, etc.)
- Generate high-quality figures for publication documenting key interactions
Troubleshooting Tips:
- If binding poses appear inconsistent across runs, increase exhaustiveness to 16-24
- If ligand fails to dock in the binding site, verify grid center coordinates
- For poor binding scores, consider protonation state adjustments at physiological pH
Molecular Dynamics Simulation Protocol
Protocol 2: Molecular Dynamics Validation of this compound Binding
This protocol describes the procedure for validating docking results through molecular dynamics simulations, providing assessment of binding stability over time. Estimated completion time: 24-48 hours depending on system size.
Materials and Software Requirements:
- AMBER14 or GROMACS software package
- Topology files for protein and this compound
- Previously obtained docking poses
- High-performance computing resources
Procedure:
System Preparation:
- Generate force field parameters for the protein using ff14SB
- Create parameters for this compound using the general AMBER force field (gaff)
- Calculate electrostatic potential fits using Gaussian 09 at the B3LYP/6-31G level
- Obtain partial charges for this compound using the RESP method in the Antechamber module
Simulation Setup:
- Solvate the protein-ligand complex in a TIP3P water box with 10 Å padding
- Add counterions to neutralize system charge
- Perform energy minimization using 2500 steps of steepest descent followed by 2500 steps of conjugate gradient method
Equilibration Phase:
- Gradually heat the system from 0 to 300 K over 50 ps with positional restraints on heavy atoms
- Conduct 100 ps of equilibration at constant temperature (300 K) and pressure (1 atm)
- Remove positional restraints and equilibrate for an additional 50 ps
Production Simulation:
- Run unrestrained molecular dynamics simulation for 50-100 ns
- Save trajectory coordinates every 10 ps for analysis
- Monitor system stability through RMSD, RMSF, and interaction analysis
Trajectory Analysis:
- Calculate RMSD of protein backbone and ligand heavy atoms to assess stability
- Identify persistent hydrogen bonds and hydrophobic interactions
- Compute binding free energy using MM/PBSA or MM/GBSA methods
- Compare simulation results with original docking predictions
Conclusion and Future Perspectives
The comprehensive molecular docking methodology outlined in these application notes provides researchers with a robust framework for investigating this compound's interactions with potential protein targets. The integrated approach combining network pharmacology, molecular docking, and experimental validation offers a systematic strategy for elucidating mechanisms of action and identifying the most promising therapeutic applications for this natural compound. The protocols and methodologies detailed herein have been refined through applications in similar research contexts, particularly in studies of Bergenia species compounds for hepatocellular carcinoma, where they demonstrated utility in identifying and validating protein targets [1].
Future research directions for this compound should include expanded target screening across multiple disease-relevant protein families, structural optimization based on binding interaction analysis, and comprehensive ADMET profiling to fully characterize its drug development potential. Additionally, the integration of advanced computational methods such as machine learning-based binding affinity prediction and quantum mechanical calculations could further enhance our understanding of this compound's molecular interactions. As natural products continue to provide valuable lead compounds for drug development, the systematic approaches described in these application notes will remain essential tools for translating traditional medicinal knowledge into modern therapeutic agents with well-characterized mechanisms of action.
References
- 1. Underlying Mechanisms of Bergenia spp. to Treat ... [pmc.ncbi.nlm.nih.gov]
- 2. The Mechanism by Which Cyperus rotundus Ameliorates ... [pmc.ncbi.nlm.nih.gov]
- 3. Distance plus attention for binding affinity prediction - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Ligand-based Pharmacophore Modeling, Virtual Screening ... [pmc.ncbi.nlm.nih.gov]
Comprehensive Application Notes and Protocols: GO and KEGG Pathway Enrichment Analysis for Leucocianidol
Introduction and Biological Significance of Leucocianidol
This compound (also known as leucocyanidol or leucocyanidin) is a proanthocyanidin flavonoid with demonstrated biological activities that make it a promising candidate for therapeutic development. This natural compound has gained significant research interest due to its potent antioxidant properties and multi-target mechanisms of action against various pathological conditions. With a molecular formula of C₁₅H₁₄O₇ and molecular weight of 306.27 g/mol, this compound exhibits favorable drug-like properties, including an oral bioavailability of 30.84% and drug likeness score of 0.27, making it suitable for further pharmaceutical investigation [1].
The compound has been identified in several medicinal plants, including various Bergenia species and Nelumbo nucifera (sacred lotus), where it contributes to their traditional therapeutic effects [1] [2]. Modern pharmacological studies have revealed that this compound and related procyanidolic oligomers exhibit significant antimutagenic activity and protective effects against cardiovascular disease [3]. Importantly, research has demonstrated that these compounds can modulate key metabolic enzymes, notably inhibiting specific cytochrome P450 isoforms (including P4501A1, P4501A2, and P4503A4) while simultaneously enhancing phase II conjugation enzymes such as glutathione S-transferase and phenolsulfotransferase [3]. This dual action suggests a role for this compound as a potential chemopreventive agent against toxic or carcinogenic metabolites.
The application of network pharmacology and pathway enrichment analysis has become increasingly valuable in natural product research like this compound studies, as these approaches can elucidate complex multi-target mechanisms that underlie the therapeutic effects of phytochemicals [1] [4]. These methods help researchers transition from traditional single-target drug discovery to a more comprehensive understanding of polypharmacological interactions, which is particularly relevant for natural compounds that typically exert their effects through simultaneous modulation of multiple biological pathways [1].
Target Identification and Pathway Enrichment Analysis
Target Prediction and Identification
The initial step in understanding this compound's mechanisms involves comprehensive target prediction, which forms the foundation for subsequent pathway analyses. Based on network pharmacology studies of similar flavonoids, researchers can identify potential protein targets through several specialized databases:
- SwissTargetPrediction: Predicts protein targets based on compound structural similarity [1] [5]
- STITCH Database: Provides information on chemical-protein interactions [1]
- Similarity Ensemble Approach (SEA): Identifies targets by comparing chiral chemical similarity [5]
In a representative study on related flavonoids, researchers identified 313 potential gene targets for four Bergenia compounds including this compound, which were refined to 228 unique drug-related gene targets after removing duplicates by aligning UniprotKB protein IDs [1]. For disease-specific investigations, researchers typically retrieve disease-associated targets from GeneCards, DisGeNET, and OMIM databases, followed by intersection with compound targets to identify overlapping targets [1] [4]. In a hepatocellular carcinoma (HCC) study, this approach revealed 98 common targets between Bergenia compounds (including this compound) and HCC pathogenesis [1].
GO and KEGG Enrichment Analysis Methodology
Gene Ontology (GO) and Kyoto Encyclopedia of Genes and Genomes (KEGG) pathway enrichment analyses are fundamental bioinformatics methods that provide systematic understanding of gene functions and associated pathways. The GO framework comprises three orthogonal categories:
- Biological Process (BP): Organized pathways of molecular activities
- Molecular Function (MF): Elemental activities at molecular level
- Cellular Component (CC): Locations where genes function
For this compound research, GO enrichment analysis can determine whether certain biological processes, molecular functions, or cellular components are statistically over-represented in its target gene list. The statistical significance of enrichment is typically determined using the hypergeometric test, with subsequent false discovery rate (FDR) correction for multiple testing [6]. The fold enrichment is calculated as the percentage of genes in the list belonging to a specific GO term divided by the corresponding percentage in the background genes, providing a measure of effect size [6].
KEGG pathway enrichment analysis helps researchers identify signaling and metabolic pathways significantly modulated by this compound. This analysis contextualizes the compound's activity within broader biological systems, potentially revealing effects on pathways such as AGE-RAGE signaling, MAPK signaling, HIF-1 signaling, and other disease-relevant pathways [2] [4]. Specialized tools like ShinyGO 0.85 provide user-friendly platforms for performing these analyses, offering graphical outputs and comprehensive statistical support [6].
Table 1: Key Databases for this compound Target and Pathway Analysis
| Database Category | Database Name | Primary Function | URL | Key Features |
|---|---|---|---|---|
| Target Prediction | SwissTargetPrediction | Predicts protein targets | http://www.swisstargetprediction.ch/ | Probability-based predictions |
| STITCH | Chemical-protein interactions | http://stitch.embl.de/ | Includes experimental & predicted interactions | |
| Disease Targets | GeneCards | Human gene database | https://www.genecards.org/ | Comprehensive gene-disease associations |
| DisGeNET | Disease-gene associations | https://www.disgenet.org/ | Includes curated and literature-derived data | |
| Pathway Analysis | ShinyGO | GO & pathway enrichment | https://bioinformatics.sdstate.edu/go/ | User-friendly, graphical outputs |
| KEGG | Pathway mapping | https://www.genome.jp/kegg/ | Reference pathway diagrams | |
| Reactome | Detailed pathway analysis | https://reactome.org/ | Manually curated pathways |
Experimental Protocols and Workflows
Computational Protocol for GO and KEGG Analysis
This protocol provides a step-by-step workflow for conducting comprehensive GO and KEGG pathway enrichment analysis for this compound, integrating information from multiple established methodologies [1] [7].
Step 1: Target Gene List Acquisition
- Obtain this compound's potential protein targets using SwissTargetPrediction and STITCH databases
- Input this compound's SMILES structure (obtained from PubChem CID: 440833) into prediction tools
- Apply "Homo sapiens" as the organism filter to ensure relevance to human biology
- Compile targets and remove duplicates by aligning UniProtKB protein IDs
- For disease-specific studies, intersect compound targets with disease-associated genes from GeneCards and DisGeNET
Step 2: Background Gene Set Selection
- Select appropriate background genes based on experimental context
- Options include: all genes detected in omics experiments, all protein-coding genes, or genes specific to relevant tissues
- Document background selection method for reproducibility
Step 3: Enrichment Analysis Execution
- Input target gene list into ShinyGO 0.85 or equivalent platform
- Select appropriate pathway databases (GO Biological Process, Molecular Function, Cellular Component, KEGG)
- Set pathway size limits (typically 5-500 genes per pathway) to avoid overly general or specific terms
- Apply statistical threshold of FDR < 0.05 for significance
- Choose sorting method (recommended: "Select by FDR, then by Fold Enrichment")
Step 4: Results Interpretation and Visualization
- Examine significantly enriched terms in tabular format
- Generate hierarchical clustering trees to identify related GO terms
- Create network plots to visualize relationships between enriched pathways
- Use KEGG mapper to highlight this compound targets on pathway diagrams
- Identify leading-edge genes that drive pathway enrichment signals
The following workflow diagram illustrates the comprehensive computational pipeline for this compound pathway analysis:
Experimental Validation Protocol
While computational predictions provide valuable insights, experimental validation is essential to confirm this compound's biological activities. This protocol outlines key experimental approaches for validating pathway enrichment results.
Molecular Docking Validation
- Preparation of Structures: Obtain protein structures (STAT3, MAPK3, SRC) from RCSB Protein Data Bank. Prepare this compound 3D structure from PubChem and convert to suitable format using OpenBabel.
- Docking Parameters: Use AutoDock Vina with grid box size 40×40×40 Å. Set exhaustiveness to 8. Perform 10 docking runs per target.
- Analysis Criteria: Consider binding affinities ≤ -6.0 kcal/mol as indicative of strong binding. Examine residue interactions using LigPlot+.
In Vitro Cell-Based Validation
- Cell Culture: Maintain HepG2 or other relevant cell lines in appropriate media. Seed cells at optimized densities for assays.
- Treatment Protocol: Prepare this compound stock solution in DMSO. Treat cells with serial dilutions (typically 1-100 μM) for 24 hours. Include vehicle controls.
- Viability Assessment: Perform MTT or CCK-8 assays after 24-hour treatment. Measure absorbance at 570 nm. Calculate IC₅₀ values using non-linear regression.
- Gene Expression Analysis: Extract RNA from treated cells. Perform qRT-PCR for key target genes (STAT3, MAPK3, SRC). Use 2^(-ΔΔCt) method for quantification.
Table 2: Expected Experimental Results for this compound Based on Literature
| Experimental Assay | Expected Outcome | Reference Compound | Significance |
|---|---|---|---|
| MTT Cytotoxicity | Dose-dependent reduction in viability in HepG2 cells | (+)-Catechin 3-gallate | Confirms anti-proliferative activity [1] |
| Molecular Docking with STAT3 | Binding affinity ≤ -8.9 kcal/mol | Known STAT3 inhibitors | Supports computational predictions [1] |
| Molecular Docking with MAPK3 | Binding affinity ≤ -10.2 kcal/mol | Known MAPK3 inhibitors | Validates network pharmacology [1] |
| Cytochrome P450 Inhibition | Decreased NADPH-cytochrome P450 reductase activity | Grape seed procyanidins | Confirms phase I enzyme modulation [3] |
| GST Activity Assay | Increased glutathione S-transferase activity | Reference inducers | Validates phase II enzyme enhancement [3] |
Data Interpretation and Integration
Analysis of Enrichment Results
Proper interpretation of GO and KEGG enrichment results is critical for extracting meaningful biological insights about this compound's mechanisms. When analyzing enrichment outputs, researchers should consider both statistical significance (FDR q-values) and biological relevance (fold enrichment). The following guidelines will facilitate accurate interpretation:
- Prioritize Pathways: Focus initially on pathways with FDR < 0.05 and fold enrichment > 2. These represent the most statistically significant and biologically impactful findings.
- Address Multiple Testing: Recognize that with thousands of pathways tested simultaneously, some significant findings may occur by chance. The FDR correction helps control false positives, but biological context remains essential [6].
- Examine Pathway Relationships: Use hierarchical clustering trees and network plots in ShinyGO to identify clusters of related GO terms. This helps uncover overarching biological themes beyond individual significant terms [6].
- Consider Pathway Size: Large pathways (e.g., "signal transduction") often show smaller FDRs due to increased statistical power, while smaller pathways might have higher FDRs despite potential biological relevance [6].
For this compound, based on studies of closely related compounds, expected significantly enriched GO terms may include:
- Biological Process: regulation of apoptotic process, response to oxidative stress, inflammatory response
- Molecular Function: protein kinase binding, transcription factor binding, antioxidant activity
- Cellular Component: membrane raft, cytoplasm, nucleus
Expected KEGG pathways likely include AGE-RAGE signaling pathway in diabetic complications, MAPK signaling pathway, HIF-1 signaling pathway, and pathways in cancer [2] [4].
Multi-Omics Integration Approaches
Advanced this compound research can benefit from multi-omics integration, which provides a more comprehensive understanding of its mechanisms. The protocol below outlines strategies for combining pathway enrichment results with additional omics data:
Transcriptomics Integration
- Obtain differentially expressed genes (DEGs) from RNA-seq of this compound-treated versus control cells
- Perform overlap analysis between DEGs and predicted targets
- Conduct pathway enrichment on overlapping gene set
- Compare pathways identified through computational prediction versus experimental transcriptomics
Metabolomics Integration
- Identify significantly altered metabolites in this compound-treated systems via LC-MS
- Map metabolites to biochemical pathways using KEGG Mapper
- Integrate metabolic pathways with protein target pathways
- Identify points of convergence between modulated metabolites and proteins
Multi-Omics Data Fusion
- Construct comprehensive networks using Cytoscape
- Incorporate protein-protein interaction data from STRING database
- Build multi-layered networks showing connections between targets, metabolites, and pathways
- Identify key hub nodes that integrate multiple data types
The following diagram illustrates the multi-omics integration strategy for comprehensive this compound mechanism elucidation:
Conclusion and Research Applications
The application of GO and KEGG pathway enrichment analysis for this compound represents a powerful approach to deciphering the complex polypharmacology of this natural compound. Through the protocols outlined in this document, researchers can systematically identify this compound's potential protein targets, elucidate its effects on biological pathways, and generate testable hypotheses regarding its mechanisms of action.
