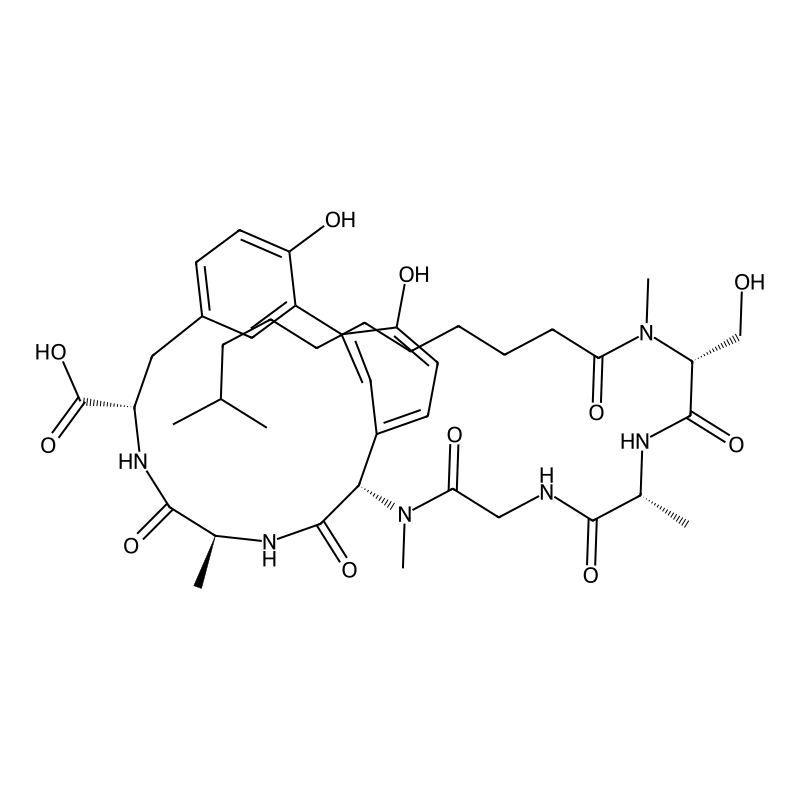
Arylomycin A2
Content Navigation
Product Name
IUPAC Name
Molecular Formula
Molecular Weight
InChI
InChI Key
Synonyms
Canonical SMILES
Isomeric SMILES
Arylomycin A2 is a naturally derived, macrocyclic lipopeptide antibiotic that functions as a highly specific, non-covalent inhibitor of bacterial type I signal peptidase (SPase I). Structurally, it features a biaryl-linked, N-methylated tripeptide macrocycle conjugated to a lipopeptide tail, lacking the nitrotyrosine or glycosylation modifications found in related class analogs [1]. By binding directly to the conserved Ser-Lys catalytic dyad of SPase I, Arylomycin A2 blocks the cleavage of N-terminal signal peptides, leading to the lethal accumulation of pre-proteins in the bacterial membrane[2]. In procurement and chemical biology, it serves as the definitive reference standard and baseline structural scaffold for investigating bacterial secretion pathways and developing next-generation, broad-spectrum SPase I inhibitors [3].
Research Fit
References
- [1] Liu, N., et al. (2011). Synthesis and Characterization of the Arylomycin Lipoglycopeptide Antibiotics and the Crystallographic Analysis of Their Complex with Signal Peptidase. Journal of the American Chemical Society, 133(44), 17869-17877.
- [2] Luo, C., et al. (2009). Crystallographic Analysis of Bacterial Signal Peptidase in Ternary Complex with Arylomycin A2 and a β-Sultam Inhibitor. Biochemistry, 48(38), 8976–8984.
- [3] Roberts, T. C., et al. (2007). Structural and Initial Biological Analysis of Synthetic Arylomycin A2. Journal of the American Chemical Society, 129(51), 15830–15838.