The integrated computational and experimental framework presented here enables a comprehensive investigation of this compound's therapeutic potential across various disease contexts. Previous studies have suggested its relevance to conditions including hepatocellular carcinoma, systemic lupus erythematosus, osteoarthritis, and metabolic disorders [1] [2] [4]. The network pharmacology approach is particularly well-suited for natural products like this compound, which typically exert their effects through subtle modulation of multiple targets rather than single-target inhibition.
For researchers pursuing this compound studies, several key considerations emerge:
- Therapeutic Development: this compound's favorable drug-like properties and dual action on phase I and II metabolic enzymes support its development as a chemopreventive agent [3].
- Combination Therapy: Its multi-target nature suggests potential in combination therapies, where it may enhance efficacy or reduce resistance to conventional treatments.
- Personalized Medicine: Identification of key pathway modulations may help identify patient subgroups most likely to respond to this compound-based interventions.
- Lead Optimization: Structural insights from docking studies can guide medicinal chemistry efforts to develop more potent this compound analogs.
As research progresses, validation of this compound's mechanisms through the integrated application of computational predictions and experimental assays will be essential to translate these findings into clinical applications. The protocols provided herein offer a robust foundation for such investigations, enabling researchers to systematically unravel the therapeutic potential of this promising natural compound.
References
- 1. Underlying Mechanisms of Bergenia spp. to Treat ... [pmc.ncbi.nlm.nih.gov]
- 2. Therapeutic potential of Nelumbo nucifera Linn. in systemic ... [documentsdelivered.com]
- 3. Effects of Leucocyanidines on Activities of Metabolizing ... [pubmed.ncbi.nlm.nih.gov]
- 4. The Mechanism by Which Cyperus rotundus Ameliorates ... [pmc.ncbi.nlm.nih.gov]
- 5. The identification of metabolites from gut microbiota in ... [nature.com]
- 6. ShinyGO 0.85 [bioinformatics.sdstate.edu]
- 7. Pathway enrichment analysis and visualization of omics data ... [pmc.ncbi.nlm.nih.gov]
Leucocianidol cell viability assay protocols
Leucocianidol at a Glance
The following table summarizes the key characteristics of this compound as identified in a network pharmacology study [1].
| Property | Description |
|---|---|
| IUPAC Name | This compound [1] |
| Molecular Formula | C₁₅H₁₄O₇ [1] |
| Molecular Weight | 306.29 g/mol [1] |
| Oral Bioavailability (OB) | 30.84% [1] |
| Drug Likeness (DL) | 0.27 [1] |
| Selection Criteria | OB > 30%, DL > 0.18 [1] |
| Reported Bioactivity | Showed interactions with 41 potential gene targets in a network pharmacology model for Hepatocellular Carcinoma (HCC) [1]. |
A Workflow for Network Pharmacology
Network pharmacology is a powerful method for studying compounds like this compound that likely act on multiple targets simultaneously. The diagram below outlines a general workflow for such an investigation, from initial compound screening to experimental validation [1] [2].
Application Notes & Research Context
Based on the available research, here are the key application notes for this compound.
Research Context and Rationale
- Therapeutic Area: The study identified this compound in the context of researching natural compounds from Bergenia species for the treatment of Hepatocellular Carcinoma (HCC) [1].
- Multi-Target Strategy: The research approach was based on network pharmacology, which is ideal for complex diseases like cancer and for herbal compounds that often work by modulating multiple targets rather than a single one [1].
Proposed Mechanism of Action
- Network Effects: While not the top compound, this compound's interaction with 41 targets suggests its potential effect arises from modulating a network of genes rather than a single pathway [1].
- Pathway Enrichment: In the referenced study, the common targets of all Bergenia compounds were enriched in key cancer-related pathways. The top hub genes identified were STAT3, MAPK3, and SRC [1]. The most stable binding with these proteins was shown by another compound, (+)-catechin 3-gallate, which was then validated in cell viability assays [1].
A Generalized Cell Viability Protocol
Since a specific protocol for this compound was not found, the following is a generalized cell viability assay protocol, common in pharmacologic studies and consistent with methods used to validate related compounds [1] [3].
Objective: To determine the effect of this compound on the viability of a specific cell line (e.g., HepG2 for liver cancer) and calculate its half-maximal inhibitory concentration (IC₅₀).
Key Reagents and Equipment:
- Cell Line: Relevant to disease model (e.g., HepG2, ARPE-19) [1] [3].
- Test Compound: this compound, dissolved in an appropriate solvent (e.g., DMSO, sterile BSS), with serial dilutions prepared in cell culture medium [3].
- Viability Assay Kit: MTS or MTT assay kit [1] [3].
- Labware: 96-well microplates, CO₂ incubator, ELISA plate reader [3].
Experimental Procedure:
- Cell Plating: Seed cells in a 96-well plate at an optimal density (e.g., 5 × 10³ cells/well) and culture for 24 hours to allow adherence [3].
- Treatment:
- Prepare a dilution series of this compound (e.g., 1, 10, 50, 100 µM).
- Replace the medium in the wells with the compound-containing medium. Include control wells with solvent only.
- Incubate for a defined period (e.g., 24 hours) [1].
- Viability Measurement:
- Data Analysis:
References
- 1. Underlying Mechanisms of Bergenia spp. to Treat ... [pmc.ncbi.nlm.nih.gov]
- 2. The identification of metabolites from gut microbiota in ... [nature.com]
- 3. Effect of vital dyes on retinal pigmented epithelial cell ... [pmc.ncbi.nlm.nih.gov]
- 4. - Wikipedia IC 50 [en.wikipedia.org]
- 5. Calculating Half Maximal Inhibitory ( Concentration ) Values from... IC 50 [link.springer.com]
- 6. Determination of half -maximal inhibitory using... concentration [pmc.ncbi.nlm.nih.gov]
Leucocianidol apoptosis induction experimental methods
Current Context on Leucocianidol from Search Results
One study identified this compound as a bioactive compound from Bergenia plant species, selected for its favorable drug-like properties (Oral Bioavailability > 30%, Drug Likeness > 0.18) for researching hepatocellular carcinoma [1].
The research used a network pharmacology approach, constructing a compound-target network that suggested this compound could interact with 41 different gene targets related to cancer pathogenesis [1]. This type of study is computational and predictive, serving as a preliminary step to guide later laboratory experiments. The search results did not contain documents detailing the subsequent wet-lab experimental procedures for this compound.
General Framework for Apoptosis Assays
While specific protocols for this compound are unavailable, the general methodology for evaluating compound-induced apoptosis is well-established. The following workflow outlines the key steps and common assays used in this process.
The table below summarizes the purpose and basic principle of common assays used to investigate apoptosis.
| Assay Type | Primary Purpose | General Principle & Key Measurements |
|---|---|---|
| Cell Viability (e.g., MTT) [2] [3] | Determine cytotoxic concentration. | Measures metabolic activity; cells convert tetrazolium dye to formazan. Output: IC50 value (dose causing 50% viability loss). |
| Apoptosis Detection (Annexin V/PI) [2] | Detect early/late apoptosis and necrosis. | Fluorescently labels phosphatidylserine (externalized in apoptosis) with Annexin V-FITC and DNA (in dead cells) with Propidium Iodide. Analysis: Flow cytometry. |
| Caspase Activity Assay | Confirm activation of key apoptosis executioners. | Uses substrates that become fluorescent when cleaved by active caspase-3/7. Output: Fluorescence intensity. |
| Gene/Protein Expression [2] [3] | Elucidate molecular mechanisms. | Quantifies mRNA (via qPCR) or protein (via Western Blot) levels of pro-/anti-apoptotic genes (e.g., BAX, BCL-2, p53). |
| Cell Cycle Analysis [3] | Identify cell cycle arrest. | Stains cellular DNA with Propidium Iodide. Analysis: Flow cytometry to determine population in G0/G1, S, G2/M phases. |
Suggestions for Finding Detailed Protocols
To obtain the specific experimental details you need, I suggest the following:
- Refine Your Literature Search: Use specialized scientific databases like PubMed or Scopus with more targeted queries, for example:
("leucocyanidol" OR "this compound") AND apoptosis AND protocol, or("plant flavonoid") AND apoptosis AND "flow cytometry" method. - Consult General Protocol Repositories: Websites and commercial kits from life science companies (e.g., Thermo Fisher Scientific, BioLegend, Abcam) provide extensively detailed, step-by-step protocols for the assays mentioned above [4]. These can be readily adapted for testing any compound, including this compound.
- Review Methods in Related Research: Look for experimental papers on closely related flavonoids, such as (+)-catechin gallate or β-sitosterol, which were mentioned alongside this compound in the search results [1]. The methodologies in these papers can often be applied directly or with minimal modification.
References
Comprehensive Application Notes and Protocols: Leucocianidol Gene Expression Analysis Techniques for Drug Development
Introduction to Leucocianidol
This compound (also known as leucocyanidol or leucocyanidin) is a naturally occurring flavonoid compound belonging to the subclass of flavan-3,4-diols that has gained significant interest in pharmacological research due to its potential therapeutic applications. This compound demonstrates favorable drug-like properties with an oral bioavailability (OB) of 30.84% and drug likeness (DL) of 0.27, making it a promising candidate for further drug development investigations [1]. Recent studies have explored this compound's potential in managing various conditions, including hepatocellular carcinoma (HCC) and autoimmune diseases such as systemic lupus erythematosus (SLE) [1] [2].
The molecular structure of this compound (C15H14O7) with a molecular weight of 306.29 g/mol enables interaction with multiple biological targets, positioning it as a multi-target therapeutic agent [1]. Current research employs advanced gene expression analysis techniques to elucidate this compound's mechanisms of action, with network pharmacology emerging as a powerful approach for understanding its polypharmacological effects. These methodologies provide researchers with comprehensive tools to investigate how this compound modulates gene expression and cellular pathways, ultimately contributing to its observed therapeutic effects [1] [2].
Network Pharmacology Workflow for Target Prediction
Network pharmacology represents a paradigm shift in pharmacological research, enabling the systematic identification of compound-target-disease interactions through computational approaches. This methodology is particularly valuable for natural products like this compound, which typically exhibit polypharmacological effects through interactions with multiple biological targets rather than single-target mechanisms [1]. The workflow integrates bioinformatics, cheminformatics, and network analysis to predict and visualize the complex relationships between phytochemicals and their potential therapeutic targets.
The following diagram illustrates the comprehensive network pharmacology workflow for identifying this compound's potential gene targets and their association with disease pathways:
Figure 1: Network Pharmacology Workflow for this compound Target Identification. This diagram outlines the comprehensive process from compound data collection to experimental validation, illustrating the systematic approach to identifying this compound's potential gene targets and their association with disease pathways.
Protocol: Compound-Target Network Construction
Objective: To identify and visualize the interactions between this compound and its potential gene targets using computational approaches and network analysis.
Materials and Software:
- This compound chemical structure (PubChem CID: 440833)
- SwissTargetPrediction database (http://www.swisstargetprediction.ch/)
- STITCH database (http://stitch.embl.de/)
- Cytoscape software (version 3.8.0 or higher)
- Computer with minimum 8GB RAM and multi-core processor
Procedure:
Compound Preparation
- Download this compound structure in SDF format from PubChem database
- Convert structure to SMILES format using Open Babel or similar software
- Verify drug-likeness parameters using SwissADME or similar tool
Target Prediction
- Submit this compound SMILES string to SwissTargetPrediction with "Homo sapiens" as organism parameter
- Query STITCH database using this compound identifier
- Extract UniProtKB accession numbers for all predicted targets
- Remove duplicate targets to create a unique target set
Network Construction
- Import target list into Cytoscape software
- Create a compound-target network with this compound as central node
- Use NetworkAnalyzer plugin to compute topological parameters
- Analyze network density, centralization, and heterogeneity
- Identify hub targets based on degree ranking [1]
Quality Control:
- Ensure all predicted targets have confirmed UniProtKB accession numbers
- Verify network connectivity to identify isolated nodes
- Cross-reference predictions with similar flavonoids to reduce false positives
Experimental Validation of this compound Targets
Molecular Docking Analysis
Objective: To validate the binding interactions between this compound and key protein targets identified through network pharmacology using computational docking studies.
Materials and Software:
- Protein Data Bank (PDB) structures of target proteins
- AutoDock Vina or similar molecular docking software
- PyMOL molecular visualization system
- This compound 3D structure file (MOL2 or PDB format)
Procedure:
Protein Preparation
- Download high-resolution crystal structures of STAT3, MAPK3, and SRC from PDB
- Remove water molecules and heteroatoms using PyMOL
- Add polar hydrogen atoms and compute Gasteiger charges
- Save prepared structures in PDBQT format
Ligand Preparation
- Obtain this compound 3D structure from PubChem
- Perform energy minimization using MMFF94 force field
- Set rotatable bonds for flexible docking experiments
- Convert to PDBQT format for docking compatibility
Docking Protocol
- Define grid box dimensions to encompass active site residues (40×40×40 Å)
- Set exhaustiveness parameter to 8 for comprehensive search
- Run AutoDock Vina with default parameters
- Generate 10 docking poses for each target protein
- Calculate binding energies (kcal/mol) for each pose
Analysis and Validation
- Select pose with most favorable binding energy for each target
- Identify hydrogen bonds and hydrophobic interactions using LigPlot+
- Visualize binding modes in PyMOL
- Compare binding energies with known inhibitors for reference [1]
Cell-Based Validation Assays
Objective: To experimentally verify this compound's effects on gene expression and cell viability in relevant cell line models.
Materials:
- HepG2 cells (ATCC HB-8065) or other appropriate cell lines
- This compound (purity ≥95% by HPLC)
- Cell culture reagents: DMEM, FBS, penicillin-streptomycin
- MTT assay kit or similar viability assay
- RNA extraction kit (TRIzol or similar)
- RT-PCR reagents and equipment
Procedure:
Cell Viability Assay
- Seed HepG2 cells in 96-well plates (5×10³ cells/well)
- Allow attachment for 24 hours in complete medium
- Treat with this compound at concentrations ranging from 1-100 μM
- Include positive control (e.g., sorafenib for HCC models) and vehicle control
- Incubate for 24-72 hours at 37°C, 5% CO₂
- Assess viability using MTT assay per manufacturer's protocol
- Measure absorbance at 570nm with reference at 630nm
- Calculate IC₅₀ values using non-linear regression analysis [1]
Gene Expression Analysis Using RT-qPCR
- Seed cells in 6-well plates (2×10⁵ cells/well)
- Treat with this compound at IC₅₀ concentration for 24 hours
- Extract total RNA using TRIzol reagent
- Quantify RNA concentration and purity (A260/A280 ratio 1.8-2.0)
- Synthesize cDNA using reverse transcriptase with oligo(dT) primers
- Perform qPCR with SYBR Green master mix
- Use primers for STAT3, MAPK3, SRC, and reference genes (GAPDH, ACTB)
- Analyze data using ΔΔCt method with appropriate normalization
Table 1: Expected Results from this compound Gene Expression Analysis
| Target Gene | Expected Fold Change | Biological Significance | Validation Method |
|---|---|---|---|
| STAT3 | ↓ 0.4-0.6 fold | Inhibition of JAK-STAT signaling pathway | qPCR, Western blot |
| MAPK3 | ↓ 0.5-0.7 fold | Modulation of cell proliferation signals | qPCR, Kinase assay |
| SRC | ↓ 0.3-0.5 fold | Regulation of oncogenic signaling | qPCR, Phosphorylation assay |
| TNF-α | ↓ 0.2-0.4 fold | Anti-inflammatory effects | ELISA, qPCR |
| IL-6 | ↓ 0.3-0.5 fold | Immunomodulatory activity | ELISA, qPCR |
Data Analysis and Interpretation
Functional Enrichment Analysis
Objective: To interpret the biological significance of this compound-modulated genes through systematic functional enrichment analysis.
Materials and Software:
- List of significantly modulated genes from expression analysis
- WebGestalt (http://www.webgestalt.org/) or similar enrichment tool
- R software with clusterProfiler package
- Computer with internet access and statistical software
Procedure:
Gene Ontology (GO) Analysis
- Upload gene list to WebGestalt platform
- Select "Homo sapiens" as reference species
- Choose GO enrichment analysis with three categories:
- Biological Process (BP)
- Molecular Function (MF)
- Cellular Component (CC)
- Set significance threshold at FDR < 0.05
- Use hypergeometric test for enrichment analysis
- Apply Benjamini-Hochberg multiple test correction
KEGG Pathway Analysis
- Perform KEGG pathway enrichment using WebGestalt or clusterProfiler
- Identify significantly enriched pathways (FDR < 0.05)
- Focus on pathways relevant to studied disease context
- Generate pathway maps highlighting this compound-affected genes
Protein-Protein Interaction (PPI) Network Analysis
- Input target genes into STRING database (https://string-db.org/)
- Set confidence score > 0.700 for interactions
- Export PPI network for visualization in Cytoscape
- Identify hub genes using cytoHubba plugin
- Calculate topological parameters (degree, betweenness, closeness) [1]
Table 2: Data Analysis Methods for this compound Transcriptomic Studies
| Analysis Type | Primary Tool | Key Parameters | Interpretation Guidelines |
|---|---|---|---|
| GO Enrichment | WebGestalt | FDR < 0.05, Minimum 5 genes/category | Focus on biologically relevant processes; exclude overly general terms |
| KEGG Pathway | clusterProfiler | P-value < 0.01, Gene count ≥ 3 | Prioritize pathways with known disease associations; verify with literature |
| PPI Network | STRING/Cytoscape | Confidence > 0.7, Degree centrality | Hub genes with high betweenness represent key regulatory targets |
| Modular Analysis | MCODE plugin | Node score > 0.2, K-core = 2 | Identify functional protein complexes affected by treatment |
Technical Considerations for Data Quality
RNA Quality Control:
- Ensure RNA Integrity Number (RIN) > 8.0 for microarray analysis
- Verify absence of genomic DNA contamination
- Confirm A260/A280 ratio between 1.8-2.0
- Use same amount of input RNA for all samples (100-500ng)
Normalization Methods:
- Apply RMA (Robust Multi-array Average) for microarray data
- Use quantile normalization to reduce technical variability
- Implement background correction using established algorithms
- For qPCR data, select stable reference genes using GeNorm or BestKeeper
Statistical Analysis:
- Apply appropriate multiple testing correction (Benjamini-Hochberg FDR)
- Use parametric tests for normally distributed data
- Employ non-parametric alternatives (Mann-Whitney) for non-normal distributions
- Maintain consistent significance threshold (p < 0.05) across analyses
Technical Considerations and Troubleshooting
Common Technical Challenges
Sample Quality Issues:
- Problem: Degraded RNA yields unreliable expression data
- Solution: Implement rapid processing, use RNA stabilization reagents, and verify RIN values before proceeding
High Background in Microarray Data:
- Problem: Fluorescence background noise obscures true signal
- Solution: Implement background correction algorithms, use validated probe sets, and apply proper normalization techniques [3]
Weak Binding Signals in Docking:
- Problem: Poor binding scores despite network pharmacology predictions
- Solution: Verify protein structure preparation, check ligand protonation states, and consider flexible receptor docking
Reproducibility and Validation
Experimental Replication:
- Perform minimum of three biological replicates for each experiment
- Include technical replicates to assess assay variability
- Use randomized sample processing to avoid batch effects
- Maintain detailed documentation of all protocol modifications
Orthogonal Validation:
- Confirm microarray results with RT-qPCR for key targets
- Validate protein-level effects using Western blotting or flow cytometry
- Use multiple cell lines or primary cells to confirm biological relevance
- Compare with public datasets when available for benchmarking
Conclusion
The application notes and protocols presented here provide researchers with a comprehensive framework for investigating this compound's effects on gene expression using modern computational and experimental approaches. The integration of network pharmacology with experimental validation creates a powerful strategy for elucidating the molecular mechanisms of this promising natural compound. The structured workflows, standardized protocols, and analytical methods detailed in this document will enable reproducible research and facilitate the advancement of this compound in drug development pipelines.
As research progresses, these protocols can be adapted to investigate this compound's effects in specific disease contexts and combined with emerging technologies such as single-cell RNA sequencing and CRISPR-based screening to further deepen our understanding of its therapeutic potential. The systematic approach outlined here serves as a template for studying other natural products with complex mechanisms of action.
References
Leucocianidol peak tailing in HPLC resolution
Understanding Peak Tailing and Its Impacts
A tailing peak is asymmetrical, with a prolonged trailing edge. The tailing factor (Tf) or asymmetry factor (As) is used to measure it [1] [2]. Ideally, Tf should be close to 1.0. Values between 1.2 and 2.0 are often acceptable, but values exceeding 2.0 are generally considered unacceptable for precise analytical methods [1] [3] [4].
Even minor tailing can significantly degrade resolution by overlapping neighboring peaks, lead to inaccurate quantitative integration, and reduce the overall robustness of your method [1] [5].
Quick-Action Troubleshooting Checklist
For a fast diagnosis, use this checklist to identify the most likely causes based on your symptoms.
| Symptom | Most Likely Causes | Immediate Action |
|---|---|---|
| Tailing for only one/some peaks, especially basic compounds | Secondary interactions with residual silanols on stationary phase [1] [3] [2] | Lower mobile phase pH, use a highly end-capped column, or add a silanol suppressor like TEA [1] [5] [2] |
| All peaks are tailing | Column void or blocked inlet frit; Mass overload; Instrument issues (e.g., extra-column volume) [1] [2] [6] | Reverse and flush the column; Dilute your sample 10-fold; Check tubing and fittings for dead volume [1] [3] [6] |
| Tailing worsened with new column | Mismatched column chemistry [1] | Switch to a column designed for basic/ polar compounds (e.g., polar-embedded, CSH) [1] |
| Sudden onset of tailing | Column degradation; Change in mobile phase (pH, buffer strength, contamination) [1] [6] | Prepare a fresh mobile phase; Condition or replace the column [1] |
Systematic Troubleshooting Workflow
Follow this logical workflow to diagnose and resolve peak tailing issues methodically. The process is visualized in the diagram below.
Step 1: Confirm and Quantify Tailing
First, calculate the tailing factor to confirm the severity. Your HPLC software can usually do this automatically. A common formula is Tf = W₀.₀₅ / (2 × f), where W₀.₀₅ is the peak width at 5% height and 'f' is the distance from the peak's front to its apex at 5% height [1] [4].
Step 2: Perform a Column and System Health Check
- Benchmark with a Test Mixture: Inject a standard mixture that previously yielded good peaks. If tailing persists, the issue is likely with the column or instrument [2].
- Check for Column Voids: A common cause of tailing for all peaks. Symptoms include a sudden increase in tailing and a change in backpressure. A temporary fix is to reverse the column (after disconnecting it from the detector) and flush it with a strong solvent [1] [2].
- Minimize Extra-Column Volume: Excess volume in tubing, fittings, or the detector cell can cause band broadening and tailing. Use the shortest possible tubing with the smallest appropriate internal diameter (e.g., 0.12-0.17 mm ID) [1] [2].
Step 3: Optimize Method Conditions for Leucocianidol
Since this compound is a flavonoid with phenolic groups, it can act as a weak acid. Its ionization and interaction with the column are highly dependent on mobile phase conditions.
- Adjust Mobile Phase pH: For acidic compounds, tailing can occur if the pH is too high, causing ionization. Keep the mobile phase pH at least 1-1.5 units below the pKa of your analyte to suppress ionization. A pH between 2.5 and 4.5 is often a good starting point [1] [3].
- Increase Buffer Concentration: A higher buffer concentration (e.g., 20-50 mM) can more effectively mask ionic interactions with residual silanols on the stationary phase [2].
- Ensure Solvent Compatibility: The solvent used to dissolve your sample should not be stronger than the initial mobile phase. Otherwise, it can cause peak distortion. Match the sample solvent to the mobile phase as closely as possible [1] [6].
Step 4: Select the Right Column
The choice of column is critical. For polyphenols like this compound, consider these options [1] [3]:
- Use a "Deactivated" Column: Select a column made from high-purity, type-B silica that is fully end-capped to reduce the number of acidic silanol groups.
- Specialty Columns: Polar-embedded phases (e.g., amide, phenyl-hexyl) or charged surface hybrid (CSH) columns can offer better control over secondary interactions for challenging analytes.
Advanced Method Optimization Protocols
If basic troubleshooting is insufficient, these structured protocols can help systematically optimize your method.
Protocol 1: Mobile Phase pH Scouting
Objective: To find the optimal pH for peak symmetry of this compound.
- Prepare three separate mobile phase buffers (e.g., phosphate or formate) at pH 2.5, 4.0, and 5.5.
- Keep the organic modifier (e.g., acetonitrile) concentration constant for an isocratic method or use the same gradient profile.
- Inject a standard this compound solution using each mobile phase.
- Measure the tailing factor and retention time at each pH. The pH yielding a Tf closest to 1.0 without compromising retention is optimal.
Protocol 2: Column Screening and Evaluation
Objective: To select the most suitable column chemistry.
- Select 2-3 different columns for testing. A good starting set is:
- Standard C18 (for baseline)
- Heavy-duty end-capped C18 (e.g., ZORBAX Eclipse Plus)
- Polar-embedded or phenyl column
- Use the same mobile phase, temperature, and flow rate across all tests.
- Inject the same standard mixture and record the tailing factor, theoretical plates, and retention time for this compound.
- Compare results to select the column providing the best symmetry and efficiency.
Frequently Asked Questions (FAQs)
Q1: What are the regulatory limits for the tailing factor in system suitability tests? For methods requiring high precision, such as in pharmaceutical analysis, the tailing factor (Tf) should generally be less than 2.0, and often stricter limits like ≤ 1.5 are applied. Chapter 621 of the U.S. Pharmacopeia specifies that peak asymmetry should be less than 1.8 [5] [7].
Q2: Can sample preparation affect peak shape? Yes. A dirty sample matrix can contaminate the column, leading to tailing. Implementing a solid-phase extraction (SPE) clean-up step can significantly improve peak shape. Also, ensure your sample is fully dissolved and compatible with the mobile phase [1] [3].
Q3: Why should I use an internal standard? An internal standard is a compound added to the sample that elutes at a different time. It helps correct for minor, run-to-run variations in retention time, improving the accuracy and reliability of quantitative analysis [8] [4].
References
- 1. Tailing Peaks in HPLC: A Practical Guide to Causes ... [uhplcs.com]
- 2. The LCGC Blog: HPLC Diagnostic Skills II – Tailing Peaks [chromatographyonline.com]
- 3. Peak Tailing in HPLC [elementlabsolutions.com]
- 4. System Suitability Test in HPLC – Key Parameters Explained [assayprism.com]
- 5. Strategies for Improving Peak Tailing | LCGC International [chromatographyonline.com]
- 6. LC Troubleshooting Essentials: A Guide to Common ... [chromatographyonline.com]
- 7. System Suitability in HPLC Analysis [pharmaguideline.com]
- 8. Retention Time Drift in HPLC: Causes, Corrections, and ... [uhplcs.com]
Leucocianidol retention time shift troubleshooting
Troubleshooting Guide: Retention Time Shifts
| Observed Shift Pattern | Likely Causes | Immediate Actions & Checks |
|---|
| Gradual Decrease in RT [1] | - Wrong solvent composition/pH [1] [2]
- Increasing column temperature [1]
- Loss of bonded stationary phase (column aging) [1] [3]
- Increasing flow rate [1] | - Prepare fresh, well-mixed mobile phase [1].
- Verify column oven temperature stability [1].
- Replace the column if degraded [1]. | | Gradual Increase in RT [1] | - Wrong solvent composition/pH [1] [2]
- Decreasing column temperature [1]
- Decreasing flow rate (e.g., from a system leak) [1] | - Check for mobile phase evaporation; cover reservoirs [1] [2].
- Confirm column thermostat setting [1].
- Perform a system pressure test to check for leaks [1]. | | Fluctuating RT (Unpredictable) [1] | - Insufficient mixing of mobile phase [1]
- Insufficient column equilibration, especially after a gradient [1] [4]
- Unstable flow rate or pressure [1]
- Fluctuating column temperature [1] | - Ensure mobile phase is freshly prepared and degassed [1].
- Increase equilibration time (e.g., 10-15 column volumes) [1].
- Check pump for air bubbles or faulty seals [1] [5]. | | All Peaks Shifted Equally [5] [4] | - Flow rate changes [5] [4]
- Column temperature changes [5] [4] | - Manually check flow rate accuracy [5].
- Verify column oven calibration and stability [4]. | | Only Early Peaks Shifted [5] | - Sample solvent mismatch (sample in stronger solvent than mobile phase) [5] [4] [3] | - Re-constitute sample in a solvent that matches the initial mobile phase composition [5] [2]. | | Random or Varying Shifts [5] | - Sample matrix effects or pH differences [5]
- Column contamination or buildup of sample matrix [5] [6] | - Match sample pH to mobile phase pH [5] [4].
- Flush the column with a strong solvent or replace the guard column [5] [6]. |
Systematic Diagnostic Workflow
When you encounter a retention time shift, follow this logical workflow to identify the root cause efficiently. The process below helps you isolate the problem through a series of checks and experiments.
Detailed Steps for the Workflow
Reproduce and Quantify the Shift [4]:
- Action: Inject a system suitability standard or a recent standard that has previously shown stable retention times.
- Diagnosis: If the standard's retention time has also shifted, the issue is with the instrument, solvents, or column. If the standard is stable, the problem is likely specific to your sample preparation [4].
Check System Pressure [4]:
- Action: Observe the system's backpressure.
- Diagnosis: A sudden change in pressure often indicates a clogged frit, a blockage, or a column issue. A gradual pressure rise typically suggests column fouling or contamination [4].
Check and Remake Mobile Phase [1] [2]:
- Action: This is a highly common fix. Prepare a fresh batch of mobile phase, ensuring accurate composition, pH, and adequate degassing.
- Diagnosis: If the problem is resolved, the cause was solvent evaporation, incorrect preparation, or pH drift [2].
Check Instrumental Factors [1] [5] [4]:
- Flow Rate: Manually verify the flow rate by collecting eluent at the column outlet and measuring the volume over time [5] [4].
- Temperature: Confirm the column oven temperature is stable and calibrated. Even a ±1 °C change can cause a noticeable RT shift [1] [4].
- Leaks & Bubbles: Check for leaks in the flow path. Inspect pump seals and purge the pump to remove any air bubbles [1] [5].
Best Practices for Prevention
To maintain stable retention times in your experiments, consider adopting these routine practices [4]:
- System Suitability Testing: Run a system suitability standard at the start of each batch and track retention times over time using a control chart [4].
- Mobile Phase Management: Always use fresh, properly prepared mobile phases. Filter and degas solvents. Cover solvent bottles to prevent evaporation [1] [2].