Substituting Arylomycin A2 with other class members, such as Arylomycin B2 or the C-series lipoglycopeptides, fundamentally alters the molecule's physicochemical properties and target interaction profile. Arylomycin B2 contains a nitrated tyrosine residue (Tyr7) on the biaryl core, which introduces distinct electronic effects and shifts the antimicrobial spectrum, complicating baseline structure-activity relationship (SAR) studies . Similarly, C-series lipoglycopeptides feature deoxy-α-L-mannose glycosylation, which alters solubility, membrane partitioning, and free inhibitor concentration [1]. For researchers requiring an unmodified, un-nitrated, and un-glycosylated core to serve as a clean synthetic starting point or a precise crystallographic baseline for SPase I binding, Arylomycin A2 is the strictly required molecular form [2].
Substitution Risk
References
- [2] Liu, N., et al. (2011). Synthesis and Characterization of the Arylomycin Lipoglycopeptide Antibiotics and the Crystallographic Analysis of Their Complex with Signal Peptidase. Journal of the American Chemical Society, 133(44), 17869-17877.
- [3] Roberts, T. C., et al. (2007). Structural and Initial Biological Analysis of Synthetic Arylomycin A2. Journal of the American Chemical Society, 129(51), 15830–15838.
Superior SPase I Target Affinity Compared to Standard Serine Protease Inhibitors
Arylomycin A2 demonstrates exceptional potency against bacterial type I signal peptidase compared to conventional beta-sultam inhibitors. In biochemical assays against the soluble catalytic domain of E. coli SPase I (Δ2−75), Arylomycin A2 achieved an IC50 of 1 ± 0.2 μM, whereas the morpholino-β-sultam inhibitor BAL0019193 required an IC50 of 610 ± 18 μM to achieve dose-dependent inhibition [1].
| Evidence Dimension | SPase I (Δ2−75) Inhibitory Potency (IC50) |
| Target Compound Data | 1 ± 0.2 μM |
| Comparator Or Baseline | Morpholino-β-sultam (BAL0019193): 610 ± 18 μM |
| Quantified Difference | Over 600-fold higher binding affinity |
| Conditions | In vitro dose-dependent inhibition assay using E. coli SPase I Δ2−75 |
Ensures reliable, high-affinity target engagement for researchers establishing baseline SPase I inhibition assays or conducting structural biology studies.
High-Resolution Co-Crystallization Suitability for Structural Biology
Arylomycin A2 is highly effective at stabilizing the SPase I binding cleft for structural elucidation. X-ray crystallographic studies of E. coli SPase I in complex with Arylomycin A2 and a β-sultam inhibitor successfully resolved the ternary complex at a 2.0 Å resolution, an improvement over the 2.5 Å resolution achieved in earlier cocrystal structures of the binary complex [1]. The compound binds in an extended β-sheet conformation, forming a critical salt bridge with the catalytic residues and allowing clear electron density observation of the macrocycle and lipid tail [2].
| Evidence Dimension | Crystallographic Resolution |
| Target Compound Data | 2.0 Å (in ternary complex) to 2.5 Å (binary complex) |
| Comparator Or Baseline | Apo-SPase I or lower-affinity ligands (often fail to stabilize the active site cleft) |
| Quantified Difference | Enables high-resolution (≤2.5 Å) structural mapping of the active site |
| Conditions | X-ray crystallography of E. coli SPase I Δ2−75 |
Provides structural biologists with a validated, high-stability ligand essential for mapping the SPase I active site and designing next-generation inhibitors.
Permeability-Dependent Antibacterial Readout for Membrane Disruptors
Arylomycin A2 exhibits a highly specific permeability-dependent activity profile against Gram-negative pathogens. While it shows no growth inhibition against wild-type, non-permeabilized E. coli (MIC > 128 μM), it effectively inhibits the growth of E. coli permeabilized with polymyxin B nonapeptide, yielding an MIC of 128 μM[1]. This stark contrast confirms that its primary limitation in Gram-negative bacteria is outer membrane penetration rather than target affinity[2].
| Evidence Dimension | Antibacterial Activity (MIC) |
| Target Compound Data | 128 μM (permeabilized E. coli) |
| Comparator Or Baseline | Wild-type E. coli: >128 μM (No inhibition) |
| Quantified Difference | Absolute shift from inactive to active upon membrane permeabilization |
| Conditions | Broth microdilution against E. coli MG1655 with and without polymyxin B nonapeptide |
Makes Arylomycin A2 an ideal positive control and readout tool for assays evaluating outer membrane permeabilizers or novel drug delivery vectors.