- Column Care: Use a guard column to protect the analytical column. Log the number of samples and types of matrices a column has been exposed to [5] [4].
- Preventive Maintenance: Adhere to a regular schedule for replacing pump seals, check valves, and other consumables as recommended by the instrument manufacturer [4].
References
- 1. Troubleshooting Peak Retention Time Shifts and Non- ... [community.agilent.com]
- 2. [Readers Insight] Retention Time Drifts: Why Do They Occur? [welch-us.com]
- 3. Essentials of LC Troubleshooting, Part II [chromatographyonline.com]
- 4. How to troubleshoot shift in Retention time in Liquid ... [linkedin.com]
- 5. Why is my LC Retention Time Shifting? [restek.com]
- 6. LC Troubleshooting—Retention Time Shift [restek.com]
Leucocianidol low recovery extraction optimization
Frequently Asked Questions
What is leucocianidol and why is its recovery low? this compound is a plant-based flavonoid (a type of phytochemical) investigated for its potential pharmacological activities, such as larvicidal properties [1]. Low recovery can be attributed to its chemical instability or inefficient extraction from the plant matrix.
What are the key drug-likeness parameters for this compound? In pharmacological research, active plant compounds are often screened based on specific parameters to predict their potential as oral drugs. The table below lists the known parameters for this compound compared to a similar compound, (+)-catechin gallate [2].
| Parameter | This compound | (+)-Catechin gallate (Reference) |
|---|---|---|
| Oral Bioavailability (OB) | > 30% [2] | > 30% [2] |
| Drug-Likeness (DL) | > 0.18 [2] | > 0.18 [2] |
Troubleshooting Guide for Low Recovery
If you are experiencing low yields, consider the following potential issues and solutions.
| Problem | Possible Causes | Suggested Solutions |
|---|
| Low Extraction Yield | Inefficient solvent system; Incorrect particle size; Inadequate extraction time or temperature. | - Optimize solvent (test ethanol/water mixtures).
- Reduce plant material particle size.
- Increase extraction time/temperature within stability limits. | | Compound Degradation | Exposure to light, heat, or oxygen during extraction. | - Perform extractions in darkened glassware.
- Use an inert atmosphere (e.g., nitrogen).
- Lower processing temperatures. | | Inefficient Identification | Co-elution with other compounds in crude extracts; lack of standard. | - Use standardized analytical methods (HPLC, LC-MS).
- Employ purification techniques like column chromatography to isolate the compound first [1]. |
Experimental Protocol: Ultrasound-Assisted Extraction (UAE)
While a specific protocol for this compound was not found, the following optimized method for extracting anthocyanins (which are structurally similar polyphenols) from plant material can serve as a robust starting point for your optimization experiments [3].
- Equipment & Reagents: Dried and powdered plant source material, Ethanol, Deionized water, Ultrasonic bath or sonotrode, Centrifuge, Filter paper, Volumetric flasks, Spectrophotometer or HPLC for analysis.
- Procedure:
- Preparation: Dry plant material (e.g., bark, leaves) and grind it into a fine powder [1].
- Setup: Weigh a specified amount of powder (e.g., 1g) into a glass vial.
- Extraction: Add an ethanol-water mixture (optimized at 60% ethanol) at a liquid-to-solid ratio of 30 mL/g [3].
- Sonication: Extract using an ultrasonic probe (sonotrode) for 6 minutes [3]. Keep the vessel covered to minimize solvent evaporation and light exposure.
- Separation: Centrifuge the mixture to separate the solid residue. Filter the supernatant for analysis.
- Analysis: Determine the total this compound content in the extract using HPLC against a pure standard. Calculate the recovery percentage.
The workflow for developing and troubleshooting an extraction process can be summarized as follows:
Key Optimization Strategies
- Systematic Optimization: Use experimental design (e.g., Response Surface Methodology with a Box-Behnken design) to simultaneously study the impact of multiple factors like time, solvent concentration, and liquid-to-solid ratio, rather than testing one variable at a time [3].
- Stability First: If initial recovery is poor, prioritize assessing the compound's stability under different extraction conditions (pH, temperature, light) as this is a common issue with sensitive polyphenols [4].
- Purification Before Analysis: Complex plant extracts can interfere with analysis. If you have a reference standard, first use simple purification methods to isolate this compound from the crude extract for a more accurate recovery calculation [1].
References
- 1. Terminalia Arjuna (Roxb.) Wight & amp; Arn [openbiotechnologyjournal.com]
- 2. Underlying Mechanisms of Bergenia spp. to Treat ... [mdpi.com]
- 3. Optimization of Anthocyanin Extraction from Purple Sweet ... [pubmed.ncbi.nlm.nih.gov]
- 4. Natural Dietary Polyphenolic Compounds Cause ... [sciencedirect.com]
Troubleshooting Guide: Solubility & Stability Issues
The core challenge with compounds like leucocianidol often lies in their chemical instability in solution, which can manifest as poor solubility, peak tailing, or the formation of extra peaks. The table below outlines common symptoms and their solutions.
| Symptom | Potential Cause | Corrective Action |
|---|---|---|
| Poor solubility in aqueous mobile phases | Zwitterionic structure or intermolecular bonding at neutral pH [1] | Use acidic mobile phases (e.g., 0.1% TFA, 0.1% formic acid) to protonate the analyte [1] [2]. |
| Peak tailing or broadening | Ionic interaction with residual silanols on the C18 column [2] | Use a low-pH mobile phase (<3) to suppress silanol ionization; use high-quality, end-capped columns [1] [2]. |
| Extra peaks in chromatogram; solution darkens | Chemical degradation/oxidation of the analyte over time [1] | Prepare mobile phase and standards in acidic solvents (e.g., 0.1 M HCl); use fresh solutions [1]. |
| Variable retention times and poor peak shape | Inadequate buffering capacity; inconsistent pH [2] | Use a buffer (e.g., phosphate) for precise pH control instead of simple acid additives for critical assays [2]. |
| Low analyte recovery | Stationary phase dewetting (for 100% aqueous mobile phases) [1] | Maintain a certain percentage of organic solvent (e.g., 1-5%) in the mobile phase to wet the column [1]. |
Method Optimization & FAQs
Frequently Asked Questions
Q1: What is the most critical factor to prevent this compound degradation during analysis? The pH of the solvent and mobile phase is paramount. For catechol-containing compounds like this compound and L-Dopa, working in acidic conditions (pH 2-3) is crucial. This suppresses auto-oxidation and enzymatic activity (e.g., from polyphenol oxidases) that lead to degradation and polymerization [1].
Q2: Which organic modifier is better for this compound, methanol or acetonitrile? Both have their merits, and testing both is recommended during method development.
- Acetonitrile is often preferred for its stronger eluting power and lower viscosity, which leads to higher column efficiency and lower backpressure [2].
- Methanol offers different selectivity as it is a protic solvent (can act as both a proton donor and acceptor) and is less expensive [2]. The final choice depends on the separation selectivity you achieve.
Q3: My this compound solution changed color. Is it still usable? No. A darkening color (e.g., turning brown or black) is a strong visual indicator of oxidation and degradation, likely forming melanin-like polymers [1]. The concentration of the parent compound would have changed, making quantitative analysis unreliable. You should discard the solution and prepare a fresh one in an appropriate acidic solvent.
Mobile Phase Selection Strategy
The following workflow outlines a systematic approach to developing a robust method for a challenging analyte like this compound.
Optimized Mobile Phase Components
Based on the literature for similar compounds, the following table provides a summary of recommended mobile phase components.
| Component | Recommendation | Rationale & Notes |
|---|---|---|
| Aqueous Phase (A) | Acidified water with 0.1% v/v Trifluoroacetic Acid (TFA) or 0.1% v/v Formic Acid [2]. | Suppresses analyte ionization and silanol interactions; TFA offers lower pH (~2.1). For MS detection, formic acid is preferred [2]. |
| Organic Phase (B) | Acetonitrile or Methanol with 0.1% of the same acid additive [2]. | Maintains consistent ionic strength; acetonitrile generally provides better efficiency [2]. |
| Buffer | For highest precision, use phosphate buffer at pH ~2.5 [2]. | Provides superior pH control; not MS-compatible. Use for UV-based methods requiring high robustness. |
| Sample Solvent | 0.1 M HCl or the initial mobile phase (e.g., 5% organic in acidic water) [1]. | Acidic environment stabilizes the analyte against oxidation during storage. |
Experimental Protocol: Stability and Solubility Assessment
This procedure helps you verify the stability of this compound in your chosen solvent system.
Objective: To confirm the chemical stability of a this compound standard solution under the selected acidic conditions over a defined period [1].
Materials:
- This compound reference standard
- Hydrochloric acid (HCl, 1 M and 0.1 M)
- Acetonitrile (HPLC grade)
- Water (HPLC grade)
- Volumetric flasks, pipettes, HPLC vials
- HPLC system with UV-Vis or DAD detector
Procedure:
- Standard Solution Preparation: Prepare a this compound stock solution at a concentration of 50-100 mg/L in the following solvents:
- Solvent A: 0.1 M HCl
- Solvent B: Acidic water (e.g., 0.1% Formic acid)
- Solvent C: Neutral water (as a control)
- Storage: Aliquot each solution into several HPLC vials. Store them at room temperature and protected from light.
- Analysis: Inject each solution immediately after preparation (T=0). Re-inject the same solutions at intervals (e.g., 4 hours, 24 hours, 1 week) using a preliminary HPLC method.
- Evaluation: Monitor for changes in:
- Chromatographic Peak Area: A significant decrease indicates degradation.
- Peak Purity/Presence of New Peaks: The appearance of new peaks is a direct sign of decomposition [1].
- Visual Inspection: Note any darkening of the solution.
References
Leucocianidol column selection for HPLC separation
Troubleshooting Common Issues
If your initial separation is unsatisfactory, you can optimize the method by adjusting key parameters.
| Issue | Possible Causes | Troubleshooting Actions |
|---|
| Poor Peak Shape (Tailing) | - Column degradation/deactivation
- Silanol interactions
- Inappropriate mobile phase pH | - Use a C18 column with high purity silica and dense bonding [1]
- Consider a mobile phase buffer to control pH [2] | | Insufficient Resolution | - Poor selectivity
- Solvent strength too high/too low
- Co-elution of compounds | - Optimize organic modifier ratio (Acetonitrile vs. Methanol) [3] [2]
- Adjust gradient profile (if using) [2] | | Long Analysis Time | - Mobile phase strength too weak
- Flow rate too low | - Increase the percentage of organic modifier [1]
- Consider a shorter column or smaller particles (e.g., 3 µm) [3] | | Low Sensitivity | - Suboptimal detection wavelength
- Significant band broadening | - Use PDA detector to find λmax for leucocyanidol; avoid wavelengths <200 nm [2]
- Reduce system void volumes [1] |
A Workflow for Method Development
The following diagram outlines a systematic approach to developing and optimizing your HPLC method.
FAQs for Technical Support
Q1: What is the best column for analyzing leucocyanidol and similar flavonoids? While a standard C18 column is the best starting point [2], if you encounter issues with peak tailing, consider a C18 column made with high-purity, fully end-capped silica to minimize secondary interactions with residual silanol groups [1].
Q2: Should I use isocratic or gradient elution? For simple mixtures where leucocyanidol is the main component of interest, isocratic elution is simpler and provides a more stable baseline [3]. For complex plant extracts where leucocyanidol must be separated from many other compounds, gradient elution is necessary as it can resolve a much larger number of components [2].
Q3: My leucocyanidol peak is tailing. What should I do? Peak tailing often indicates undesirable interactions with the stationary phase. First, try modifying the mobile phase, such as adding a small amount of acid (like 0.1% formic acid) to suppress the ionization of silanol groups. If the problem persists, the column itself might be degraded, or a column with different packing characteristics may be needed [1].
Q4: How do I validate my HPLC method for quantifying leucocyanidol? Method validation should follow established guidelines (e.g., ICH). Key parameters to assess include:
- Specificity: Confirming that the leucocyanidol peak is pure and free from interference.
- Linearity and Range: Preparing a series of standard solutions to demonstrate a linear response across the expected concentration range.
- Accuracy: Performing recovery studies by spiking a known amount of leucocyanidol into a sample.
- Precision: Evaluating repeatability (multiple injections of the same sample) and intermediate precision (different days, analysts, or instruments) [2].
References
Leucocianidol mass spectrometry detection parameters
Frequently Asked Questions (FAQs)
Q1: What are the typical challenges when detecting plant-based flavonoids like Leucocianidol via LC-MS/MS? The analysis of flavonoids such as this compound presents several common challenges:
- Ion Suppression: Co-eluting matrix components from the plant extract can suppress or enhance the ionization of your target analyte, leading to inaccurate quantification [1].
- Low Abundance: The compound may be present in very low concentrations, requiring a highly sensitive instrument and often a preconcentration step like Solid-Phase Extraction (SPE) [1].
- Chromatographic Resolution: Separating this compound from its structural isomers and other phenolic compounds requires optimized liquid chromatography conditions [2].
- In-source Fragmentation: Some flavonoids can be fragile and may undergo unintended fragmentation in the ion source, complicating the spectrum.
Q2: How can I improve the sensitivity and reduce noise for my this compound assay? Improving sensitivity is a multi-faceted process:
- Sample Preparation: Implement a robust SPE protocol to clean up your sample and pre-concentrate the analyte. The use of Design of Experiments (DoE) and Response Surface Methodology (RSM) is highly recommended for optimizing SPE parameters such as sample pH, volume, and elution solvent for maximum recovery [1].
- Instrument Denoising: For data-independent acquisition (DIA) methods, advanced bioinformatics algorithms like CRANE (Chemical and Random Additive Noise Elimination) can be applied to raw MS data. This technique uses a 2D undecimated wavelet transform to remove baseline, chemical, and random noise, which can significantly improve peptide (and by extension, small molecule) identification and quantification [3].
- Source Maintenance: Ensure your ESI source is clean to prevent signal loss.
Troubleshooting Guide
The following table outlines common issues, their potential causes, and recommended actions.
| Problem | Possible Cause | Suggested Solution |
|---|---|---|
| Weak or No Signal | Suboptimal ionization efficiency; Low concentration | Check ESI source parameters (temp., gas flow); Use positive ion mode first; Pre-concentrate sample via SPE [1]. |
| High Background Noise | Chemical noise from sample matrix; Instrument contamination | Improve chromatographic separation; Apply algorithmic denoising (e.g., CRANE [3]); Implement stricter sample clean-up protocols. |
| Poor Chromatographic Peak Shape | Incompatible mobile phase; Column issues | Adjust pH and gradient of mobile phase; Use a column suitable for phenolic compounds (e.g., C18 with high purity silica). |
| Irreproducible Results | Inconsistent sample preparation; Instrument drift | Automate sample prep steps where possible; Use internal standards; Follow a strict instrument calibration schedule. |
Detailed Experimental Protocols
While a direct protocol for this compound is not available, the following workflows, derived from the search results for similar analyses, provide a robust foundation which you can adapt.
1. Sample Preparation and SPE Optimization using DoE This protocol is based on the optimization of multi-residue analysis in water samples, a principle that can be adapted for plant extracts [1].
- Step 1: Sample Pre-treatment. Reconstitute your dried plant extract in a suitable solvent (e.g., methanol/water mixture) and centrifuge to remove particulate matter.
- Step 2: Solid-Phase Extraction. Use a reversed-phase SPE cartridge.
- Step 3: Experimental Design. To optimize efficiency, use a Response Surface Methodology (RSM) approach. Key parameters to vary and optimize are:
- Sample pH: Test a range from 3 to 4.
- Sample Volume: Evaluate different loading volumes (e.g., 100-400 mL for environmental water, scale down for extracts).
- Elution Solvent: Test different volumes and compositions of a strong solvent like ethanol.
- Step 4: Analysis. The optimal conditions are expected to yield an average extraction efficiency of around 65% and an absolute recovery of 73% for your target analyte [1].
2. LC-MS/MS Analysis with Denoising This protocol integrates chromatographic separation with advanced data processing [2] [3].
- Step 1: Liquid Chromatography.
- Column: XSelect (100 mm × 2.1 mm, 2.5 μm) or equivalent C18 column.
- Mobile Phase: (A) 0.1% Formic acid in H2O; (B) 0.1% Formic acid in 50% Acetonitrile/Methanol.
- Gradient: Run a linear gradient from 95% A to 5% A over 16 minutes, hold at 5% A for 3 minutes, then re-equilibrate [2].
- Flow Rate: 300 μL/min.
- Step 2: Mass Spectrometry.
- Ionization: Electrospray Ionization (ESI), positive mode.
- Source Conditions: Temperature: 150°C; Desolvation Temperature: 500°C; Capillary Voltage: 3.20 kV; Cone Voltage: 40 V [2].
- Acquisition Mode: Data-Independent Acquisition (DIA) is recommended for untargeted screening. Set the collision energy to a low function (e.g., 0 V) and a ramped high function (e.g., 10-50 V) for fragmentation data [2] [3].
- Step 3: Data Denoising.
- Process the raw MS data files using the CRANE algorithm.
- The software applies a 2D undecimated wavelet transform to jointly consider the m/z and retention time dimensions, effectively suppressing baseline, chemical, and random noise [3].
- This step is performed before downstream identification and quantification analyses.
Workflow Diagram for Method Development
The following diagram visualizes the comprehensive workflow for developing and troubleshooting a this compound detection method, incorporating the protocols above.
References
Leucocianidol sample preparation contamination issues
Frequently Asked Questions
- Q1: What are the common signs of contamination in my sample analysis? You might observe elevated baseline signals, unexpected peaks in your chromatograms that interfere with your target analyte, or significant ion suppression, which can reduce the detection of your compound of interest [1].
- Q2: I've followed my protocol, but my results are inconsistent. Could contamination be the cause? Yes. Inconsistent results, especially a sudden loss of signal or sensitivity, can often be traced to a new source of a mobile phase additive or a reagent that introduces an ion-suppressing contaminant [1].
- Q3: What are the most overlooked sources of contamination? The analyst is a very common source. Keratins from skin and hair, amino acids, and lipids can be inadvertently transferred to samples and solvents if proper gloves are not worn. Residual detergents from washed glassware are another frequent and serious contaminant source [1].
Troubleshooting Guide: Common Contaminants & Solutions
The table below outlines frequent contamination sources and actionable measures to mitigate them.
| Contaminant Category | Potential Sources | Preventive Measures & Best Practices |
|---|---|---|
| Background Ions & Additives [1] | Mobile phase solvents and additives (e.g., formic acid), microbial growth in aqueous solvent reservoirs. | Use LC-MS grade solvents and additives. Dedicate solvent bottles to specific solvents/instruments and avoid detergent washing. Add ~10% organic solvent to aqueous phases to inhibit microbial growth [1]. |
| Sample Carryover [2] | Previous samples adsorbing to flow path surfaces (e.g., stainless steel, PEEK) and eluting later. | Incorporate sufficient wash steps. Consider using a metal-free, inert column with anti-fouling properties to minimize binding [2]. |
| Analyst Introduced [1] | Keratins, skin cells, lipids, and amino acids from bare hands during sample/solvent handling. | Always wear nitrile gloves when handling all instrument components, solvent bottles, and during sample preparation [1]. |
| Suppressing Contaminants [1] | Unknown compounds in plastic bottles of mobile phase additives (e.g., formic acid). | Source additives from reputable suppliers of LC-MS grade materials. When developing a new method, compare results using additives from different sources to check for interference [1]. |
Experimental Protocol: Contamination Prevention for Sensitive Analysis
Here is a general workflow for sample and solvent preparation designed to minimize contamination, which should be adapted for your specific leucocianidol protocol.
Key Considerations for this compound
Based on the search results, one study identified this compound as a phytochemical from *Terminalia arjuna* with potential insecticidal properties [3]. When working with such natural products, consider these specific points:
- Stability: The general guidance on using stabilizers and radical scavengers to protect sensitive compounds during processing and storage may be highly relevant [4]. You may need to experiment with different sample environments.
- Matrix Complexity: this compound extracted from plant material will come with a complex matrix of other compounds. The sample preparation and LC-MS method must be robust enough to separate your analyte from these potential interferents [1] [5].
References
- 1. Contaminants Everywhere! Tips and Tricks for Reducing ... [chromatographyonline.com]
- 2. How To Stop HPLC Corrosion, Protein Fouling, And ... [silcotek.com]
- 3. Terminalia Arjuna (Roxb.) Wight & amp; Arn [openbiotechnologyjournal.com]
- 4. Gamma irradiation of protein-based pharmaceutical products [patents.google.com]
- 5. An overview of sample preparation procedures for LC-MS ... [pubmed.ncbi.nlm.nih.gov]
A Quick Guide to Validation Parameters & Acceptance Criteria
The table below summarizes the core validation characteristics you need to establish, along with common challenges and solutions that are applicable to the analysis of natural products like leucocianidol [1] [2].
| Validation Parameter | What It Measures | Common Challenges | Typical Acceptance Criteria | Troubleshooting Tips |
|---|---|---|---|---|
| Specificity | Ability to measure analyte unequivocally in the presence of potential interferents (e.g., impurities, matrix) [2]. | Co-elution of this compound with other similar compounds from the extract or degradation products [2]. | Chromatographic peak purity; No interference at the retention time of this compound [2]. | Optimize mobile phase (pH, gradient) and column type; Use Diode Array Detector (DAD) for peak purity assessment [3]. |
| Accuracy | Closeness of measured value to true value [2]. | Incomplete extraction from a natural product matrix; Low recovery due to adsorption or degradation [4]. | Mean recovery of 80-120% for drug products at the target concentration [2]. | Conduct a standard addition (spiking) study; Ensure sample preparation method (e.g., extraction solvent, sonication time) is robust [4]. |
| Precision (Repeatability) | Closeness of agreement between a series of measurements under the same conditions [2]. | High variability in replicate sample preparations. | RSD ≤ 1% for assay of drug substance, though higher may be acceptable for complex matrices [2]. | Standardize and meticulously control all sample preparation steps; Ensure instrument performance (e.g., injector precision) [5]. |
| Linearity | Ability to obtain test results proportional to analyte concentration [2]. | Non-linear response at higher or lower concentrations due to detector saturation or insufficient sensitivity. | Correlation coefficient (R²) > 0.998 [6] [2]. | Prepare calibration standards from independent weighings/dilutions; Verify detector response is within linear dynamic range [3]. |
| Range | The interval between upper and lower concentration levels over which linearity, accuracy, and precision are demonstrated [2]. | Setting a range too narrow for the intended use (e.g., content uniformity testing). | The range must bracket the target test concentration(s) [2]. | Define range based on the method's intended use (e.g., 80-120% of label claim for assay). |
| Robustness | Capacity to remain unaffected by small, deliberate variations in method parameters [2]. | Method fails with a new batch of column, reagent, or on a different HPLC system. | System suitability criteria are met despite variations. | Test robustness during development by varying pH, column temperature, flow rate, and mobile phase composition [3]. |
Detailed Experimental Protocols for Key Tests
Here are detailed methodologies for two critical validation experiments.
Protocol for Accuracy by Recovery Study
This experiment assesses the accuracy of measuring this compound within its specific matrix (e.g., a plant extract or formulated product) [6] [2].
- Principle: A known amount of a this compound reference standard is added ("spiked") into a pre-analyzed sample matrix. The measured concentration is compared to the theoretical spiked concentration to calculate the percentage recovery.
- Materials:
- This compound reference standard (e.g., purity ≥98%)
- Placebo matrix (the product without the active ingredient) or blank plant extract
- Appropriate solvents (e.g., methanol, water with formic acid)
- Procedure:
- Prepare a sample of the placebo matrix as you would for the actual test.
- Spike the placebo with the this compound standard at three concentration levels (e.g., 80%, 100%, and 120% of the target test concentration). Prepare a minimum of three replicates at each level [2].
- Process and analyze these samples using the developed analytical method (e.g., HPLC).
- Calculate the recovery for each spike level using the formula:
- % Recovery = (Measured Concentration / Theoretical Concentration) × 100
- Acceptance Criteria: The mean recovery at each level should be within 80-120%, with a low relative standard deviation (RSD) between replicates [2].
Protocol for Precision (Repeatability)
This test evaluates the precision of the method under the same operating conditions over a short time [6] [2].
- Principle: Multiple samplings from a single, homogeneous sample preparation are analyzed to determine the variability of the results.
- Materials:
- A single, homogenous batch of sample containing this compound.
- Procedure:
- Prepare a minimum of six independent sample preparations from the same homogenous batch at 100% of the test concentration [2].
- Analyze all six preparations using the validated method.
- Calculate the mean, standard deviation, and Relative Standard Deviation (RSD) for the this compound content from the six results.
- Acceptance Criteria: The RSD should typically be ≤ 1% for a drug substance assay, though a slightly higher value may be justified for complex natural product matrices [2].
Workflow for Systematic Troubleshooting
When faced with a validation failure, a systematic approach is crucial. The following workflow diagrams outline a logical path to diagnose and resolve common specificity and precision issues.
Diagram: Troubleshooting Path for Specificity Challenges
Diagram: Troubleshooting Path for Precision Challenges
Frequently Asked Questions (FAQs)
Q1: What is the difference between a method verification and a full validation? A1: Method verification is performed when you are adopting an existing, compendial method (e.g., from a pharmacopoeia) to demonstrate that it works correctly in your laboratory with your specific instruments and analysts. Full validation is required when you are developing a new analytical method from scratch, for example, for a new substance like this compound that lacks a published method [1] [5].
Q2: How do I determine the Limit of Detection (LOD) and Limit of Quantification (LOQ)? A2: There are several accepted approaches. The signal-to-noise ratio method is common, where an LOD has a S/N of 3:1 and an LOQ of 10:1. Alternatively, you can base it on the standard deviation of the response and the slope of the calibration curve using the formulas: LOD = (3.3 × σ) / S and LOQ = (10 × σ) / S, where σ is the standard deviation of the response and S is the slope of the calibration curve [2].
Q3: Our method works perfectly in our lab but fails during transfer to a quality control (QC) lab. What could be wrong? A3: This often highlights a lack of demonstrated robustness or intermediate precision. The failure could be due to small, uncontrolled variations in equipment, columns, reagents from a different supplier, or environmental conditions. To prevent this, ensure you have conducted rigorous robustness testing during development and established clear system suitability tests (SST) that must be met before any analysis run [2] [7].
References
- 1. Bioanalytical method validation: An updated review - PMC [pmc.ncbi.nlm.nih.gov]
- 2. : are your Analytical ... | QbD Group Method Validation analytical [qbdgroup.com]
- 3. HPLC Method Development and Validation for ... [pharmtech.com]
- 4. Phytochemical analysis and anticancer activity of the ... [degruyterbrill.com]
- 5. Analytical Method Validation: Back to Basics, Part I [chromatographyonline.com]
- 6. Validation of the High-Performance Liquid ... [pmc.ncbi.nlm.nih.gov]
- 7. Automation of the Chromatographic Analytical Method ... [chromatographyonline.com]
Leucocianidol stability in experimental conditions
Leucocianidol Technical Data Sheet
For any experimental work, having key physicochemical data on hand is essential. The table below summarizes the available information for this compound.
| Property | Value / Description | Source / Reference |
|---|---|---|
| CAS Number | 480-17-1 (Other IDs: 93527-39-0, 69256-15-1 for (+)-form) | [1] [2] |
| Molecular Formula | C15H14O7 | [1] [2] [3] |
| Molecular Weight | 306.27 g/mol | [1] [2] |
| Appearance | White to off-white solid powder | [1] |
| Purity | ≥98% (as available from suppliers) | [1] |
| Solubility (DMSO) | ~100 mg/mL (~326.51 mM) | [1] |
| Recommended Storage (Powder) | -20°C for long-term (3 years); 4°C for short-term (2 years) | [1] |
| Recommended Storage (Solution) | -80°C for long-term (6 months); -20°C for short-term (1 month) | [1] |
Experimental Protocol & Formulation Guide
Since a detailed stability-indicating method for this compound was not found, here is a general workflow for assessing stability, incorporating guidance from general stability principles for drug development [4].
Stock Solution Preparation
This protocol is adapted from supplier recommendations and general laboratory practices [1].
- Calculation: Calculate the required mass of this compound powder to achieve your desired stock concentration, using the molecular weight of 306.27 g/mol.
- Weighing: Accurately weigh the powder using a calibrated analytical balance.
- Dissolution: Transfer the powder to a volumetric flask and add the chosen solvent (e.g., DMSO) to volume. Gently vortex or sonicate to ensure complete dissolution.
- Aliquoting: Immediately aliquot the stock solution into small, single-use vials to minimize freeze-thaw cycles and exposure to air.
- Storage: Store the aliquots according to the recommended conditions in the Technical Data Sheet above.
Preparation of In Vivo Formulations
For animal studies, the supplier provides two sample formulations. Note: These are example protocols and should be validated for your specific application [1].
- Formulation 1 (10% DMSO, 40% PEG300, 5% Tween 80, 45% Saline)
- Sequentially add 100 µL of a 25.0 mg/mL DMSO stock solution to 400 µL PEG300 and mix evenly.
- Add 50 µL Tween-80 and mix evenly.
- Add 450 µL of normal saline (0.9% sodium chloride in ddH₂O) to adjust the volume to 1 mL.
- Formulation 2 (10% DMSO, 90% 20% SBE-β-CD in Saline)
- Add 100 µL of a 25.0 mg/mL DMSO stock solution to 900 µL of a 20% SBE-β-CD solution in saline and mix evenly.
- Preparation of 20% SBE-β-CD in Saline: Dissolve 2 g of SBE-β-CD in 10 mL of saline. This solution is stable for 1 week at 4°C.
Frequently Asked Questions & Troubleshooting
Q1: What is the best way to store this compound powder and solutions to ensure stability?
- A: For long-term stability (up to 3 years), store the powder at -20°C. For short-term storage (up to 2 years), 4°C is acceptable [1]. For stock solutions, prepare aliquots and store them at -80°C for up to 6 months. Avoid repeated freezing and thawing.
Q2: My this compound solution has changed color. What does this indicate?
- A: A change in color (e.g., from clear/colorless to yellow or brown) is a strong physical indicator of chemical degradation. This compound, like other flavonoids and polyphenols, is susceptible to oxidation. You should discard the solution and prepare a fresh batch. For future work, ensure solutions are protected from light and oxygen, and consider using an antioxidant in your buffer if compatible with your assay.
Q3: I am observing low solubility or precipitation in my aqueous buffers. How can I resolve this?
- A: this compound has high solubility in DMSO but limited solubility in water. Follow these steps:
- Confirm Preparation Order: Always add the DMSO stock solution to the aqueous components slowly and with constant mixing.
- Use Co-solvents: Employ the recommended formulation guides using PEG300, Tween-80, or SBE-β-CD to enhance solubility in aqueous systems [1].
- Check pH: The compound's solubility can be pH-dependent. Slight adjustments to the buffer pH may improve solubility, but ensure this does not compromise stability.