Unmodified Core Scaffold for SAR and Derivative Synthesis
Unlike the Arylomycin B series, which contains a nitro group (-NO2) on the Tyr7 residue, Arylomycin A2 possesses an unmodified biaryl macrocycle. This structural distinction is critical for synthetic chemistry; the absence of the electron-withdrawing nitro group alters the reactivity and physical properties of the core, making Arylomycin A2 the preferred baseline scaffold for synthesizing novel lipid tail derivatives (such as C16 variants) without the confounding steric or electronic variables introduced by nitration [1].
| Evidence Dimension | Core Macrocycle Modification |
| Target Compound Data | Unmodified Tyr7 residue |
| Comparator Or Baseline | Arylomycin B2: Nitrated Tyr7 residue (-NO2) |
| Quantified Difference | Eliminates electronic and steric interference from the nitro group during derivatization |
| Conditions | Total synthesis and structure-activity relationship (SAR) profiling |
Provides medicinal chemists with the cleanest baseline scaffold for developing optimized SPase I inhibitors with modified lipid tails.
Structural Biology and Crystallography of Bacterial Secretion Systems
Due to its ability to form stable, high-resolution (2.0–2.5 Å) complexes with the SPase I catalytic domain, Arylomycin A2 is heavily procured by structural biology laboratories. It serves as an essential co-crystallization ligand to stabilize the active site cleft in an extended β-sheet conformation, enabling the precise mapping of the Ser-Lys catalytic dyad and facilitating structure-based drug design[1].
Baseline Scaffold for Novel Antibiotic Synthesis
Because it lacks the nitrotyrosine modification of the B-series and the glycosylation of the C-series, Arylomycin A2 provides an unmodified core macrocycle. Medicinal chemistry groups procure this compound as a clean starting material or reference baseline to synthesize derivatives with optimized lipopeptide tails (e.g., C16 variants), aiming to overcome natural resistance mutations or improve membrane penetration without confounding electronic effects [2].
Positive Control in Outer Membrane Permeability Assays
Arylomycin A2 possesses high target affinity but poor intrinsic outer membrane penetration in Gram-negative bacteria. Consequently, it is an ideal functional readout molecule for assays screening outer membrane permeabilizers (such as polymyxin derivatives). A shift in Arylomycin A2's MIC provides direct, quantitative confirmation of successful membrane disruption [3].
Reference Standard for SPase I Inhibitor Screening
With a highly quantified IC50 of 1 μM against E. coli SPase I, Arylomycin A2 is the gold-standard positive control for biochemical assays targeting type I signal peptidases. Assay developers use it to validate high-throughput screening (HTS) platforms and benchmark the potency of novel, non-covalent SPase I inhibitor candidates [1].
Application Fit Matrix
References
- [1] Luo, C., et al. (2009). Crystallographic Analysis of Bacterial Signal Peptidase in Ternary Complex with Arylomycin A2 and a β-Sultam Inhibitor. Biochemistry, 48(38), 8976–8984.
- [2] Liu, N., et al. (2011). Synthesis and Characterization of the Arylomycin Lipoglycopeptide Antibiotics and the Crystallographic Analysis of Their Complex with Signal Peptidase. Journal of the American Chemical Society, 133(44), 17869-17877.
- [3] Roberts, T. C., et al. (2007). Structural and Initial Biological Analysis of Synthetic Arylomycin A2. Journal of the American Chemical Society, 129(51), 15830–15838.
XLogP3
Hydrogen Bond Acceptor Count
Hydrogen Bond Donor Count
Exact Mass
Monoisotopic Mass
Heavy Atom Count
Wikipedia
Explore Compound Types