The following troubleshooting guide visualizes a logical approach to common lab issues.
Recommendations for Further Research
To build a more complete stability profile, you may need to generate your own data.
- Develop a Stability-Indicating Method: The most critical step is to develop and validate a specific HPLC or LC-MS method for this compound. This method should be able to separate the parent compound from its degradation products.
- Design a Formal Stability Study: Place samples of this compound under controlled stress conditions (e.g., elevated temperature, humidity, oxidative, and photolytic stress) as per ICH guidelines [5] [4]. Analyze these samples at set time points using your stability-indicating method to identify degradation products and determine the compound's intrinsic stability.
References
- 1. | anti-ulcerogenic | treatment of hemorroids | InvivoChem this compound [invivochem.com]
- 2. KEGG COMPOUND: C05906 [genome.jp]
- 3. Showing metabocard for Leucocyanidin (HMDB0303660) [hmdb.ca]
- 4. The importance of stability programs in early clinical drug ... [iconplc.com]
- 5. Q1 Stability Testing of Drug Substances and Drug Products ... [federalregister.gov]
Leucocianidol degradation products identification
Leucocianidol Basic Information
The table below summarizes the core chemical and physical properties of this compound (CAS No. 480-17-1) from the search results [1].
| Property | Value / Description |
|---|---|
| CAS Number | 480-17-1 |
| Chemical Name | This compound, Leucocyanidin polymer |
| Molecular Formula | C₁₅H₁₄O₇ |
| Molecular Weight | 306.27 g/mol |
| Boiling Point | 641.5 °C at 760 mmHg |
| Flash Point | 341.8 °C |
| Density | 1.709 g/cm³ |
| Usage | Dietary supplement, therapeutic agent, natural preservative, skincare ingredient [1]. |
Proposed Workflow for Degradation Product Identification
Based on standard laboratory practice for similar phytochemicals, the identification of degradation products typically follows the workflow below. You can use this as a template for developing your own detailed protocols.
Frequently Asked Questions
Here are some anticipated FAQs that can be included in your support center.
Q1: What are the major challenges in identifying this compound degradation products?
- Polymer Complexity: As a polymer, this compound can break down into multiple monomeric and oligomeric units, making separation and identification complex [1].
- Structural Similarity: Degradation products, such as flavan-3-ol monomers like catechin or epicatechin, may have very similar structures, requiring high-resolution analytical techniques for distinction [1].
Q2: Which analytical techniques are most suitable for this analysis?
- Separation: High-Performance Liquid Chromatography (HPLC) or Ultra-Performance Liquid Chromatography (UPLC) are recommended for separating complex mixtures.
- Identification: Hyphenated techniques like LC-MS/MS (Liquid Chromatography-Tandem Mass Spectrometry) and NMR (Nuclear Magnetic Resonance) spectroscopy are critical. NMR is particularly powerful for determining the detailed structure of isolated compounds, as demonstrated in studies of related procyanidins [1].
Q3: Are there any known safety concerns when handling this compound? The search results did not list any specific hazard codes or statements for this compound [1]. However, it is always essential to consult the Safety Data Sheet (SDS) from your chemical supplier and follow general laboratory safety protocols, including wearing appropriate personal protective equipment (PPE).
Troubleshooting Guide
This guide addresses common experimental problems.
| Problem | Possible Cause | Suggested Solution |
|---|
| Poor chromatographic separation | Complex mixture of degradation products with similar polarity. | Optimize the HPLC/UPLC gradient method. Use columns with different stationary phases (e.g., C18, phenyl). | | Low signal-to-noise in MS detection | Low concentration of degradation products; ion suppression. | Pre-concentrate the sample; use electrospray ionization (ESI) in both positive and negative modes. | | Cannot differentiate between isomers | MS alone cannot distinguish between molecules with the same mass. | Couple LC-MS with NMR analysis. Compare retention times and fragmentation patterns with available standards. |
Knowledge Gaps and Further Research
The existing search results confirm this compound's biological relevance [2] [3] [4] but lack specific degradation data. To fill these gaps, I suggest:
- Search Specialized Databases: Probe SciFinder, Reaxys, or PubMed specifically for "Leucocyanidin stability," "Leucocyanidin degradation," and "proanthocyanidin analysis."
- Review Broader Literature: Look into analytical papers on related compounds like procyanidins or condensed tannins, as their degradation pathways can offer valuable methodological insights [1].
References
Leucocianidol vs catechin biological activity comparison
Chemical Properties and Bioactivity at a Glance
The table below summarizes the core characteristics and reported bioactivities of leucocianidol and catechin.
| Feature | This compound (Leucoanthocyanidin) | Catechin |
|---|---|---|
| IUPAC Name | (2R,3S)-2-(3,4-dihydroxyphenyl)-3,4-dihydro-2H-chromene-3,5,7-triol [1] | Not explicitly listed in results; multiple isomers exist (e.g., (+)-Catechin, (-)-Epicatechin) [2]. |
| PubChem CID | 440833 [3] | 9064 (for Cianidanol, a synonym) [3] |
| Molecular Formula | C15H14O7 [3] | C15H14O6 (for Cianidanol) [3] |
| Molecular Weight | 306.29 g/mol [3] | 290.29 g/mol (for Cianidanol) [3] |
| Drug Likeness (Oral Bioavailability) | 30.84% [3] | 54.83% (for Cianidanol) [3] |
| Key Reported Biological Activities | Antiviral (Herpes) [4], potential for Hepatocellular Carcinoma (HCC) [3] | Antioxidant [5] [6], Anti-inflammatory [5], Antimicrobial [6] [5], potential for Hepatocellular Carcinoma (HCC) [3], Cardioprotective [7] |
| Primary Molecular Targets (from studies) | Herpesvirus Thymidine Kinase & Protease [4], Hub genes in HCC (e.g., STAT3, MAPK3) [3] | Hub genes in HCC (e.g., STAT3, MAPK3) [3], Bacterial cell membranes & DNA [6], Endothelial nitric oxide signaling [7] |
Quantitative Experimental Data Comparison
This table consolidates key experimental findings, highlighting the different focuses of research for each compound.
| Assay / Parameter | This compound | Catechin / (+)-Catechin gallate |
|---|---|---|
| Binding Affinity (Molecular Docking) | Strong binding to Herpes Thymidine Kinase [4] | -8.9 kcal/mol with STAT3 [3] |
| Molecular Docking Score | Not quantitatively specified [4] | -8.9 kcal/mol with SRC [3] |
| Cell Viability Assay (IC50) | Not reported in search results | -10.2 kcal/mol with MAPK3 [3] |
| Cell Viability Assay (IC50) | Not reported in search results | Significant reduction in HepG2 (liver cancer) cells [3] |
| Antibacterial Activity (MIC) | Not reported in search results | IC50 10-14 μg/mL (as Cat-HPβCD complex) in MCF-7 breast cancer cells [8] |
| Antioxidant Activity | Not reported in search results | 1-2 mg/mL (against E. coli) [6] |
| Toxicity (In silico) | Minimal toxicity risks, favorable pharmacokinetics [4] | Increased with concentration (0.5 to 32 μg/mL) [5] |
| Considered safe by FDA; favorable computational toxicity profile [6] |
Detailed Experimental Protocols
For researchers looking to replicate or understand the basis of these findings, here are the methodologies from key studies.
Computational Screening of this compound against Herpes Virus
This study used a suite of in silico tools to evaluate this compound's potential.
- Molecular Docking: The interaction between this compound and two herpesvirus enzymes (Thymidine Kinase and Type II Protease) was simulated to predict binding affinity and pose [4].
- ADME/Toxicity Prediction: Computational models were used to analyze the Absorption, Distribution, Metabolism, and Excretion properties, along with potential toxicity, showing high gastrointestinal absorption and minimal toxicity risks [4].
- Density Functional Theory (DFT): This quantum mechanical method was employed to calculate the compound's electronic properties and structural stability, providing insights into its reactivity [4].
- Molecular Dynamics (MD) Simulations: The stability of the this compound-protein complexes was assessed under simulated physiological conditions (e.g., 310 K, 1 atm) for 100 nanoseconds, revealing stable interactions with minimal fluctuations [4].
Network Pharmacology & Molecular Docking for HCC
This approach identified multi-target mechanisms against Hepatocellular Carcinoma (HCC) for compounds from Bergenia species, including this compound and (+)-catechin gallate (a catechin derivative).
- Compound Screening: Phytochemicals were filtered based on oral bioavailability (OB > 30%) and drug-likeness (DL > 0.18) [3].
- Target Prediction: Gene targets for the compounds and for HCC were retrieved from SwissTargetPrediction, STITCH, GeneCards, and DisGeNET databases. Overlapping genes were considered potential targets [3].
- Network Analysis: Protein-Protein Interaction (PPI) networks were built using STRING and analyzed with Cytoscape to identify hub genes like STAT3, MAPK3, and SRC [3].
- Validation via Docking: Molecular docking was performed to confirm the binding of the top compounds (+)-catechin gallate and β-sitosterol to the hub gene proteins [3].
- In vitro Validation: The cytotoxic activity of the top compounds was tested on HepG2 liver cancer cells using a cell viability assay (e.g., MTT) after 24 hours of treatment [3].
This workflow for network pharmacology and docking is summarized in the diagram below:
Antimicrobial and Therapeutic Potential
Research into the applications of these compounds reveals distinct pathways.
- Catechin as an Antimicrobial Agent: Catechins exhibit a broad spectrum of biological activities. Their antimicrobial mechanism is well-studied, including disruption of bacterial cell walls and membranes, suppression of virulence factors, and induction of DNA damage through oxidative stress [6]. They are effective against Gram-positive bacteria like Staphylococcus aureus and have synergism with antibiotics [5] [6].
- This compound's Targeted Antiviral Action: In contrast, current research on this compound points to a more specialized, high-potential application as an antiviral agent, specifically against the herpes virus, by targeting essential viral enzymes [4]. Its activity against HCC was identified as part of a multi-compound study, but dedicated research is still needed [3].
Conclusion for Research and Development
- Catechin is a more broadly studied compound with multi-faceted applications, including antioxidant, anti-inflammatory, antimicrobial, and anticancer activities. Its higher oral bioavailability and favorable safety profile make it a strong candidate for nutraceutical and cosmetic development [3] [5] [6].
- This compound presents as a highly specific lead compound for anti-herpetic drug development. Its strong binding to viral targets and favorable computational ADMET profile are promising, but it requires further in vitro and in vivo validation to confirm its efficacy and safety [4].
The choice between them depends entirely on the therapeutic target. For antimicrobial or general antioxidant formulations, catechin has a stronger evidence base. For targeted antiviral therapy, particularly against herpes, this compound represents an exciting, though less validated, candidate.
References
- 1. Comparative analysis of the reactivity of anthocyanidins ... [pmc.ncbi.nlm.nih.gov]
- 2. Flavanols from Nature: A Phytochemistry and Biological ... [mdpi.com]
- 3. Underlying Mechanisms of Bergenia spp. to Treat ... [pmc.ncbi.nlm.nih.gov]
- 4. 7.95 [jetir.org]
- 5. Comparative study of anti-inflammatory, antioxidant and ... [sciencedirect.com]
- 6. Catechins as Antimicrobial Agents and Their Contribution ... [mdpi.com]
- 7. Natural Dietary Polyphenolic Compounds Cause ... [sciencedirect.com]
- 8. Enhancement of the Biological Activity of Catechin from ... [espublisher.com]
Leucocianidol vs cyanidin antioxidant capacity assessment
Chemical Profile and Relationship
First, it's helpful to understand the fundamental relationship between these two compounds, as this informs their antioxidant behavior.
| Feature | Leucocianidol (Leucocyanidin) | Cyanidin-3-Glucoside (C3G) |
|---|---|---|
| Chemical Classification | Flavan-3,4-diol (Leucoanthocyanidin) [1] | Anthocyanin (3-O-glucoside of cyanidin) [2] [3] |
| Core Structure | Colorless flavan derivative with two hydroxyl groups on the C-ring [1] | Glycosylated anthocyanidin with a flavylium cation core [2] |
| Relationship | A potential precursor in the biosynthesis of anthocyanins like C3G [1]. | A colored, glycosylated pigment found in mature plant tissues [2] [4]. |
This structural relationship is key. This compound's simpler, colorless structure suggests its antioxidant mechanism and capacity will differ from its more complex, stabilized derivative, C3G.
Antioxidant Capacity of Cyanidin-3-Glucoside (C3G)
The antioxidant activity of anthocyanins like C3G is well-documented and depends on its structural features.
Structural Determinants of Activity
C3G's effectiveness as an antioxidant is attributed to several key structural characteristics [2]:
- o-Dihydroxyl group on the B-ring: This catechol structure allows for the formation of a stable semiquinone radical after scavenging other radicals, which is a critical feature for potent antioxidant activity.
- Conjugated double bond system: The C1=C2 and C3=C4 double bonds in conjugation facilitate electron delocalization across the molecule, enhancing its ability to stabilize unpaired electrons.
While glycosylation (the attachment of a sugar molecule, in this case, glucose) generally lowers the antioxidant activity compared to the aglycone (cyanidin) due to steric hindrance, it significantly increases the compound's stability and water solubility [2].
Key Experimental Data and Protocols
The table below summarizes common experimental protocols and typical findings for C3G's antioxidant capacity.
| Assay Type | Mechanism | Key Protocol Details | Exemplary Finding for C3G |
|---|
| FRAP (Ferric Reducing Antioxidant Power) [5] [6] | Single-Electron Transfer (SET) | Incubate sample with Fe³⁺-TPTZ complex at low pH; measure absorbance increase at 593 nm as Fe³⁺ is reduced to Fe²⁺ [5]. | Used to optimize extraction of cyanidin-rich extracts from red araça pomace (85°C, 60 min) [4]. | | DPPH (Diphenyl-1-Picrylhydrazyl) [5] | Mixed SET / Hydrogen Atom Transfer (HAT) | Mix sample with methanolic DPPH• radical solution; measure decrease in absorbance at 515 nm as radical is scavenged [5]. | Applied alongside FRAP to evaluate cyanidin-rich antioxidant extracts [4]. | | CUPRAC (Cupric Ion Reducing Antioxidant Capacity) [6] | Single-Electron Transfer (SET) | Mix sample with Cu²⁺ and neocuproine; measure absorbance increase at 450 nm as Cu²⁺ is reduced to Cu⁺ [6]. | A high-throughput, microplate-based version was validated for complex mixtures; less susceptible to pigment interference than DPPH [6]. | | Interaction Studies (e.g., with Proteins) | Non-covalent / Covalent Binding | Multi-spectroscopy (fluorescence quenching), thermodynamic analysis, particle size/zeta potential measurement [3]. | Forms non-covalent complexes with Corbicula fluminea protein (CFP); shows antagonistic antioxidant effect at high C3G concentrations but synergistic effects in covalent conjugates [3]. |
Research Roadmap for this compound
To fill the gap in the literature for this compound, you could design a study using the following approach:
- Standardized Extraction: Use acidified aqueous-organic solvents (e.g., methanol/water) to extract this compound from a known source, such as White Oak bark or grape seeds [1], optimizing temperature and time as done for C3G [4].
- Parallel Antioxidant Profiling: Subject both this compound and C3G extracts to the same battery of assays (e.g., DPPH, FRAP, CUPRAC, ORAC) under identical experimental conditions to generate directly comparable data [2] [5].
- Advanced Mechanistic Studies:
- Cell-Based Assays: Move beyond chemical assays to evaluate the protective effects of both compounds against oxidative stress in cell cultures, measuring biomarkers like SOD, glutathione peroxidase, and oxidative DNA damage markers [7].
- Interaction Studies: Investigate how this compound interacts with other biomolecules, similar to the C3G-CFP study, to see if its activity is enhanced or antagonized in complex systems [3].
The following diagram outlines this proposed experimental workflow:
References
- 1. Leucocyanidin [en.wikipedia.org]
- 2. Antioxidant Activity of Anthocyanins and Anthocyanidins [mdpi.com]
- 3. Interactions Between Cyanidin-3-Glucoside and Corbicula ... [pmc.ncbi.nlm.nih.gov]
- 4. Novel strategies for valorizing red araça pomace: Cyanidin ... [sciencedirect.com]
- 5. State of the Art of Anthocyanins: Antioxidant Activity, ... [pmc.ncbi.nlm.nih.gov]
- 6. Critical Evaluation and Validation of a High-Throughput ... [mdpi.com]
- 7. How to assess antioxidant activity? Advances, limitations, and ... [pmc.ncbi.nlm.nih.gov]
Leucocianidol network pharmacology validation studies
Leucocianidol in a Network Pharmacology Study
The table below summarizes the role and key findings for this compound from a 2023 network pharmacology and molecular docking study aimed at exploring the mechanism of Bergenia species in treating HCC [1] [2].
| Aspect | Findings for this compound |
|---|---|
| Source | One of four active phytochemicals selected from several Bergenia species (including B. ciliata and B. purpurascens) [1] [2]. |
| Screening Criteria | Oral Bioavailability (OB) > 30%; Drug-Likeness (DL) > 0.18 [1] [2]. |
| Pharmacokinetic Properties | OB: 30.84%; DL: 0.27; Molecular Weight: 306.29 g/mol [1] [2]. |
| Network Topology (Degree) | Degree = 41, indicating interactions with 41 potential gene targets in the compound-target network [1] [2]. |
| Experimental Validation | The study did not select this compound for further experimental validation (e.g., molecular docking or cell viability assays). Subsequent analysis focused on (+)-catechin gallate and β-sitosterol [1] [2]. |
Detailed Experimental Workflow
The study followed a common and rigorous network pharmacology workflow to identify and preliminarily validate the active compounds. The diagram below outlines the key steps, highlighting where this compound was included and where it was excluded from further analysis.
Based on this workflow, the following are the key experimental protocols cited in the study [1] [2]:
- Bioactive Compound Screening: Active compounds from Bergenia species were screened from database and literature-mined libraries using Oral Bioavailability (OB ≥ 30%) and Drug-likeness (DL ≥ 0.18) as key ADME (Absorption, Distribution, Metabolism, Excretion) criteria.
- Target and Disease Gene Prediction: Putative targets of the bioactive compounds were predicted using the SwissTargetPrediction and STITCH databases. HCC-related genes were collected from the GeneCards and DisGeNET databases.
- Network Construction and Analysis: A compound-target network was built using Cytoscape software. The Network Analyzer Cytoscape plug-in calculated topological parameters (e.g., Degree) to identify influential compounds and targets.
- Protein-Protein Interaction (PPI) Analysis: The common targets were input into the STRING database to build a PPI network, specifying Homo sapiens and a high confidence score (0.700). The resulting network was analyzed with Cytoscape.
- Enrichment Analysis: Gene Ontology (GO) and Kyoto Encyclopedia of Genes and Genomes (KEGG) pathway enrichment analyses were performed on the 98 common targets using R software and the ClusterProfiler package.
- Experimental Validation: The top hub genes (STAT3, MAPK3, SRC) were validated via molecular docking using AutoDock software. The top compounds, (+)-catechin gallate and β-sitosterol, were further tested in in vitro cell viability assays on HepG2 cells (human liver cancer cell line) using a CCK-8 assay after 24 hours of treatment.
Interpretation and Insights for Researchers
Based on the available data, here are some key points for your research:
- Promising Multi-Target Profile: this compound's high degree value (41) in the compound-target network suggests it has a multi-targeting mechanism of action, which is a key focus of network pharmacology and desirable for treating complex diseases like cancer [1] [2].
- Lack of Direct Comparative Data: This study does not offer a head-to-head comparison between this compound and other similar compounds. Its potential was noted computationally but not pursued experimentally in this work.
- Focus on Other Compounds: In this particular study, (+)-catechin gallate (which showed the highest degree value of 47) and β-sitosterol were prioritized for further validation. These compounds demonstrated significant binding scores in molecular docking and reduced cell viability in experiments [1] [2].
References
Chemical Structure and Predicted Reactivity of Leucocyanidin
Leucocyanidin is a leucoanthocyanidin, a class of flavonoids that are intermediates in anthocyanidin biosynthesis [1]. Its chemical structure features two benzene rings (A and B) and a heterocyclic ring (C), with hydroxyl groups at the R1 position [1].
A 2023 comparative computational study used Density Functional Theory (DFT) to analyze the electronic properties and reactivity of various flavonoids, including Leucocyanidin. The table below summarizes key molecular descriptors derived from this analysis, which are crucial for predicting a compound's potential bioactivity [1].
| Flavonoid | Flavonoid Class | HOMO-LUMO Gap (eV) | Global Electrophilicity Index (ω) | Key Reactivity Finding |
|---|---|---|---|---|
| Leucocyanidin | Leucoanthocyanidin | 5.03 | 1.37 | Highly reactive in electrophilic reactions |
| Quercetin | Flavonol | 4.71 | 1.41 | One of the most reactive flavonoids in electrophilic reactions |
| Kaempferol | Flavonol | 4.90 | 1.39 | High reactivity, similar to Quercetin |
| Delphinidin | Anthocyanidin | 4.18 | 1.79 | Highly reactive in nucleophilic reactions |
| (+)-Catechin | - | 5.25 | 1.28 | Lower chemical reactivity |
Table Notes: A lower HOMO-LUMO gap generally indicates higher chemical reactivity. The Global Electrophilicity Index measures a molecule's propensity to act as an electrophile (an electron-seeking species). Higher values suggest a greater capacity to undergo covalent interactions with biological nucleophiles, such as proteins or DNA, which can be a mechanism for cytotoxicity [1].
The study concluded that Leucocyanidin and Quercetin are among the most reactive flavonoids in electrophilic reactions [1]. This high reactivity, particularly of the hydroxyl groups on its ring A, suggests a strong potential for Leucocyanidin to interact with cellular targets.
Cytotoxicity and Anticancer Mechanisms of Flavonoids
While quantitative cytotoxicity data (e.g., IC₅₀) for Leucocyanidin against specific cancer cell lines is lacking in the search results, the reactivity profile is a strong indicator of its potential. For context, the following experimental data for other flavonoids illustrates the established cytotoxic effects within this compound class.
| Flavonoid | Flavonoid Class | Experimental Model | Key Cytotoxic/Anticancer Finding | Study |
|---|---|---|---|---|
| Baicalein, Myricetin | Flavone, Flavonol | Human chronic myeloid leukemia K562 cells | Specific cytotoxic effect on leukemia cells with less effect on normal blood cells | [2] |
| 5,6-dihydroxyflavone, Apigenin, Luteolin, Genistein | Flavone, Isoflavone | Human melanoma cells (A375, C32) | Reduced cell viability by activating intrinsic (caspase-9) and extrinsic (caspase-8) apoptosis pathways | [3] |
| Baicalein, Genistein, Scutellarin | Flavone, Isoflavone | Various leukemia cells (HL-60, NB4, etc.) | Induced apoptosis and cell cycle arrest by dysregulating proteins like CDK4, cyclin D1, and p-ERK | [4] |
| Apigenin, Quercetin | Flavone, Flavonol | Human breast cancer cells (MCF-7, MDA-MB-231) | High doses (>20 µM) induced oxidative stress, mitochondrial dysfunction, apoptosis, and cell cycle arrest | [5] |
| Various Flavonoids | Multiple | Human colon cancer cells (Caco-2, HT-29) | Antiproliferative activity for over 30 flavonoids; Baicalein and Myricetin also induced apoptosis in intestinal cell lines | [6] |
Core Experimental Protocols for Cytotoxicity Assessment
The following are standard experimental workflows cited in the research for evaluating flavonoid cytotoxicity. You can use these protocols to design your own experiments for Leucocyanidin.
Key Assay Details:
- MTT Assay: This colorimetric assay measures the reduction of yellow MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) to purple formazan by metabolically active cells [7]. The signal is proportional to the number of viable cells. The formazan product must be solubilized (e.g., with DMSO or SDS) before recording absorbance at 570 nm [7].
- Apoptosis Detection: Activation of caspases (e.g., caspase-3, -8, -9) is a central marker for apoptosis [3] [4] [6]. This can be measured using commercial kits that detect cleavage of specific substrates.
- Oxidative Stress Markers: Common metrics include:
Conclusion and Research Implications
Based on the gathered data, here is a comparative summary:
- Leucocyanidin's Profile: Computational analysis positions Leucocyanidin as a highly electrophilic molecule, suggesting significant potential for biological activity through interactions with cellular nucleophiles [1]. Its reactivity is comparable to established cytotoxic flavonoids like Quercetin.
- Established Flavonoids: As the tables show, many flavonoids, including Baicalein, Myricetin, Quercetin, and Apigenin, have demonstrated potent and specific cytotoxicity across various cancer cell lines through mechanisms like apoptosis induction, cell cycle arrest, and modulation of oxidative stress [2] [3] [4].
The primary gap is the lack of direct, experimental cytotoxicity data for Leucocyanidin alongside these other compounds. Therefore, its comparative performance remains a key area for future research. The provided experimental protocols offer a roadmap for generating this essential data to determine where Leucocyanidin stands among cytotoxic flavonoids.
References
- 1. Comparative analysis of the reactivity of anthocyanidins ... [pmc.ncbi.nlm.nih.gov]
- 2. Effect of Cytotoxic on Leukemia Cells and Normal Cells of... Flavonoids [link.springer.com]
- 3. Using Flavonoid Substitution Status to Predict Anticancer ... [pmc.ncbi.nlm.nih.gov]
- 4. Signaling Proteins and Pathways Affected by Flavonoids ... [pubmed.ncbi.nlm.nih.gov]
- 5. The Biphasic Effect of Flavonoids on Oxidative Stress and ... [mdpi.com]
- 6. analysis of the effects of Comparative on proliferation... flavonoids [pubmed.ncbi.nlm.nih.gov]
- 7. Cell Viability Assays - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
Leucocianidol drug-likeness properties vs synthetic compounds
Drug-Likeness Profile of Leucocianidol
The table below summarizes the key quantitative drug-likeness properties of this compound as reported in a 2023 network pharmacology study [1].
| Property | Value for this compound | Common "Drug-Like" Thresholds [2] |
|---|---|---|
| Molecular Formula | C15H14O7 [1] | - |
| Molecular Weight | 306.29 g/mol [1] | 160 - 480 g/mol |
| Oral Bioavailability (OB) | 30.84% [1] | Typically >30% |
| Drug Likeness (DL) | 0.27 [1] | Typically >0.18 |
This compound in Modern Research Context
The provided data comes from a study that used network pharmacology, a method that reflects a shift from the traditional "one drug, one target" model to a more holistic "multi-compound, multi-target" approach [1]. In this study, this compound was identified as one of several phytochemicals from Bergenia species with potential against hepatocellular carcinoma (HCC) [1].
- Research Workflow: The study selected this compound based on its OB and DL, predicted its protein targets, and overlapped them with known HCC-related genes. The compound was part of a network predicted to interact with 98 common targets [1].
- Experimental Validation: It is important to note that while the network analysis suggested a role for this compound, it was the compounds (+)-catechin gallate and β-sitosterol that were selected for and confirmed to have anti-HCC activity in subsequent in vitro experiments on HepG2 cells [1].
Evolving Standards in Molecular Design
The concept of "drug-likeness" is evolving beyond simple rules like Lipinski's Rule of Five. Today's drug discovery, especially with the integration of Generative AI (GenAI), defines a promising molecule through a more holistic lens [3].
The workflow for modern generative AI models in drug discovery actively incorporates these considerations to ensure generated molecules are not just novel, but also practical and therapeutically aligned [3] [4]. These models are increasingly designed to integrate with active learning cycles, where initial predictions are iteratively refined using feedback from both computational oracles (e.g., for synthetic accessibility or binding affinity) and, crucially, human experts [3] [4].
How to Approach a Deeper Comparison
For a researcher, making an objective comparison involves more than just tabulating simple properties. Here are some suggestions for a more rigorous analysis:
- Benchmark Against Target Comparators: A powerful method is to compare this compound's properties not against generic rules, but against the known active compounds for your specific target of interest. A 2021 study in the Journal of Medicinal Chemistry found that 96% of drugs had better Ligand Efficiency (LE) or Lipophilic Ligand Efficiency (LLE) than the median of their target's comparator compounds [5].
- Evaluate Within a Multi-Target Framework: Given that this compound was identified via network pharmacology, its true value may lie in polypharmacology. Its "performance" should be evaluated based on the strength of its network and the critical pathways it is predicted to modulate [1].
- Prioritize Synthetic Feasibility: For any molecule, its potential is moot if it cannot be synthesized. Modern tools like SynLlama are now fine-tuned to only propose molecules with plausible synthesis pathways from available building blocks, a key advance in generative AI [6].
I hope this structured overview provides a solid foundation for your comparative guide. The field is rapidly moving towards integrated AI and human expert approaches to define the next generation of therapeutic compounds.
References
- 1. Underlying Mechanisms of Bergenia spp. to Treat ... [pmc.ncbi.nlm.nih.gov]
- 2. Druglikeness [en.wikipedia.org]
- 3. In Search of Beautiful Molecules: A Perspective on Generative ... [pmc.ncbi.nlm.nih.gov]
- 4. Optimizing drug design by merging generative AI with a ... [nature.com]
- 5. Target-based evaluation of 'drug-like' properties and ligand ... [pmc.ncbi.nlm.nih.gov]
- 6. SynLlama: Generating Synthesizable Molecules and Their ... [arxiv.org]
Leucocianidol toxicity profile ADMET evaluation
Available Data on Leucocianidol
The table below summarizes the key information found for this compound, also known as leucocyanidol [1].
| Property | Value / Description |
|---|---|
| IUPAC Name | (2R,3S)-2-(3,4-dihydroxyphenyl)-3,4-dihydro-2H-chromene-3,5,7-triol |
| Molecular Formula | C15H14O7 [1] |
| Molecular Weight | 306.29 g/mol [1] |
| Oral Bioavailability (OB) | 30.84% [1] |
| Drug-Likeness (DL) | 0.27 [1] |
| Key Finding | Showed interactions with 41 gene targets related to Hepatocellular Carcinoma (HCC) [1] |
Research Context and Methodologies
The data for this compound was generated through a network pharmacology and molecular docking approach, a common method for the initial prediction of a compound's polypharmacological effects [1] [2].
- Compound Screening: The researchers selected this compound from a library based on predefined pharmacokinetic criteria: Oral Bioavailability (OB) ≥ 30% and Drug-Likeness (DL) ≥ 0.18 [1]. This filter helps prioritize compounds with a higher potential to become successful drugs.
- Target Prediction and Network Analysis: Potential protein targets of this compound were predicted using databases like SwissTargetPrediction and STITCH. These targets were cross-referenced with genes known to be associated with a specific disease (hepatocellular carcinoma) to identify common targets. A protein-protein interaction (PPI) network was then constructed using the STRING database to understand the relationships between these targets [1].
- Topological Analysis: Using Cytoscape software, researchers calculated network parameters to identify "hub" targets. In this study, this compound was found to interact with 41 targets, suggesting a multi-target mechanism of action [1].
The following diagram illustrates this multi-step workflow for predicting a compound's therapeutic potential.
Current Limitations and Research Gaps
Based on the search results, a full ADMET evaluation for this compound is not yet possible. The key limitations are:
- Lack of Comprehensive ADMET Data: The available data is focused on target interactions and drug-likeness, covering only early aspects of Absorption and very limited Distribution. Crucial experimental data on Metabolism, Excretion, and Toxicity (MET) is missing [1] [3].
- No Direct Comparative Data: The search results do not provide experimental data comparing this compound's ADMET profile side-by-side with other similar compounds, which is a core requirement for your guide.
- Focus on Efficacy, Not Safety: The identified study primarily investigates the compound's potential therapeutic mechanisms against liver cancer, not its full toxicity profile [1].
Suggested Path Forward
To build a complete ADMET comparison guide, you may need to explore the following:
- Specialized ADMET Prediction Tools: Utilize in-silico platforms like admetSAR or ADMETLab to generate predictive data for various toxicity endpoints (e.g., Ames mutagenicity, hERG inhibition) [4] [3].
- Broaden Literature Search: Look for primary research articles specifically on this compound's toxicology or the toxicology of very structurally similar flavonoids.
- Consult Experimental Databases: Search chemical databases such as PubChem for any available bioassay results related to this compound's toxicity.
References
- 1. Underlying Mechanisms of Bergenia spp. to Treat ... [pmc.ncbi.nlm.nih.gov]
- 2. Exploring active ingredients and function mechanisms of ... [pmc.ncbi.nlm.nih.gov]
- 3. -score – a comprehensive scoring function for evaluation of... ADMET [pubs.rsc.org]
- 4. - ADMET Chemistry Glossary Predictions Computational [deeporigin.com]
Leucocianidol efficacy comparison in different cell lines
Anticancer Profiles of Selected Natural Compounds
| Compound / Extract | Plant Source | Tested Cell Lines (Cancer Type) | Key Efficacy Findings | Proposed Mechanisms | Experimental Methods Cited |
|---|---|---|---|---|---|
| Cranberry Extract [1] | Vaccinium macrocarpon (Cranberry) | KB (Oral), L929 (Normal Fibroblast) | IC50 of 3.564 μg/ml in KB cells; higher viability in normal fibroblasts [1]. | Antiproliferative effect [1]. | MTT viability assay [1]. |
| P. dulce Seed Extract [2] | Pithecellobium dulce | LoVo (Colorectal), MCF7 (Breast), A549 (Lung), HUVEC (Normal Endothelial) | Induced apoptosis & cell cycle arrest in LoVo cells; upregulation of BAX and P53 [2]. | Reduced migration; suppression of MMP2, MMP9, IL-8 genes [2]. | MTT assay; Annexin V/PI apoptosis detection; gene expression analysis [2]. |
| Kaempferol [3] | Cyperus rotundus | Chondrocytes (Inflammatory model for Osteoarthritis) | Weakened IL-1β effects on viability, apoptosis, and inflammation [3]. | Multiple targets predicted (AKT1, IL1B, STAT3); good binding affinity in silico [3]. | Network pharmacology; molecular docking; in vitro validation [3]. |
| Curcumin, Resveratrol, etc. [4] | Various (e.g., Turmeric, Grapes) | Rhabdomyosarcoma, Sarcoma (Muscle-derived cancers) | Inhibited NF-κB signaling pathway [4]. | Inhibition of IKK complex activation and NF-κB translocation [4]. | Primarily review-based; mechanisms summarized from existing literature [4]. |
Common Experimental Workflows
The studies referenced employed standard, rigorous methodologies for evaluating compound efficacy. The diagram below outlines the typical workflow for the in vitro experiments mentioned in the table [2] [1] [3].
References
- 1. Anticancer and antiproliferative efficacy of a standardized ... [pmc.ncbi.nlm.nih.gov]
- 2. Phytochemical analysis and anticancer activity of the ... [degruyterbrill.com]
- 3. The Mechanism by Which Cyperus rotundus Ameliorates ... [pmc.ncbi.nlm.nih.gov]
- 4. Alternations of NF-κB Signaling by Natural Compounds in ... [mdpi.com]
Chemical and Pharmacological Profile of Leucocianidol
Leucocianidol (also known as Leucocyanidin or Leucocyanidol) is a flavan-3-ol type of flavonoid, belonging to the class of leucoanthocyanidins [1]. The table below summarizes its fundamental characteristics:
| Property | Description |
|---|---|
| IUPAC Name | (2R,3S,4S)-2-(3,4-Dihydroxyphenyl)-3,4-dihydro-2H-1-benzopyran-3,4,5,7-tetrol [1] |
| Chemical Formula | C15H14O7 [2] [1] [3] |
| Molecular Weight | 306.27 g/mol [1] [4] [3] |
| CAS Registry Number | 480-17-1 [4] [3] |
| Synonyms | Leucocyanidol, Leucocyanidin, Resivit, Vitamin P faktor [1] [3] |
Comparison with Selected Bioactive Flavonoids
The following table compares this compound with other phytochemicals studied in similar network pharmacology contexts, highlighting their potential therapeutic roles. Please note that this is not a direct structural analog comparison but an overview of compounds with similar bioactivity.
| Compound | Molecular Formula | Molecular Weight (g/mol) | Oral Bioavailability (OB) | Drug Likeness (DL) | Reported Bioactivities (from Network Pharmacology) |
|---|---|---|---|---|---|
| This compound | C15H14O7 [5] | 306.29 [5] | 30.84% [5] | 0.27 [5] | Potential for SLE management [6]; Identified for HCC treatment [5] |
| (+)-Catechin Gallate | C22H18O10 [5] | 442.4 [5] | 53.57% [5] | 0.75 [5] | Highest degree of target interactions in HCC study; strong binding to MAPK3, SRC, STAT3 [5] |
| β-Sitosterol | C29H50O [5] | 414.79 [5] | 36.91% [5] | 0.75 [5] | Multiple target interactions; induced reduction of cell viability in HepG2 cells [5] |
| Cianidanol | C15H14O6 [5] | 290.29 [5] | 54.83% [5] | 0.24 [5] | Listed in analysis but showed minimal target interactions in the HCC study [5] |
Experimental Insights and Methodologies
Recent studies have utilized advanced computational methods to explore the therapeutic potential of this compound. Here is a summary of the key experimental protocols and findings:
Network Pharmacology & Molecular Docking for SLE
A 2024 study investigated Nelumbo nucifera (lotus) for Systemic Lupus Erythematosus (SLE) management [6].
- Experimental Protocol:
- Target Prediction: Active compounds and their protein targets were identified from IMPPAT and KNApSAcK databases. SLE-related targets were retrieved from GeneCards and OMIM.
- Network Construction: A Protein-Protein Interaction (PPI) network was built using Cytoscape software to identify core targets.
- Pathway Analysis: Gene Ontology (GO) and KEGG pathway enrichment analyses were performed using ShinyGo.
- Molecular Docking & Dynamics: The binding affinity of compounds to core targets was evaluated. A molecular dynamics simulation was run to assess the stability of the this compound-ESR1 protein complex.
- Key Findings: The study identified this compound as a key active compound in lotus. Molecular docking showed this compound had favourable binding affinities (less than -4.5 kcal/mol) for all 10 core targets identified in SLE, suggesting a strong potential for multi-target activity [6].
Network Pharmacology for Hepatocellular Carcinoma (HCC)
A 2023 study evaluated several Bergenia species for treating HCC [5].
- Experimental Protocol:
- Compound Screening: 147 phytochemicals were screened based on pharmacokinetic properties (OB > 30% and DL > 0.18), narrowing the list to four, including this compound.
- Target Identification & PPI: Targets for the compounds and HCC disease were gathered from multiple databases. Overlapping targets were used to build a PPI network.
- Topological Analysis: The network was analyzed to find hub genes; STAT3, MAPK3, and SRC were selected for molecular docking.
- Key Findings: this compound was one of the top three compounds with a high degree of target interactions (degree = 41) within the network, indicating its potential multi-target role in HCC. However, (+)-Catechin gallate showed the highest number of interactions and the best binding scores in molecular docking [5].
The experimental workflow from these studies can be visualized as follows:
Conclusion for Researchers
Based on the gathered data, here is a comparative summary:
- This compound demonstrates significant promise as a multi-target therapeutic agent, particularly in autoimmune (SLE) and liver diseases (HCC), supported by strong computational binding affinities [6] [5].
- (+)-Catechin Gallate appears to have superior drug-like properties and a broader target interaction profile compared to this compound in the context of HCC, making it a compelling candidate for further investigation [5].
- Key Research Gaps: A direct, head-to-head comparative analysis of this compound with its closest structural analogs (e.g., other leucoanthocyanidins or flavan-3-ols) using standardized experimental protocols is lacking in the current literature. Future work should focus on this, supplemented with in vitro and in vivo validation.
References
- 1. Leucocyanidin [en.wikipedia.org]
- 2. This compound | C15H14O7 | CID 445881 - PubChem - NIH [pubchem.ncbi.nlm.nih.gov]
- 3. | C15H14O7 this compound [chemspider.com]
- 4. Cas 480-17-1,LEUCOCYANIDIN POLYMER [lookchem.com]
- 5. Underlying Mechanisms of Bergenia spp. to Treat ... [pmc.ncbi.nlm.nih.gov]
- 6. Therapeutic potential of Nelumbo nucifera Linn. in systemic ... [pubmed.ncbi.nlm.nih.gov]
Leucocianidol reactivity comparison with anthocyanidins and flavonols
Structural and Chemical Reactivity Comparison
The core differences in reactivity between leucocyanidin, anthocyanidins, and flavonols can be summarized in the table below.
| Property | Leucocyanidin & Leucoanthocyanidins | Anthocyanidins (e.g., Cyanidin, Delphinidin) | Flavonols (e.g., Quercetin, Kaempferol) |
|---|---|---|---|
| Basic Structure | Flavan-3,4-diols [1] [2] | Flavylium cation (2-phenylbenzopyrylium) [3] [4] | 3-hydroxyflavone (with C4-oxo and C2–C3 double bond) [5] [6] |
| Key Functional Groups | Hydroxyl groups at positions C3 and C4 on ring C [5] | Positively charged oxygen in ring C; hydroxylation patterns vary on rings A and B [3] | Ketone group (C4=O); hydroxyl group at C3; C2–C3 double bond [5] [4] |
| Aromaticity of Ring C | Less aromatic [5] | More aromatic [5] | Less aromatic [5] |
| Reactivity in Electrophilic Reactions | Moderate. Leucocyanidin is one of the most reactive among the leucoanthocyanidins. The most susceptible sites for attack are on Ring A [5]. | Highly reactive. Global descriptors indicate they are the most reactive class in nucleophilic reactions. Delphinidin has the smallest HOMO-LUMO gap, indicating high reactivity [5]. | Highly reactive. Quercetin is one of the most reactive flavonoids in electrophilic reactions. Reactivity is high across the structure [5]. |
| Reactivity in Nucleophilic Reactions | Information not specified in search results. | Highly reactive [5]. | Information not specified in search results. |
| Key Antioxidant Features | Acts as a biosynthetic intermediate; its conversion can produce antioxidant compounds [1]. | Reactivity relies on hydroxylation pattern (e.g., catechol or pyrogallol on Ring B) [3] [4]. Pelargonidin (lacking ortho-dihydroxyl) is least active [4]. | Exhibits strong antioxidant capacity due to the 2,3-double bond in conjugation with a 4-carbonyl group and the catechol group on Ring B (Bors criteria) [4]. |
Experimental Methodologies for Reactivity Analysis
The comparative data above is largely derived from advanced computational chemistry studies, which employ the following rigorous protocol:
- Computational Method: Density Functional Theory (DFT) is the standard for evaluating molecular properties and reactivity [5] [7] [8].
- Functional and Basis Set: The CAM-B3LYP functional combined with the def2TZV basis set is typically used for geometry optimization and electronic property calculations. This setup often includes Grimme's D3 dispersion correction for weak interactions and an implicit solvation model (e.g., IEFPCM for water) to simulate a biological environment [5].
- Key Analyses Performed:
- Global Reactivity Descriptors: Calculated from frontier molecular orbitals (HOMO and LUMO) to predict global electrophilic and nucleophilic tendencies [5].
- Fukui Functions: Analyze local electron density changes to identify atomic sites most susceptible to nucleophilic or electrophilic attack [5] [7].
- Molecular Electrostatic Potential (MEP) Surface: Visualizes regions of high and low electron density on the van der Waals surface, indicating potential sites for electrophilic (red) and nucleophilic (blue) interactions [5].
- Topological Analysis (AIM): Identifies Bond Critical Points (BCPs) to understand the strength and nature of intramolecular interactions, such as hydrogen bonds [5].
The experimental workflow for the quantum chemical analysis of flavonoid reactivity is summarized in the diagram below.
Key Reactivity Insights and Biological Implications
The structural differences lead to specific and consequential reactivity behaviors:
- Leucocyanidin's Focused Reactivity: The finding that Ring A of leucoanthocyanidins is the most susceptible site for electrophilic attack provides a precise chemical rationale for its role as a biosynthetic precursor. Its reactivity is more localized compared to the broader reactivity of anthocyanidins and flavonols [5].
- Anthocyanidin's Charge-Driven Reactivity: The flavylium cation structure makes anthocyanidins particularly potent in nucleophilic reactions. This, combined with a more aromatic C-ring, defines their unique chemical profile compared to their leuco- precursors and flavonols [5].
- The Flavonol Advantage: Flavonols like quercetin meet the classic Bors criteria for optimal antioxidant activity: a catechol group in Ring B, the C2–C3 double bond, and a 4-carbonyl group. This allows their aroxyl radicals to be highly stabilized through resonance and hydrogen bonding, making them exceptionally strong antioxidants and reactive in electrophilic processes [5] [4].
Conclusion for Research and Development
For researchers in drug development, these reactivity profiles suggest different strategic applications:
- Leucoanthocyanidins are key targets for biosynthetic studies or as specialized intermediates whose localized reactivity on Ring A can be exploited.
- Anthocyanidins, with their global nucleophilic reactivity and pH-dependent color changes, are prime candidates for development as natural colorants and for investigating activities related to electron donation.
- Flavonols like quercetin, with their robust and well-understood radical-stabilizing structure, remain the most reliable choice for applications demanding potent antioxidant and electrophilic activity, such as in nutraceuticals or anti-inflammatory agents.
References
- 1. Leucoanthocyanidin - an overview | ScienceDirect Topics [sciencedirect.com]
- 2. Leucoanthocyanidin [en.wikipedia.org]
- 3. Anthocyanins: A Comprehensive Review of Their Chemical ... [pmc.ncbi.nlm.nih.gov]
- 4. Antioxidant Activity of Anthocyanins and Anthocyanidins: A Critical Review - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Comparative analysis of the reactivity of anthocyanidins, leucoanthocyanidins, and flavonols using a quantum chemistry approach - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Chemistry and Biological Activities of Flavonoids [pmc.ncbi.nlm.nih.gov]
- 7. Comparative analysis of the reactivity of anthocyanidins, leucoanthocyanidins, and flavonols using a quantum chemistry approach | Journal of Molecular Modeling [link.springer.com]
- 8. Comparative analysis of the reactivity of anthocyanidins ... [pubmed.ncbi.nlm.nih.gov]
XLogP3
Hydrogen Bond Acceptor Count
Hydrogen Bond Donor Count
Exact Mass
Monoisotopic Mass
Heavy Atom Count
Wikipedia
Use Classification
Dates
Explore Compound Types